// BLOG
Solving Major Database Contention Problems with Throttling and Akka.NET Streams
Alleviate strain on production systems with in-process Akka.NET streams.
When troubleshooting performance problems in distributed systems or locally-run, high-throughput-required software I tell our users “your most severe performance problems are almost always going to be caused by flow control issues.”
My preferred batting order for troubleshooting performance issues is:
- Improve or resolve flow control issues;
- Eliminate wasteful I/O and round-trips; and
- Technical improvements - improve how efficiently work is performed leveraging mechanical sympathy.
This list is ranked in the order of “most likely to have largest real-world performance impact.”
In this post we’re going to address how you can use Akka.NET actors and Akka.Streams to easily resolve some one of the most painful flow control issues: database contention and bottlenecking.
Database Contention Explained
Database contention is a class of problem that creeps in on developers and typically doesn’t get discovered until it’s too late.
Take your typical stateless CRUD line of business application, for instance:
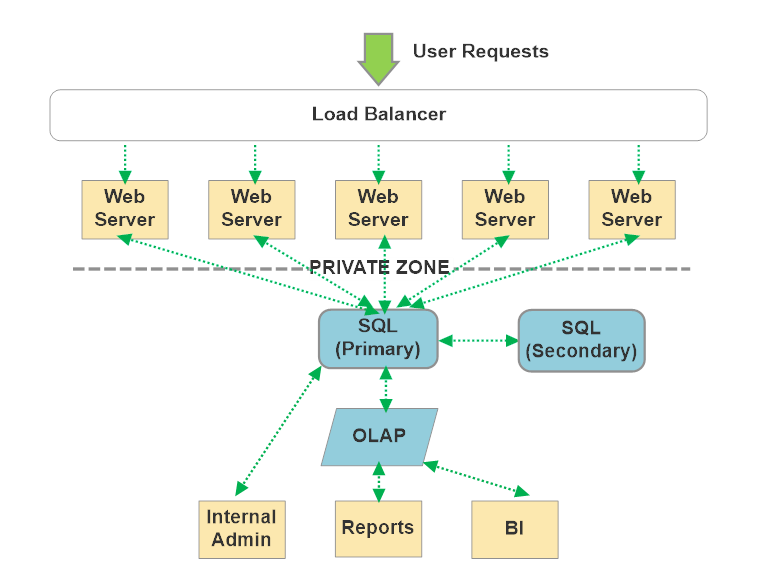
There’s nothing fundamentally wrong with this architecture. It’s extremely low-cost to deliver these types of designs usually - hence why they’re so ubiquitous. The centralization of data inside the database is what makes this design cheap: SQL Server, MongoDb, or whatever handles most of the hard problems around data consistency and synchronization.
However, all of these designs are vulnerable to “single point of bottleneck” flow control issues wherein the centralized database starts experiencing lock escalation / row or table contention / I/O bottlenecking pressure under load.
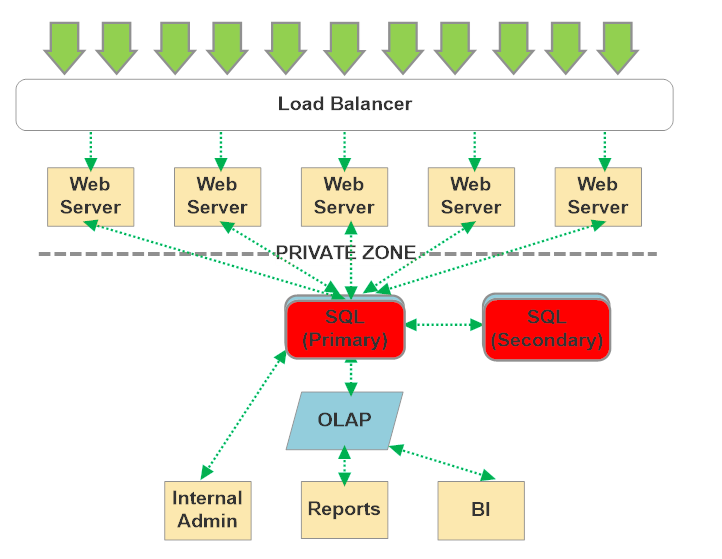
“Under load” is the key phrase that will indicate whether or not you’ll run into this problem - internal line of business applications with a relatively low number of concurrent tasks or users are unlikely to ever run into it.
However, once demand on your system starts scaling - and this includes both reads and writes, database contention might emerge in the following ways:
- Significant increases in end-to-end response time from the database;
- Query timeouts;
- Connect timeouts; and
- In really large-scale cases, connection pool saturation.
Usually at this point software developers will turn to:
- Caching;
- Performance-tuning the SQL queries; and
- In some cases, disabling database features such as using the
NOLOCKkeyword to reduce locking overhead on reads.
These approaches can usually help, to a degree, but they’re only addressing item 2 on my list: “eliminate wasteful I/O and round-trips.” It’s also worth noting that some of these approaches (caching and NOLOCK) may introduce new classes of problems: data consistency and stale reads.
For a web application with growing amounts of traffic these contention pressures are going to need to be addressed via flow control sooner or later.
Throttling with Akka.Streams
The correct flow control solution to these types of contention problems is limiting the number of parallel reads and writes to highly contended areas; this is “throttling.”
This is the exact same technique we applied to Akka.Persistence.Sql.Common internally inside Akka.NET last year, which we documented in our blog post “Scaling Akka.Persistence.Query to 100k+ Concurrent Queries for Large-Scale CQRS.”
Here’s what an underlying ASP.NET controller might look like:
public class ProductController : Controller
{
private readonly IProductService _products;
private readonly ILogger<ProductController> _logger;
public ProductController(IProductService products, ILogger<ProductController> logger)
{
_products = products;
_logger = logger;;
}
[HttpGet("index.json", Name = Routes.RegistrationIndexRouteName)]
public async Task<ActionResult<ProductIndexResponse>> ProductIndexAsync(string id,
CancellationToken cancellationToken)
{
var index = await _products.GetProductIndexOrNullAsync(id, cancellationToken);
if (index == null)
{
return NotFound();
}
return index;
}
}
And you can imagine that our IProductService abstracts over something like Entity Framework or whatever, where the underlying database calls are made:
public interface IProductService{
Task<ProductIndexResponse?> GetProductIndexOrNullAsync(string id,
CancellationToken cancellationToken = default);
// i.e. other CRUD methods pertaining to Products
}
public sealed class ConcreteDatabaseImplementation : IProductService{
private readonly DbContext _myDomainContext;
// i.e. implementations of interface methods using EF et al
}
In this status quo ASP.NET application, you have the following flow control:
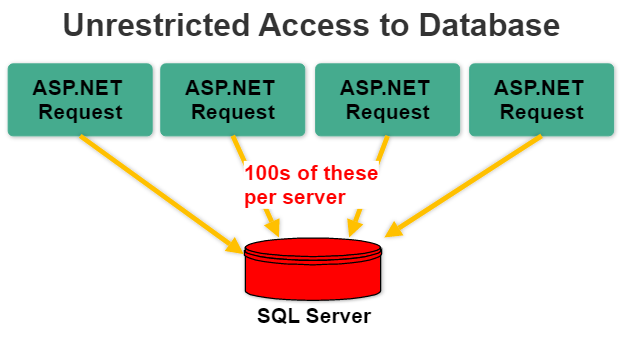
The degree of concurrent database access is unbounded and this is what introduces all of the performance problems described earlier.
Now, we can introduce a local ActorSystem that uses a single Akka.Streams graph to impose an explicit degree of parallelism, per-server, on database access for the IProductService.
First thing we’re going to do: instead of calling Db access methods directly, we need to codify these into messages so they can be queued into an Akka.NET actor’s mailbox and reasoned about:
/// <summary>
/// Use a message to describe what type of database operation we want to perform.
/// </summary>
public interface IDbOperation
{
CancellationToken CancellationToken { get; }
}
public sealed record ReadProductById(string ProductId,
CancellationToken CancellationToken) : IDbOperation;
We’re going to embed a cancellation token directly inside the queued message so the Akka.Streams processor can determine if the request this message correlates to has already timed out - that way we can simply discard this message instead of processing it, which will stop us from wasting resources on doomed requests.
Next, we’re going to build a ThrottlerActor that uses Akka.Streams internally to control the degree of parallel database access:
using Akka.Actor;
using Akka.Streams;
using Akka.Streams.Dsl;
namespace MyAkkaApp.Actors;
public sealed class ThrottlerActor : ReceiveActor
{
private readonly IServiceProvider _sp;
private ISourceQueueWithComplete<(IDbOperation, IActorRef)> _dbOperationQueue;
public ThrottlerActor(IServiceProvider sp)
{
_sp = sp;
ReceiveAsync<IDbOperation>(async dbOp =>
{
// will block and buffer messages inside actor's mailbox once queue reaches capacity
await _dbOperationQueue!.OfferAsync((dbOp, Sender));
});
}
protected override void PreStart()
{
_dbOperationQueue = Source.Queue<(IDbOperation, IActorRef)>(100, OverflowStrategy.Backpressure)
.ToMaterialized(Sink.ForEachAsync<(IDbOperation, IActorRef)>(10, async tuple =>
{
var (dbOperation, replyTo) = tuple;
if (dbOperation.CancellationToken.IsCancellationRequested)
{
// if the cancellation token is already cancelled, we can't do anything
Sender.Tell("request failed");
}
using var scope = _sp.CreateScope();
var db = scope.ServiceProvider.GetRequiredService<ConcreteDatabaseImplementation>();
switch (dbOperation)
{
case ReadProductById readProductById:
var result = await
db.GetProductIndexOrNullAsync(readProductById.ProductId,
readProductById.CancellationToken);
replyTo.Tell(result);
break;
default:
throw new NotSupportedException(
$"Unsupported IDbOperation type [{dbOperation.GetType()}]");
}
}), Keep.Left)
.Run(Context.Materializer());
}
protected override void PostStop()
{
_dbOperationQueue?.Complete();
}
}
What we are fundamentally doing here is re-arranging the flow of control to look like this:
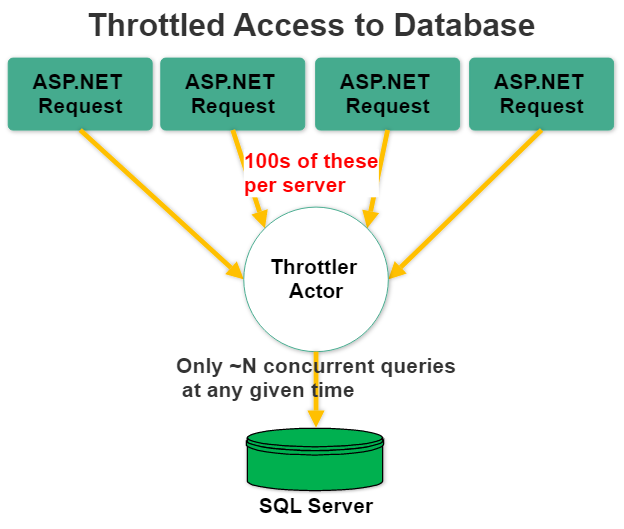
How Throttling Solves Contention Problems
How does throttling solve database contention problems?
- Reduces total pressure on the database - instead of allowing an unbounded number of queries per node to hit the database all at once, which strains it, we are limiting the degree of parallelism-per-node to 10 queries-per-node in this case. That value is configurable and arbitrary: a larger number of queries might be perfectly acceptable in your use case. But the point is, bounding the number of outstanding queries at any given time gives the database fewer things to do simulatenously and improves the odds that all presented queries will be completed successfully and quickly.
- Moves waiting from an expensive area to a cheap one - you are waiting for these queries to complete regardless of where the waiting happens. If we’re able to improve average query execution time by reducing contention on the database, then the latency overhead of having pending queries sitting in the Akka.NET actor’s queue will be paid for many times over. You should see a noticeable increase in total throughput when this happens.
- Makes parallelism a measurable, tunable, configurable factor in the system - the key line in this Akka.Streams sample code is:
Sink.ForEachAsync<(IDbOperation, IActorRef)>(10, async tuple =>; the10value determines the number of concurrent operations allowed at any given time. That value can be lowered or raised depending on your circumstances. Either way though, you’re now in a situation where you, the developer are in charge of how much traffic each of your server instances can send to the database at any given time. It’s no longer an uncontrollable byproduct of activity applied to the server.
You’ll notice this approach is quite similar to the tried-and-true “put a queue in front of it” approach to solving database contention problems. There are some very important differences, however:
- No external infrastructure required - all of this code works in process using an
ActorSystemrunning in the background of your ASP.NET application; no need for RabbitMQ or Azure Service Bus or whatever; - No serialization required - because nothing is going over the network, there’s no need for serialization. All message passing is in-memory. This is why we can pass
CancellationTokens directly to Akka.NET. - Queue consumption is per-process - all of the rate limits we’re setting in Akka.Streams are per-process, rather than globally, which means that you should adjust your maximum degree of parallelism accordingly.
This approach is 1-2 orders of magnitude simpler than trying to set up a traditional persistent-queue based approach.
Integrating Akka.Streams with ASP.NET Core
Ok, so we have our actor-to-database infrastructure ready to go. How do we integrate the Akka.NET and database changes back into ASP.NET?
Using Akka.Hosting this is quite easy to do:
using Akka.Actor;
using Akka.Hosting;
using MyAkkaApp;
using MyAkkaApp.Actors;
var builder = WebApplication.CreateBuilder(args);
// register IProductService
builder.Services.AddScoped<ConcreteDatabaseImplementation>();
builder.Services.AddSingleton<IProductService, ThrottledImplementation>();
builder.Services.AddControllers();
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
builder.Services.AddAkka("MyActorSystem", (akkaBuilder, provider) =>
{
// Configure your ActorSystem here
akkaBuilder.WithActors((system, registry, di) =>
{
// start ThrottlerActor and add to registry
var throttlerActor = system.ActorOf(di.Props<ThrottlerActor>(), "throttler");
registry.Register<ThrottlerActor>(throttlerActor);
});
});
We just call the AddAkka method to our IServceCollection, start an instance of our ThrottlerActor, and then use the ActorRegistry to save a copy of it.
We also have to add a new implementation of the IProductService we used previously, which will talk to Akka.NET instead of the database directly:
public sealed class ThrottledImplementation : IProductService
{
private readonly IActorRef _throttler;
public ThrottledImplementation(IRequiredActor<ThrottlerActor> throttler)
{
_throttler = throttler.ActorRef;
}
public Task<ProductIndexResponse?> GetProductIndexOrNullAsync(string id, CancellationToken cancellationToken = default)
{
return _throttler.Ask<ProductIndexResponse?>(
new ReadProductById(id, cancellationToken),
cancellationToken: cancellationToken);
}
}
The IRequiredActor<ThrottlerActor> implementation corresponds directly to the registry.Register<ThrottlerActor>(throttlerActor); method we invoked when we started our ThrottlerActor. The Microsoft.Extensions.DependencyInjection runtime will correctly resolve our ThrottlerActor instance each time it injects the IRequiredActor<ThrottlerActor> into an ASP.NET Controller or any of its dependent services, such as this IProductService implementation.
This IProductService implementation works by using Akka.NET’s Ask<T> pattern, which creates a single use actor that will dispose itself once someone replies to it for the first time. That IActorRef created by the Ask<T> operation is the IActorRef you see inside the (IDbOperation, IActorRef) tuple processed by the ThrottlerActor’s Akka.Streams graph.
Finally, we close the loop by changing our DI registration for the IProductService itself:
builder.Services.AddScoped<ConcreteDatabaseImplementation>();
builder.Services.AddSingleton<IProductService, ThrottledImplementation>();
This will ensure that our throttled IProductService implementation is injected into our ProductController, rather than the original concrete implementation that talks directly to the database.
The full source code for this sample is available here: https://github.com/Aaronontheweb/AkkaStreamsDatabaseThrottlingExample
Wrapping Up
If you’re unsure of whether or not this would work for your case: I promise, it will. Throttling is an extremely common approach to solving shared resource contention issues, hence why it’s used for things like rate-limiting external callers to public APIs.
For further reading on the subject, take a look at the actual numbers throttling produced for Akka.Persistence.Query itself when we started using it inside our plugins: “Scaling Akka.Persistence.Query to 100k+ Concurrent Queries for Large-Scale CQRS.”
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.

Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS