// BLOG
Introduction to Akka.Cluster.Sharding in Akka.NET
Distributing State Evenly and Automatically with Self-Managing Actors
We have an updated guide to Akka.Cluster.Sharding that incorporates newer APIs and practices. Please see “Distributing State Reliably with Akka.Cluster.Sharding” instead.
In this post, we’ll discuss one of the Akka.NET plugins, Akka.Cluster.Sharding and how it gives us easier, higher level abstractions to work with actors (in this case also referred to as entities). Cluster.Sharding gives us:
- By using a logical keys (in form of ShardId/EntityId pairs) it’s able to route our messages to the right entity without need to explicitly determine on which node in the cluster it lives.
- It automatically manages the process of actor creation, so you don’t have to do it explicitly. When a message is addressed to an entity that didn’t exist, an actor for that entity will be created automatically.
- It’s able to rebalance actors across cluster as it grows or shrinks, to ensure its optimal usage.
Given all of those traits, let’s see how to utilize cluster sharding in a standard Akka.NET application.
Introduction to Akka.Cluster.Sharding
Here, we provide some introductory information on how to start working with cluster sharding plugin. First you need to get a dependency to prerelease version of Akka.Cluster.Sharing:
install-package Akka.Cluster.Sharding -Pre
Next we need to define something known as message extractor - it’s a component responsible for extracting ShardId/EntityId pair from the actual messages we send to our entities. It’s essential to cluster sharding routing logic and must behave exactly the same way on each node we’re having our entities on.
In this case we define a simple ShardEnvelope message that will wrap any kind of underlying message with the entity identifier.
public sealed class ShardEnvelope
{
public readonly string EntityId;
public readonly object Payload;
public ShardEnvelope(string entityId, object payload)
{
EntityId = entityId;
Payload = payload;
}
}
public sealed class MessageExtractor : HashCodeMessageExtractor
{
public MessageExtractor(int maxNumberOfShards) : base(maxNumberOfShards) { }
public override string EntityId(object message) =>
(message as ShardEnvelope)?.EntityId;
public override object EntityMessage(object message) =>
(message as ShardEnvelope)?.Payload;
}
Here we inherit from a predefined HashCodeMessageExtractor, that is part of cluster sharding module. You can read how does it affect message routing in paragraph below.
Next we need to define our custom entity actor. For a basic scenario, there’s no magic here. Cluster sharding is able to work with any kind of actor we wish. Often times end-users will create persistent actors so the entities can recover their state from a database when started again in the future. In this case we’re going to stick with a simple actor, non-persistent actor.
public class MyActor : ReceiveActor{
public MyActor(){
Receive<MyMessage>(_ => {
// update state
});
Receive<MyFetch>(_ => {
// fetch state
});
}
}
Since cluster sharding makes use of Akka.Persistence plugin to keep consistent view on a location of each shard, we need to setup both an event journal and a snapshot store. The thing to remember here is that those stores must refer to a database that can be accessed by every cluster node participating in cluster sharding protocol.
Akka.Cluster.Sharding will use the default event journal and snapshot plugin if not told to do otherwise. This means, that you may end with your business and sharding event mixed up with each other inside the same collections/tables. While it’s not mandatory, it’s good to configure cluster sharding to operate on a separate collections. Example below shows, how to do this by using Akka.Persistence.SqlServer plugin:
akka {
cluster.sharding {
journal-plugin-id = "akka.persistence.journal.sharding"
snapshot-plugin-id = "akka.persistence.snapshot-store.sharding"
}
persistence {
journal {
# set default plugin
plugin = "akka.persistence.journal.sql-server"
sql-server {
# put your sql-server config here
}
# a separate config used by cluster sharding only
sharding {
connection-string = "<connection-string>"
auto-initialize = on
plugin-dispatcher = "akka.actor.default-dispatcher"
class = "Akka.Persistence.SqlServer.Journal.SqlServerJournal,
Akka.Persistence.SqlServer"
connection-timeout = 30s
schema-name = dbo
table-name = ShardingJournal
timestamp-provider = "Akka.Persistence.Sql.Common.Journal.DefaultTimestampProvider,
Akka.Persistence.Sql.Common"
metadata-table-name = ShardingMetadata
}
}
snapshot-store {
sharding {
class = "Akka.Persistence.SqlServer.Snapshot.SqlServerSnapshotStore,
Akka.Persistence.SqlServer"
plugin-dispatcher = "akka.actor.default-dispatcher"
connection-string = "<connection-string>"
connection-timeout = 30s
schema-name = dbo
table-name = ShardingSnapshotStore
auto-initialize = on
}
}
}
}
Once we have our actors defined and a persistence plugins in place, we need to instantiate a shard region for them. Shard region is a container for all actors of given type living on a current node - this also means that if we want to span our cluster sharding capabilities onto multiple nodes, we need to instantiate the same shard region on each one of them.
Example:
using(var system = ActorSystem.Create("cluster-system"))
{
var sharding = ClusterSharding.Get(system);
var shardRegion = sharding.Start(
typeName: nameof(MyActor),
entityProps: Props.Create<MyActor>(), // the Props used to create entities
settings: ClusterShardingSettings.Create(system),
messageExtractor: new MessageExtractor(maxNumberOfNodes * 10)
);
// ... etc
}
Once we have everything set in place, we can simply use shardRegion to communicate with any entity living in the cluster, simply by providing it a message recognized by message extractor:
shardRegion.Tell(new ShardEnvelope("<entity-id>", new MyMessage()));
Entities passivation
Since cluster sharding takes over a process of managing actor’s life cycle, we may need to enhance our actors behavior when we want i.e. to stop them to when they’re not needed anymore. This is where passivation comes in.
Passivation is the process, in which an entity (actor) and its shard both mutually acknowledge the information about actor termination. This is necessary due to nature of asynchronous passing of messages to actor’s mailbox - while stopping, an entity may still be receiving messages routed through its shard. In that case those messages may be lost.
To prevent that, entity may send a Passivate message to its parent (the shard itself). This will trigger the shard to stop forwarding messages to an entity, buffering them instead. Passivation message also carries a stop message, that will be send back in order to stop an entity - by default you can simply pass a PoisonPill (see: How to stop an actor… the Right way). If you need a more advanced stopping procedure, you may decide to pass some custom message instead. Nonetheless expected effect of this is termination of an actor. In case if actor has stopped, while there were some messages addressed to it, a shard will resurrect that entity and flush awaiting messages back to it.
You may implement a simple garbage collection of idle entities by combining ReceiveTimeout and Passivate messages:
Context.SetReceiveTimeout(timeout);
Receive<ReceiveTimeout>(_ => {
Context.Parent.Tell(new Passivate(PoisonPill.Instance));
});
Why not just use consistent hash cluster routers to distribute state?
Cluster routers have been already discussed on this blog before (see: Distributing state in Akka.Cluster Applications), but to answer that question, first we need to understand similarities and differences between consistent hashing routers and cluster sharding.
From a high level perspective consistent hash cluster routers and cluster sharding appear to work similarly. We send a message with some kind of a key/identifier through an entry point, then the internal logic will ensure that the message will be routed to a single actor in the cluster responsible for handling that identifier - or will create the actor if it doesn’t exist yet - no matter where on the cluster it lives. However, the devil lies in the details.
In consistent hashing scenarios a whole key space is spliced between the number of actors we had defined in our router configuration. What does that actually mean? A single actor instance is responsible for handling whole range of key. For example: let’s say that we have a key space of numbers 1-100 shared equally between 5 actors behind consistent hash router. That means, first actor will be responsible for handling all messages with IDs 1-20, second actor 21-40, third one 41-60 etc. If your goal is to have a unique actor per identifier, this is not a valid scenario for your case. On the other side in cluster sharding scenarios each entity (this is how we refer to sharded actors) is identified by pair (ShardId, EntityId). It is 1-1 relationship, so messages identified with the same pair are guaranteed to always be routed to the same single entity.
Another difference is flexibility. Consistent hash routers are pretty much static and they don’t play well in situations, where you want to resize your cluster. Do you remember the concept of spliced key space, we’ve mentioned previously? Imagine how it will behave once we change actual number of actors/nodes assigned to it. Of course, those key ranges will have to change as well. So an actor that previously handled messages with IDs from 1-20, after cluster resize may now handle different range (i.e. 1-15). This is called a “partition handoff.” When using cluster sharding, our actors will be able to migrate to other nodes as cluster size will change, preserving the relationship between message id and sharded entity even when cluster size changes.
How to build a shard identifier
As said previously, we need a pair of identifiers. Most of the time finding right way to determine EntityId is quite simple, but it’s worth explaining how to do it. So how can we build shard identifiers?
First way is to look for natural group identifiers in our business domain. Offices, regions, projects etc. All of those can be potentially used as natural grouping key. In many domains, a message exchange is more frequent within boundaries of the same group than between them, which gives us additional way to optimize communication between actors lying in the same shard - as they’ll always live on the same node, we don’t need to pay the cost of the remote message transport here.
Question: what if those groups specified by natural keys vary in sizes? I.e. regions may have varying population of consumers, we want to represent using our shard entities. In that case we can provide further division of bigger shards, by using either natural or artificial sub keys for example 1 shard for Australia AU-1 and 3 shards for North America: NA-1, NA-2, NA-3.
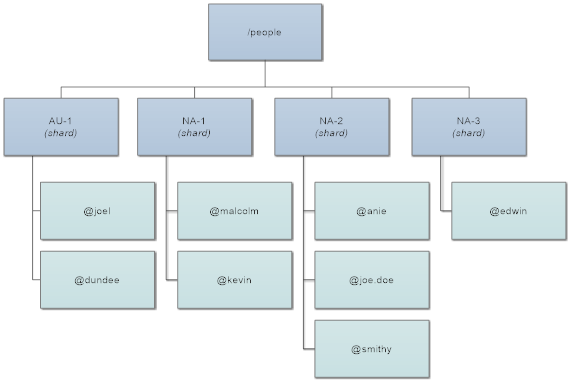
Other option is to establish grouping by using mathematical function. Cluster sharding provides an example message extractor for that, called HashCodeMessageExtractor. We’ve shown it already few paragraphs above. It simply provides a shard id by computing a modulo of hash code of an entity identifier. To work correctly it must have constant max number of shards, that will never be changed over the lifetime of the application - once specified, ShardId/EntityId pair for the same actor must never change. While setting a correct number of shards may be problematic, the rule of thumb proposed by Lightbend team (creators of original Akka implementation on the JVM) is to set the maximum shard count to 10x more than maximum number of nodes we will ever plan to use in our cluster.
References
Here you may find some resources, that will help you with your first steps on that topic:
- Official Akka.NET documentation
- A basic example that shows, how to use Akka.Cluster.Sharding together with persistent actors
- A slightly more complicated example, which combines cluster sharding, cluster singleton and persistent actors to live display vehicle fleet in the browser by using SignalR and Google Maps API.
About the Author
Bartosz Sypytkowski is one of the Akka.NET core team members and contributor since 2014. He’s one of the developers behind persistence, streams, cluster tools and sharding plugins, and a maintainer of Akka F# plugin. He’s a great fan of distributed functional programming. You can read more about his work on his blog: http://bartoszsypytkowski.com
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.
Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS