// BLOG
Introduction to Akka.Streams
Building High-Level Streaming Worklows in Akka.NET
The goal of this blog post is to give you a glimpse of the idea and basics behind Akka.Streams. What they are and why you may find them useful addition in your day to day job.
In short: Akka.Streams is a library build on top of Akka.NET, which allows you to consume and process potentially infinite streams of data in type-safe and resource-safe way.
To make it easier to visualize, let’s take an example: we have a queue (i.e. RabbitMQ), that sends us a documents, which we have to parse, turn into structured data and save in the database.
var settings = NamedQueueSourceSettings.Create(new DefaultAmqpConnection(), "queue-name");
var rabbitMqSource = AmqpSource.AtMostOnceSource(settings, 16);
IRunnableGraph<NotUsed> graph =
rabbitMqSource
.Select(message => ParseDocument<DataItem>(message.Bytes))
.SelectAsync(parallelism: 1, item => dbContext.InsertAsync(item))
.To(Sink.ForEach<DataItem>(item => Console.WriteLine($"Inserted: {item}")));
One of the great advantages of using Akka.Streams is its declarative syntax. Imagine that we detected that our stream is slow because each time we’re persisting documents one by one - which can be bottleneck when we take into account overhead of disk and network I/O. One of the common solutions to speed that up is to apply batching. Fortunately we have a plenty of operations (in Akka.NET they’re called stages), that let us apply different grouping patterns. Example:
IRunnableGraph<NotUsed> graph =
rabbitMqSource
.Select(message => ParseDocument<DataItem>(message.Bytes))
.GroupedWithin(400, 100.Milliseconds())
.SelectAsync(parallelism: 1, items => dbContext.InsertManyAsync(items))
.To(Sink.ForEach<DataItem>(items => Console.WriteLine($"Inserted: {items}")));
The code looks very similar, the major difference is that now we use InsertManyAsync method to insert multiple items at once, and that we added a standard GroupedWithin stage - which will simply emit a batch of items once it will collect 400 elements or a 100ms will pass, whatever will happen first. That’s all!
Akka.Streams and Reactive Extensions
Initially, this may resemble Reactive Extensions to you. And yes, Akka.Streams borrows from the experiences of Rx.NET and adapts it into the more complicated world of graphs-based workflows and optimizes it for server-side systems.
One of the design decisions of Rx.NET is that it’s inherently a push-based streaming model. The pace of processing is dictated by upstream (a producer of event). While this usually isn’t a problem in client-side apps - as most of the events there are produced in result of a single user’s actions - it becomes problematic on the server-side as your downstream is not able to “hold back” (backpressure) upstream from sending more data, which may eventually result in your application toppling down and becoming unavailable once it runs out of resources. Akka.Streams is build from scratch to allow producers and consumers to negotiate streaming rate dynamically.
If you need, you still can interop between Rx.NET and Akka.NET Streams - you can read more details in docs.
Akka.Streams Business Cases
Akka.Streams are implemented on top of Akka.NET actors through a process we’ll describe in a moment called “materialization” - but aside from the fact that Akka.Streams graphs are implemented using actors at first glace there doesn’t appear to be much of a relationship between these LINQ-like flows and actors.
Akka.Streams should be thought of as a higher-level way of writing Akka.NET programs; you can express your application concisely by composing small, modular “graph stages” (i.e. a sources, flows, and sinks) together into an asynchronous streaming application. It’s highly productive and efficient, especially when you consider that Akka.NET streams have many pre-built connectors to technologies like Kafka, Azure Queues, RabbitMQ, and so on. The amount of code you have to write and debug is significantly lower for many routine streaming problems using Akka.Streams.
Beyond that though, Akka.Streams are also especially effective and making producer-consumer type systems more resilient through the use of backpressure. We’ll save the details for a subsequent blog post, but the short version is this: when producers create events at a significantly higher rate than they can be consumed by downstream clients or services your application will eventually run out of resources and crash. Akka.Streams helps prevent this issue by enabling the consumers to “backpressure” the producers through what’s known as the “pull model” - if a consumer isn’t ready to receive more events from an upstream producer, the producer won’t receive any more “pull” requests from that client and will either stop producing new events or perhaps buffer / compress existing ones.
Once the consumer has caught up on its work, it will begin pulling messages from the producer once again. This back-and-forth allows producers and consumers to load-balance, process messages as quickly as the system can allow, and prevents any unavailable as a result of excessive resource utilization.
Materializers
While we have created a fully closed shape, at this point nothing will happen. This is simply because so far we have only described the shape of our stream: we told what stages do we use, and how they will be connected to each other.
In order to run our stream, we need a materializer: component, that will take a look at the blueprint of our stream and decide how to evaluate it.
using (var materializer = actorSystem.Materializer())
{
var effect = graph.Run(materializer);
await effect;
}
There are few advantages of such approach. One is that we could potentially build different kinds of materializers that will allow us change the tradeoffs of our execution model without changing actual business logic. Another - and potentially the biggest one - is that once we know exactly, what is going to be evaluated ahead of time, we’re able to perform certain optimizations prior the graph execution.
One of the most famous optimizations done in Akka.Streams is so-called fusing. In its essence, it allows you to take multiple sequentially connected synchronous stages (like
Select,Whereetc.) and fuse them together, greatly reducing an underlying infrastructure overhead of having workflows build from dozens of stages.
Materializers fit into old design pattern known to functional programmers as Free Monad, and for object oriented ones as Interpreter. If you’re a .NET developer and this sounds scary to you, don’t worry. You probably already heard of IQueryable<> , which uses exactly the same approach. We’ll be referring to it quite often in this post.
Beside naming, the major differences are:
- Queryables are evaluated implicitly, during specific API calls like
ToList,AsEnumerableorFirstOrDefault. However, as history has proven, this solution was not free of problems (eg. accidentally loading the whole database table into memory first and paging it later). This required extra discipline from developer to keep the solution efficient. IQueryable<>usually carries its interpreter - known asQueryProvider- as part of it’s state. This could cause potential issues, as those are often disposable resources with limited lifecycle, and many developers often forgot about it. Example could be callingToListon LINQ-to-Entities query after disposing a database context.
For these reasons, to avoid confusion and potential risks, Akka.Streams has decided to go different way: graph evaluation is explicit and easier to track, because graph materializers are passed as parameters. Usually, when you’ll see a method which requires a materializer as a parameter, you may expect, that it will perform graph evaluation.
Materialized values
One of the things defining Free Monad / Interpreter pattern is an effect: the result of your computation. If you’re used to LINQ, you’re specifying your effect as result type of methods such as .ToArray, .ToListAsync or FirstOrDefault. While this may feel to be enough, when working with collections or queries, it turns into a very limiting constraint when working with graphs.
The reason is simple: general purpose graphs are not only about returning a collection of data. Sometimes the result of the materialization process may be not a collection but a queue, that will serve as a connectivity endpoint, or an awaitable, which will trigger once graph is completed/failed.
For this reason, materialized values where introduced. What they allow you to do, is to describe an effect of every particular stage in the type safe manner. If you’ll take a look at following definition:
Source<string, ISourceQueueWithComplete<string>> queueSource =
Source.Queue<string>(100, OverflowStrategy.DropHead);
you’ll see that Source<,> has two generic types. First one is the type of produced events, while second - the type of materialized value. Most of the stages are effect-free and NotUsed type is used in such cases to describe the materialized value.
On other occasions, you may need a materialized values of several stages at once or just pick one of them. This can be done easily with Keep combinators:
var (queue, result) = queueSource
.ToMaterialized(Sink.Aggregate<string, string>("", String.Concat), Keep.Both)
.Run(materializer);
Akka.Streams graphs
You may have noticed, that we’re talking about Akka.Streams in terms of streams and graphs interchangeably. So far we only talked about using LINQ syntax to build a simple linear workflows. However one of the unique attributes of Akka.Streams is ability to build a whole graphs, including cycling ones! Every linear stream is in fact a simple version of a graph.
Inlets and Outlets
Before we continue, we first need to mention basic building components of graphs. You’ve already heard about stages. We also mentioned that each stage has its shape. In Akka.Stream every shape is defined by a number of input (inlets) and output (outlets) ports. By combining inlets and outlets you can connect several smaller stages together into a bigger one.
There are several rules related to how inlets and outlets work:
- Every shape has a statically defined number of inlets and outlets. This is a difference when compared to eg. Rx.NET. In case when you need to add and remove publishers/subscribers dynamically at runtime, you can define a dedicated extension points in form of
MergeHub,BroadcastHubandPartitionHubstages. You can read more about them here. - Before you materialize a graph, you need to connect together all inlets and outlets. There can be no dangling ports around. Reason for that is simple: in order to evaluate your graph, materializers must have full knowledge of it. Imagine compiling a program where you are using variable not introduced before or not returning result from a method when required. You can use
Sink.Ignore<T>()andSource.Empty<T>()to close unnecessary ports.
A stage with shape, that has only only outlets, but no inlets is called source:

Reverse situation is called sink:
You’ve met them before. The shape with both inlets and outlets is known as flow:

A shape that has no inlets or outlets exposed is called a closed shape.
Using the Graph DSL
In order to build complex workflows Akka.Streams exposes a dedicated DSL (Domain Specific Language), that can be used to plumb various stages together.
Before we start doing so, let’s try to visualize our graph using a diagram - it’s a great way to design your system before focusing on coding:
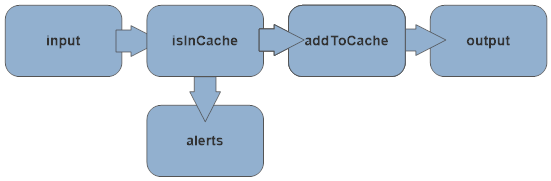
In this example we’ll build a graph which for a given stream of elements will try to cache them and ignore cached duplicates. We could represent it as follows:
var graph = RunnableGraph.FromGraph(GraphDsl.Create(b =>
{
// define stages, we're going to use
var input = b.Add(Source.From(new[] { "apple", "banana", "apple", "mango" }));
var output = b.Add(Sink.ForEach<string>(Console.WriteLine));
var alerts = b.Add(Sink.ForEach<string>(x => Console.WriteLine($"Alert: {x}")));
var isInCache = b.Add(new Partition<string>(2, x => !cache.Contains(x) ? 0 : 1));
var addToCache = b.Add(Flow.Identity<string>()
.Select(x =>
{
cache.Add(x);
return x;
}));
// connect stages together
b.From(input).To(isInCache);
b.From(isInCache.Out(0)).Via(addToCache).To(output); // happy path
b.From(isInCache.Out(1)).To(alerts); // duplicates
// return closed shape to signal that graph is completed
return ClosedShape.Instance;
}));
Since this is a simplified example, you might ask yourself: what’s the advantage of using this? Here, we only use standard output and simple functions, however in real-life scenario this might have been a database, queue or alerting system with complex processing logic.
We could reimagine structure of this graph into following example: We created system which gathers user’s requests and checks them for fraud detection. Positive checks are send to a separate alerting system, while others are batched and send to further processing.
As the time progresses, you may need to add more control flow to it, i.e. introduce batching or throttling - things, that are trivial using Akka.Streams.
The great advantage here is that you can isolate your domain logic in form of small, composable building blocks, in total separation from the code describing how they are connected.
What’s Next?
This is only a glimpse of what you can achieve with Akka.Streams. They can be used in variety of use cases:
- Many of Akka.Persistence journals allow you to query their event stores using Akka.Streams API.
- You can use streams to build a network servers over TCP using easy, declarative API. We’ll talk about it in separate post.
- You can connect to existing 3rd party systems using plugins from Alpakka repository.
- Take a look at the Akka.Streams graph code inside Petabridge’s Cluster.WebCrawler example. Can you explain what each of the graph stages are doing?
If you’re interested and want to explore Akka.Streams further, please take a look at the official documentation - it’s full of examples, use cases and answers for most frequently asked questions.
Appendix: Akka.Streams vs. TPL Dataflow
One of the common questions when Akka.Streams is being introduced to .NET developers is: we have TPL Dataflow already, so why not just use it?. As you could have noticed, their use cases are very similar. However, there are few big conceptual differences:
- TPL Dataflow presents an imperative style of programming. Conceptually dataflow control blocks are much more closer to modeling the workflows using standard Akka actors. On the other side Akka.Stream allows you to write your logic in much more fine-grained, declarative fashion (think of for loops vs. LINQ). All of that without compromising the performance of your system.
- Since Akka.Streams allows you to think about events just like if they were streams, some operations are much easier than using dataflow blocks. Examples of such could be sliding window which is much harder to implement using imperative-style programming.
- Akka.Streams come with over a 100 of different stages and connectors, which allow you to focus on your business logic in clean separation from infrastructure code. This higher level of abstraction is also one of the advantages of the declarative programming model.
With Akka.Streams you can also take advantage of existing akka programming model, integrating it with actors. Starting from v1.4 you’ll be able to propagate streams across node boundaries thanks to StreamRefs, just like you do with IActorRefs right now!
About the Author
Bartosz Sypytkowski is one of the Akka.NET core team members and contributor since 2014. He’s one of the developers behind persistence, streams, cluster tools and sharding plugins, and a maintainer of Akka F# plugin. He’s a great fan of distributed functional programming. You can read more about his work on his blog: http://bartoszsypytkowski.com
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.
Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS