Jul 06, 2026

Introducing Netclaw: An Always-On, Autonomous Agent Built on Akka.NET
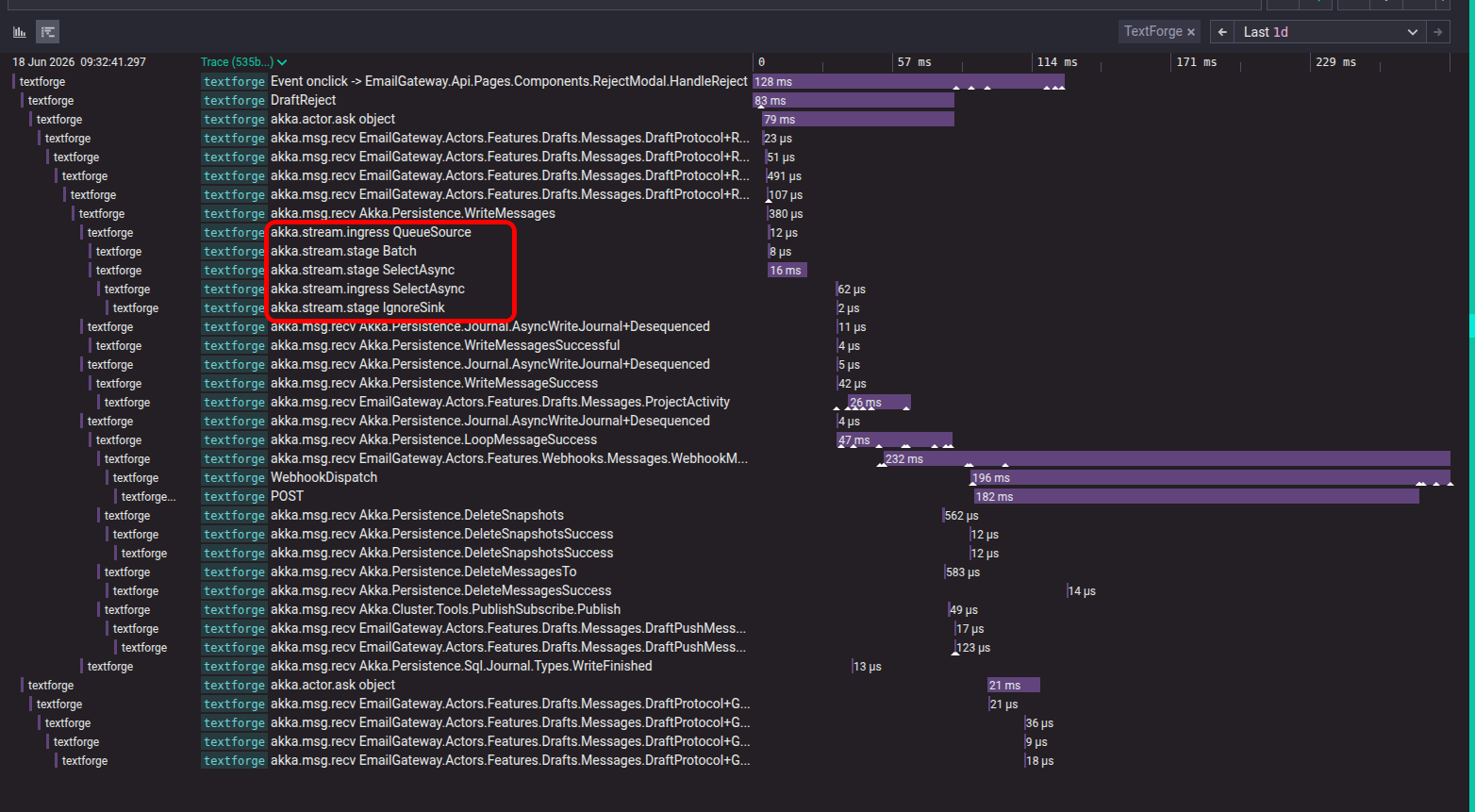
I’ve been wanting to write this post every single day for about six weeks now, and I finally get to: we shipped a brand new open source project called Netclaw. Netclaw is an always-on, autonomous personal assistant built on top...