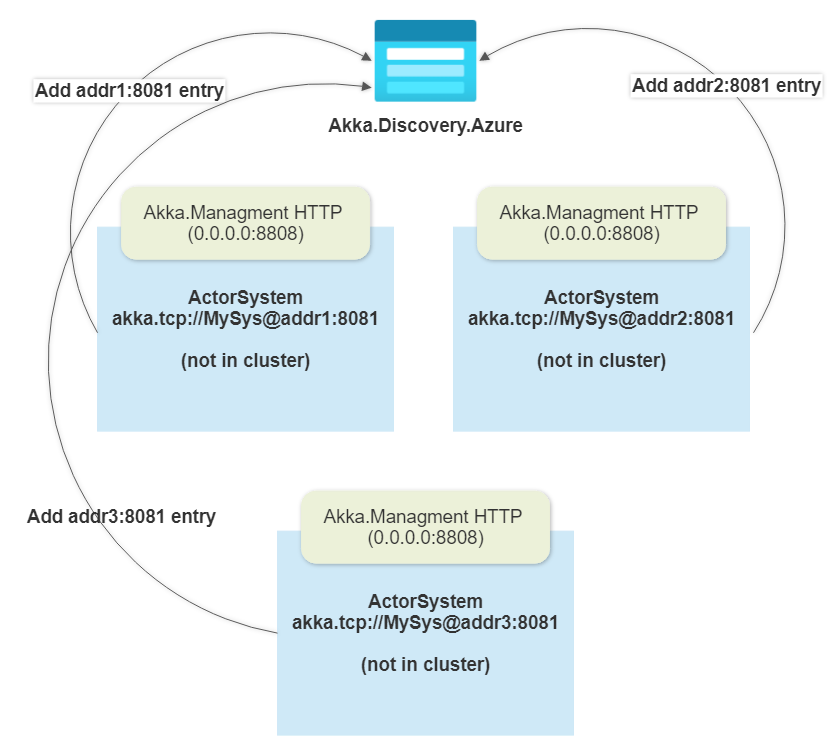
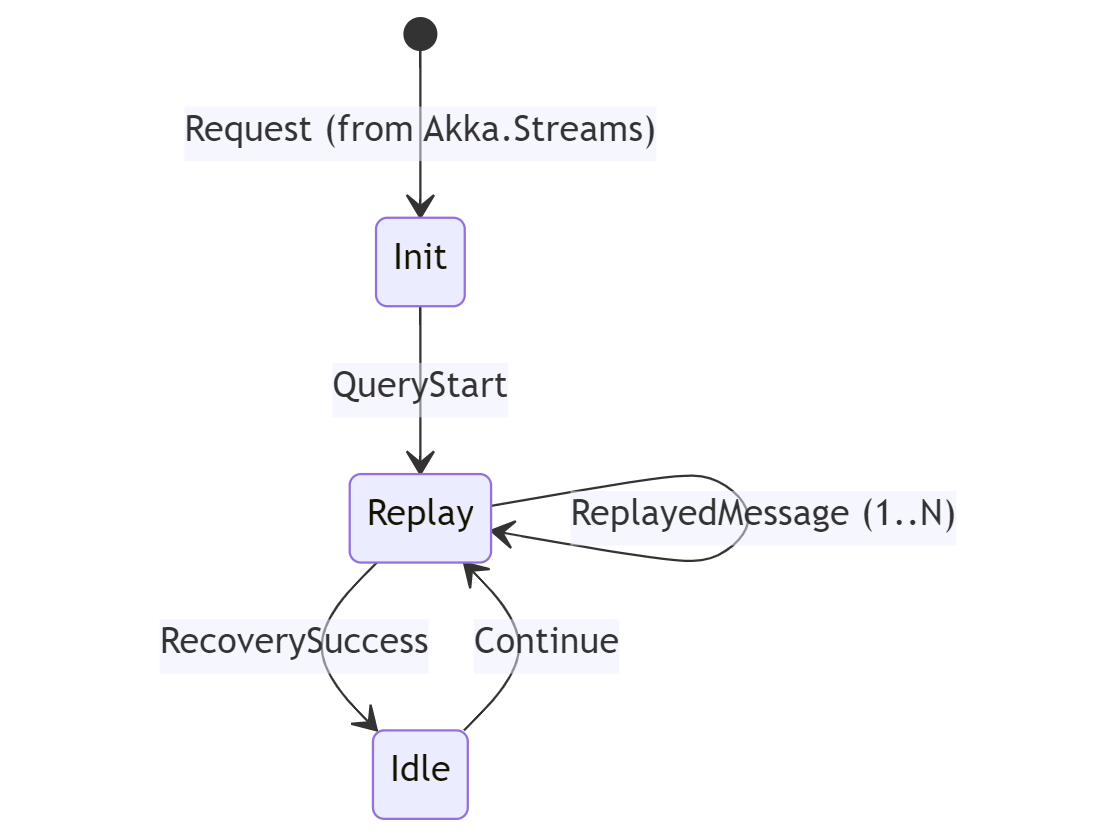
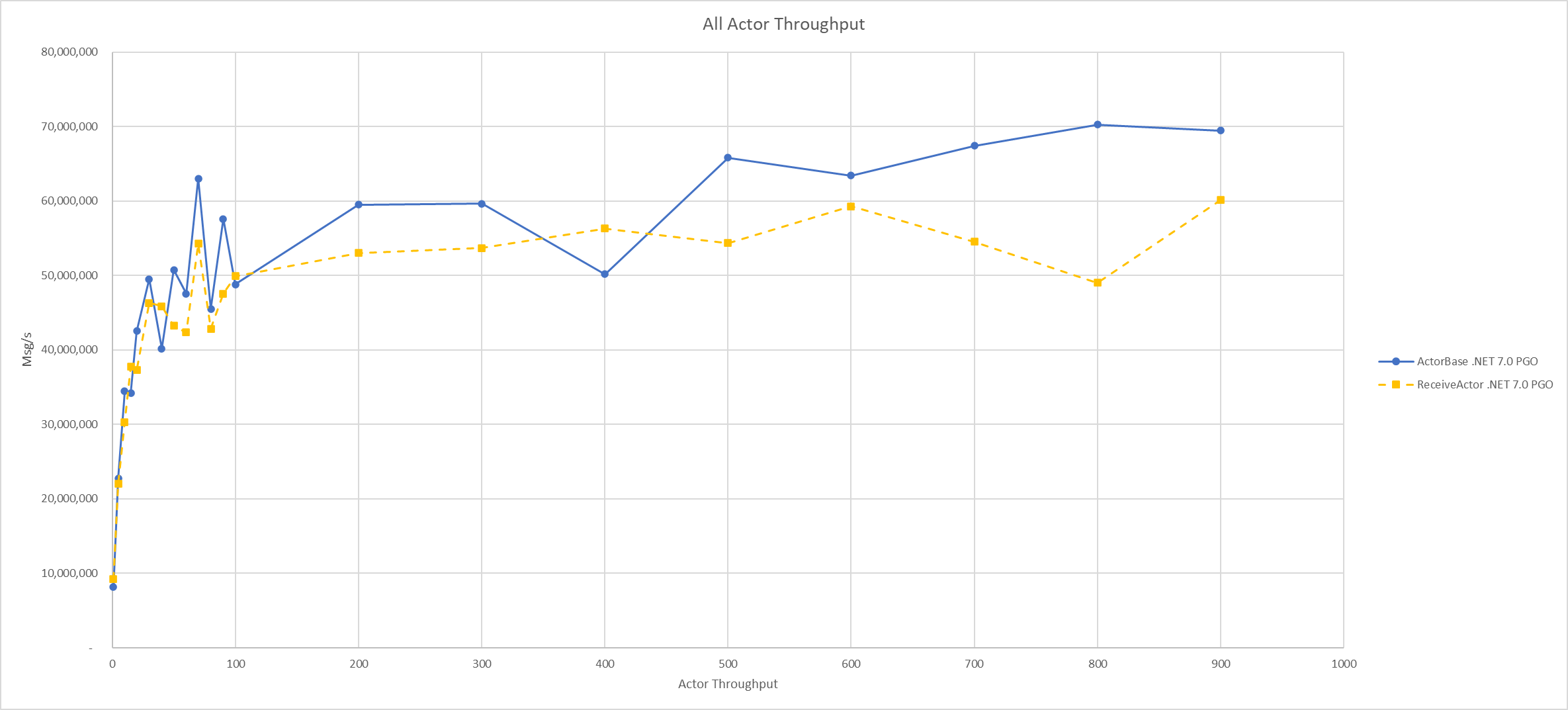
Dec 14, 2023

Solving Major Database Contention Problems with Throttling and Akka.NET Streams
When troubleshooting performance problems in distributed systems or locally-run, high-throughput-required software I tell our users “your most severe performance problems are almost always going to be caused by flow control issues.” My preferred batting order for troubleshooting performance issues is:...