// BLOG
Real World Akka.NET Clustering: Process Managers and Long-Running Operations
Using Process Managers with Akka.Persistence and Akka.Cluster.Sharding to Manage Complex, Long-Running Workflows
In our previous installment of “Real World Akka.NET Clustering”, we covered state machines - the tried and true tool for modeling event-driven behavior for business entities inside your domain. And we also demonstrated that using Akka.NET programming techniques such as behavior-switching it’s straightforward to implement them with actors.
In this post we’re going to take our discussion of real-world Akka.NET actors to a higher level and discuss how to use the process manager pattern with actors to model long-running, stateful workflows that naturally occur in all sorts of business domains.
Process Managers
What is a process manager? A process manager is a state machine used to direct a dynamic, stateful workflow. In the context of modern software applications most process managers tend to be responsible for managing distributed workflows that are executed across different services or multiple instances of a service.
Process managers are:
- Reentrant - when we say “long-running” in the context of a workflow this often means durations measured in minutes, hours, or days - not seconds. Therefore, process managers are often programmed so they can be passivated (i.e. put to sleep) and recovered at a future point in time. We typically accomplish this using Akka.Cluster.Sharding in Akka.NET.
- Durable - in order to be reentrant process managers must persist their state to a durable store of some kind, typically either a cloud filesystem or a database. This is a good fit for Akka.Persistence.
- Driven by State Changes - process managers determine the next course of action in a workflow based on the output of the current and previous states. If we’re in error, perhaps we retry the most recent failed operation. If the operation failed irrecoverably, maybe we need to perform some reverisions and send a report back upstream.
- Not Responsible for Direct Execution of Processes - typically the process manager delegates the actual execution of workflow steps to the relevant services or actors; it’s the process manager’s responsibility to shepherd along the entire workflow, not implement individual steps.
Given these requirements, lets examine how we can use process managers within the context of a specific domain: executing a long-running, data-intensive analysis process.
Example: Asset Line Management
Asset Line Management is a type of financial analysis that companies who own large numbers of assets regularly need to perform for reporting, taxation, accounting, and investment purposes. It can be used by banks to compute the risk-adjusted market value of portfolios of loans or mortgages, manufacturers to track depreciation of hardware, real-estate companies to assess the value of land and buildings, and more.
This is a terrific use case for a process manager - because computing the value of multiple large asset lines on a regular occurring basis (i.e. once per month) can become quite complicated without it.
Here’s how we might model a simple ALM system using Akka.NET actors distributed in a cluster:
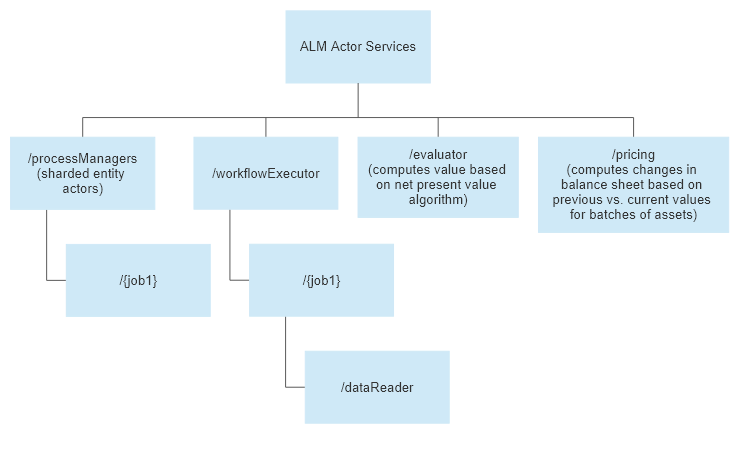
In this instance we’re going to go with five discrete actor types:
- The
ProcessManager- responsible for shepherding along theWorkflowExecutorand culminating the final results at the end. TheProcessManagerknows which other actors to call for each stage of the operation. - The
WorkflowExecutor, which is given a set of instructions from theProcessManagerfor querying asset data from a database and streaming each individual asset object through theEvaluatorActors. As individual objects’ batches of asset values are computed, progress reports will be sent to theProcessManager. - The
DataReaderactor, a child of theWorkflowExecutor, responsible for retreiving all of the records about assets, their properties (i.e. age, kind, price paid, etc) and streaming those records to theEvaluatorActor. - The
EvaluatorActor- a stateless worker actor that can compute the net present value of each asset based on its properties. It returns those results toWorkflowExecutoras a stream. - The
PricingActor- responsible for making balance sheet calculations based on the difference between net present value and the previously computed asset value.
How would we go about modeling the ProcessManager’s state and transitions?
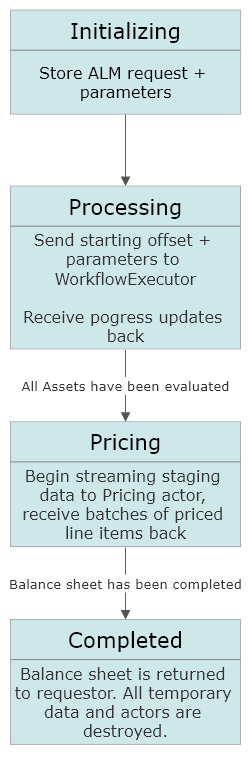
The ProcessManager never knows how to directly perform any of the tasks itself - it only knows how to tell the WorkflowExecutor or the PricingActor how to restart / resume work and it knows how to signal that the job has been completed. That’s it.
Error Handling
But what about error handling?
What will happen in the following scenarios?
- Processing - the
WorkflowExecutordies unexpectedly during the middle of retrieiving asset records for evaluation or - Pricing - the
PricingActortimes out and never returns a set of results we need for computing the balance sheet based on the data we evaluated.
In both of these cases the ProcessManager should have it covered - we’re using an offset system to determine how far through we’ve gone through the list of assets. Each time the WorkflowExecutor or the PricingActor completes its analysis of a batch of results, those results are persisted somewhere in our system (typically into a durable storage area that is available to the service, such as a database or file system) and the ProcessManager receives a progress update indicating how far through the partition we’ve gone. In the event that the WorkflowExecutor or PricingActor dies or times out, it’s possible for the ProcessManager to send a message to another node in the cluster, re-create those actors, and have them pick up exactly where the previous incarnation stopped - by using the offset from the last successful progress report.
Process Managers are simply a very useful type of state machine that makes it really easy for Akka.NET developers to organize and manage long-running, and often distributed workflows across an Akka.NET cluster. We hope you’ve found this conceptual article helpful and we look forward to following it up with a more hands-on implementation in the future.
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.

Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS