Apr 15, 2021
How to Build Headless Akka.NET Services with IHostedService
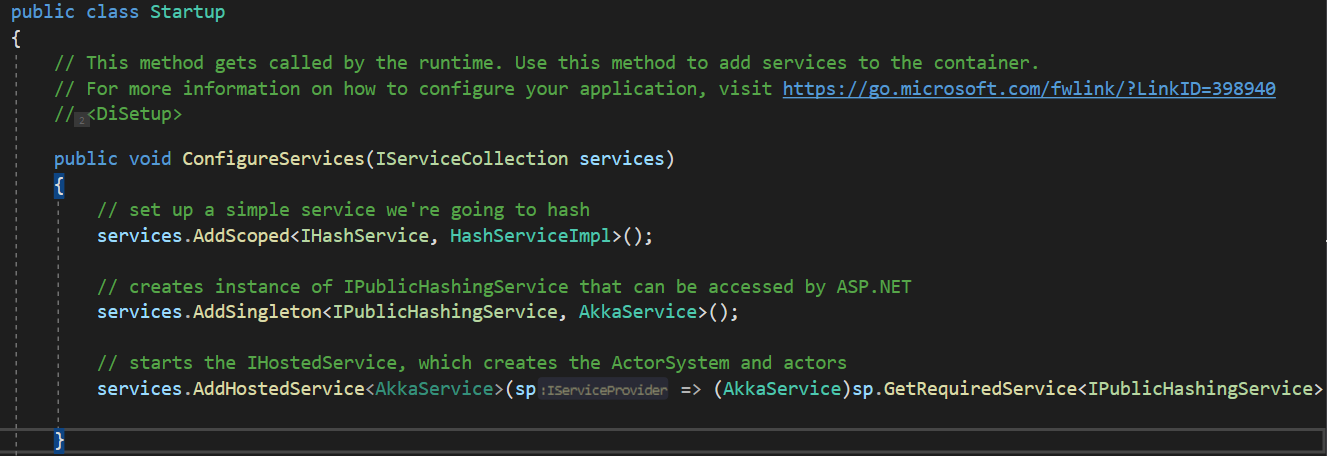
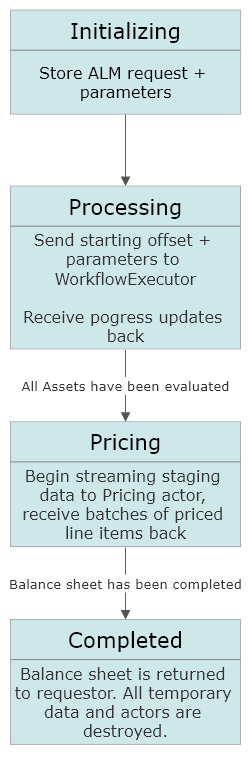
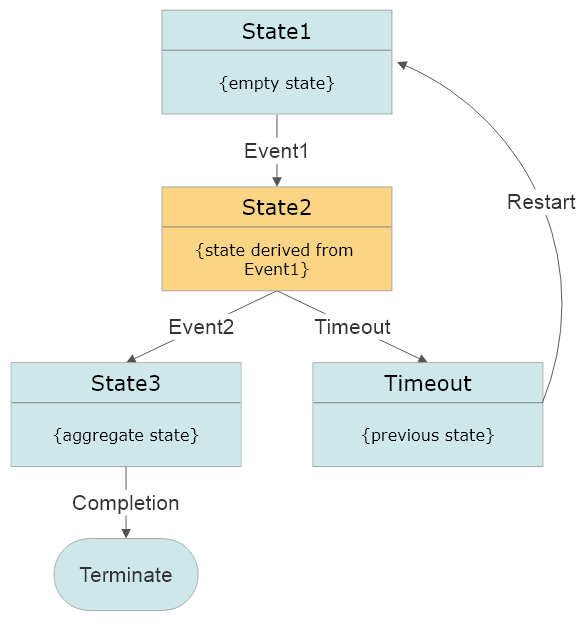
At Akka.NET’s inception, most of the server-side code samples we produced all demonstrated how to build so-called “headless” Akka.NET services as outright Windows Services primarily using libraries like Topshelf. .NET has changed tremendously since then and become a truly cross-platform...