Mar 22, 2024
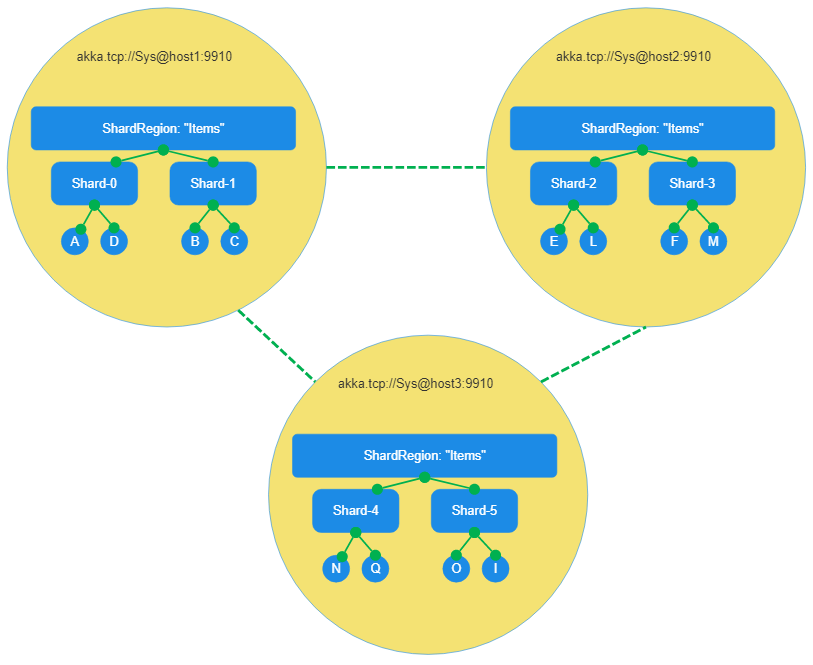
Distributing State Reliably with Akka.Cluster.Sharding
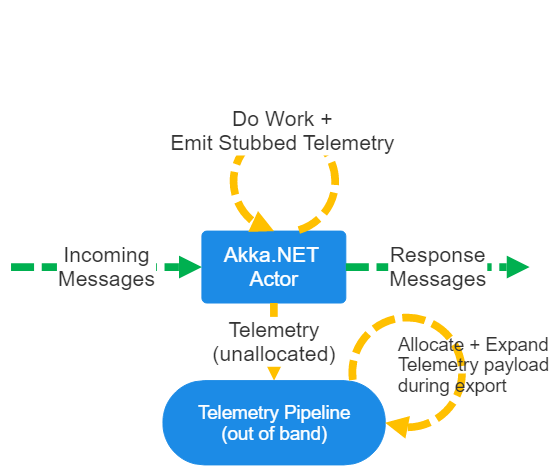
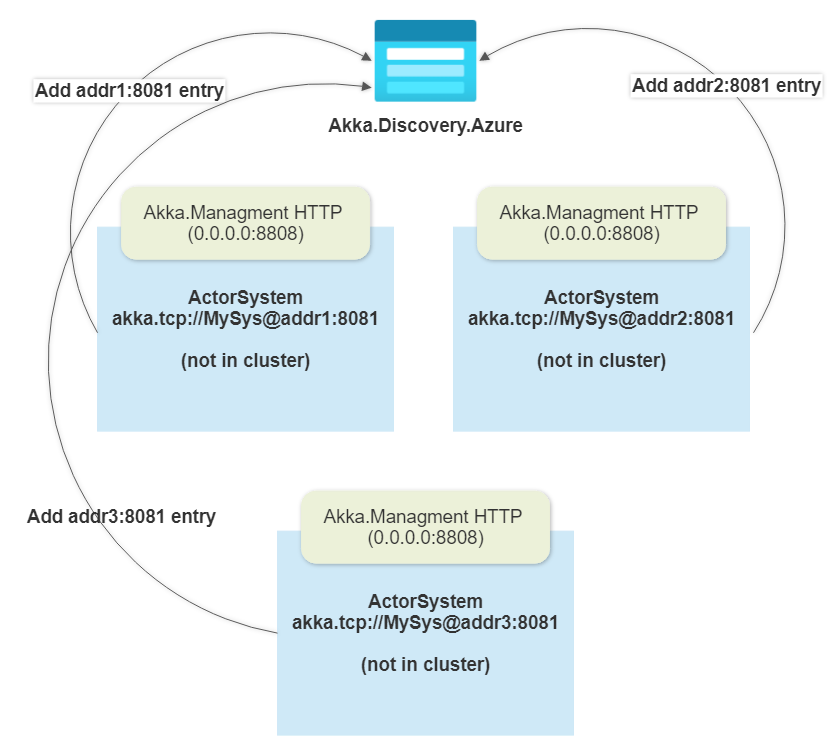
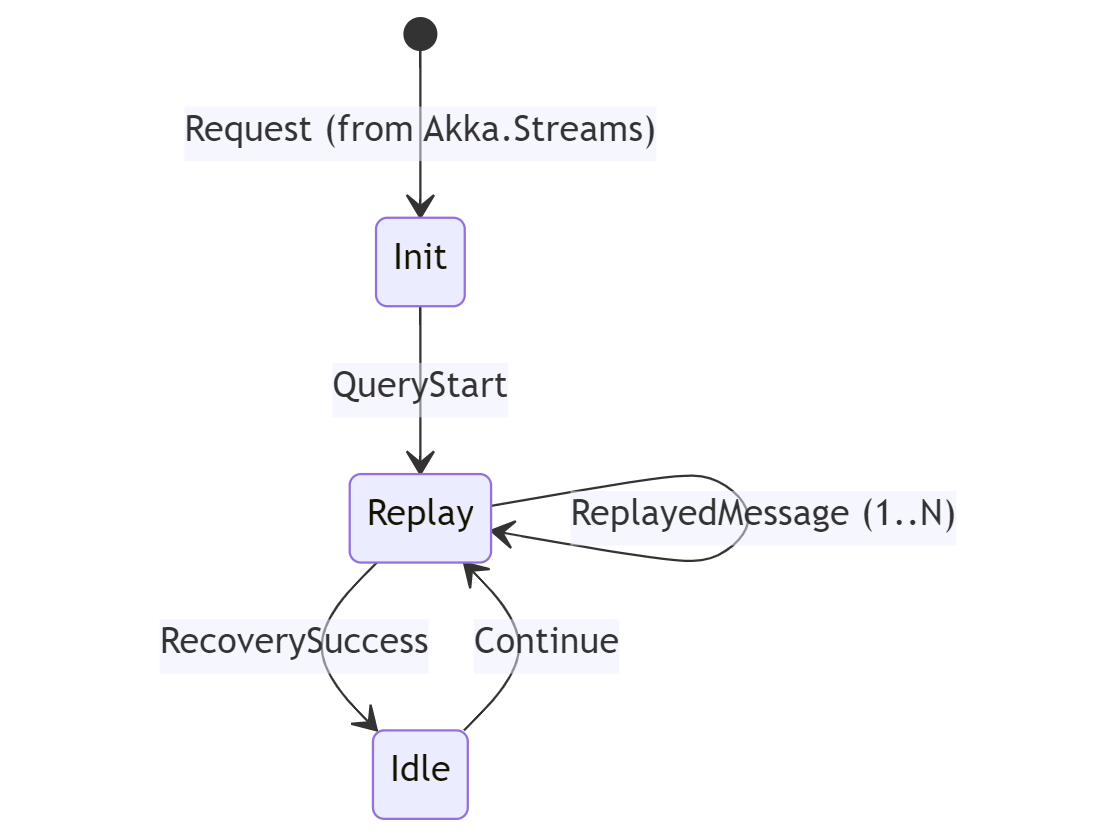
We’ve had a number of posts on Akka.Cluster.Sharding on this blog: “Introduction to Akka.Cluster.Sharding in Akka.NET” “Technical Overview of Akka.Cluster.Sharding in Akka.NET” Both of those were written by Bartosz Sypytkowski, who originally contributed those features to Akka.NET. We’ve had a...