// BLOG
The Proper Care and Feeding of Akka.NET Clusters: Understanding Reachability vs. Membership
How Akka.Cluster Achieves Partition Tolerance
Akka.Cluster is one of the most popular and useful parts of the Akka.NET ecosystem as a whole, but it’s also one of the most concept-heavy areas. We have a lot of literature on both the official Akka.NET documentation and elsewhere on our blog about concepts such as distributing state in Akka.Cluster, sharding data across cluster nodes using Akka.Cluster.Sharding, publishing messages across a cluster, and so on; however, that barely scratches the surface on the possibilities and uses of Akka.Cluster.
So my goal with this post is to provide a bit of an FAQ on some of the most important and central concepts needed to build and operate effective Akka.NET clusters.
Node Reachability vs. Membership
In Akka.Cluster there are two important, similar-looking concepts that every end-user should be able to distinguish:
- Node reachability - is this node available right now? Can I connect to it?
- Node membership - is this node a current member of the cluster? Is this node leaving? Joining? Removed?
When many users start working with Akka.Cluster, they operate from the assumption that these two concepts are the same. “If I kill a process that is part of an Akka.NET cluster, that process will no longer be part of the cluster.”
This assumption is incorrect and there’s an important distributed computing concept at work behind this distinction: partition tolerance.
In terms of the CAP theorem, Akka.Cluster provides an AP experience out of the box; Akka.Cluster developers typically trade away some of the cluster’s default availability and partition tolerance (A & P) in exchange for consistency in areas where their domains demand it.
Akka.Cluster’s partition tolerance abilities come from this “reachability” feature; in order to tolerate partitions you have to know where they are and what resources are affected by them first. That’s exactly what the ClusterEvent.IReachabilityEvent notifications will tell you.
The cluster assumes that all network partitions are temporary by default, therefore any current member nodes that are “unreachable” to any other nodes will probably be reachable again in the near future. A node’s “reachability” has no bearing on a node’s membership in the cluster by default.
Akka.Cluster’s assumption usually holds true in practice. The most common sources of network partitions, such as a blip on the network, a process crash + restart, or a CPU-pegged node that becomes unresponsive are all temporary problems that can be resolved quickly and automatically.
Here’s where the concept of partition tolerance gets realized: don’t assume that the nodes on the other side of the network partition are dead just because you can’t reach them; those nodes might still be actively doing work and might be available to do work again in the future. Give the unreachable nodes a limited window of time to reconnect and report back on whether they completed their work successfully or not. You can restart their work or re-route it to other nodes, but here’s the thing: removing a node from the cluster is a “forever” thing. Removed members can’t rejoin the cluster until they are restarted. So dealing with unreachable nodes aggressively is a mistake.
Partition Tolerance Example
Suppose you built a large scale analytics system that distributed batch analysis jobs out to a group of 100 nodes in your network. You queue up a really large analysis job and chunk out the work to the cluster. The nodes start to get busy and one of them pegs their CPU and becomes unresponsive for 30 seconds. During that 30 second window, the node is still working on the job you assigned it, but it’s not replying to incoming messages quickly.
Once that node stops replying to the others for a period longer than say, 10 seconds, we assume the node is “unreachable” because we aren’t receiving any replies from it. What’s the right thing to do in this situation?
Well, if a human were watching this situation happen in real time with all of the knowledge expressed above, they’d do the right thing: wait for the system to recover and respond on its own. And so long as that pegged node responded within a reasonable amount of time the system could recover from that network partition and determine whether the units of work assigned to the temporarily partitioned node were completed successfully or not.
This above model for partition handling is, in essence, how Akka.Cluster’s reachability mechanism operates by default.
Unfortunately, this is not how many software developers view or handle network partitions. The pervading assumption in the hundreds of projects I’ve reviewed and questions I’ve been asked is that network partitions are permanent by default. I.E. the reason a node disconnected must be because that node has been shutdown or the hardware has failed and the system won’t be able to heal on its own.
Therefore, many developers treat network partitions as terminating events: anything the nodes were working at the time the partition occurred must have failed and will need to be restarted. All state on those nodes will need to be moved. The node is never coming back. And so on. In Akka.Cluster terms, this means “unreachable == node has left the cluster.” If you operate a cluster this way, all it will take is one major surge in traffic to render your entire system inoperable as hardware resources like CPU and network hit their limits and nodes become unreachable.
This approach towards network partition handling results in systems that are extremely brittle and inefficient. Rather than letting the software recover on its own, now you need complex process management tools for detecting cluster member exits and automating restarts. You respond to partitions by needlessly restarting and redoing work in a manner which can actually compound the problems that brought on the network partition in the first place.
Many developers do this not because it’s a good way of running a cluster, but because they haven’t critically examined their assumptions about what two nodes disconnecting from each other actually means in terms of availability. Akka.Cluster’s philosophy in this regard is robust: “partitions are most often temporary in nature and we should be hesitant to treat unreachable nodes as though they’re permanently offline.”
Assume Network Partitions are Always Temporary by Default
Akka.Cluster’s assumption that changes in reachability of nodes in the network is always temporary in nature gives Akka.NET developers the opportunity to tolerate some network partitions. To be notified about network partitions you can subscribe to IReachability events inside actors inside your Akka.NET application via the following syntax:
using Akka.Actor;
using Akka.Cluster;
public class MyActor : ReceiveActor{
protected override void PreStart(){
Cluster.Subscribe(Self, typeof(ClusterEvent.IReachabilityEvent));
}
public MyActor(){
// node becomes unreachable
Receive<ClusterEvent.UnreachableMember>(m => { });
// node becomes reachable again
Receive<ClusterEvent.ReachableMember>(m => { });
}
}
Some tools like Akka.Cluster.Sharding and Akka.Cluster.Tools.Singleton will handle network partitions by assuming that actors hosted on currently unreachable nodes are still alive and working, even if they can’t be contacted right now. Therefore, no action is taken against those unreachable node by those tools.
It’s only when an unreachable node’s membership status is changed from Up or WeaklyUp to Down that those tools decide “ok, this network partition isn’t going away and we need to move all of the work and state that node owned to some other place in the cluster.”
Other tools, like clustered routers, deal with network partitions by simply not routing new messages to unreachable nodes. If an unreachable node comes back, the routers will add those nodes back to the routing table and resume delivering messages.
Your code should follow similar assumptions: give network partitions a window of time to heal on their own before you take “terminal” action against an unreachable node.
When to Remove Unreachable Nodes from a Cluster
Assuming all network partitions are temporary is a good default, but it doesn’t cover all of the real-world cases. There are plenty of instances where network partitions are indeed permanent: hardware failures, changing the location of a network resource, and scaling down a cluster are all examples of this class of partition.
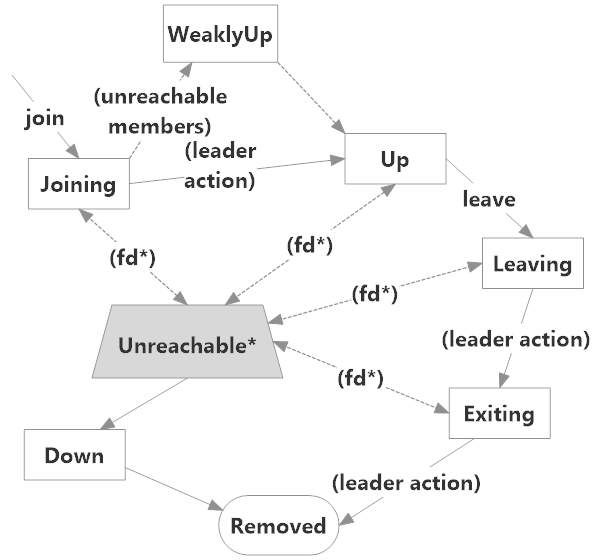
The above diagram demonstrates the membership state transitions a node can undergo with Akka.Cluster. The “unreachable” zone is a type of purgatory essentially, where we don’t have complete information on the node’s state because at least some nodes aren’t able to contact it. If the node is only unreachable temporarily it will quickly return to its previous membership state.
However, if an unreachable node is permanently offline then we have to issue a Cluster.Down command for that node. Any node in the cluster can down any other node, and this will result in the downed node’s removal from the cluster’s membership.
There are a number of different tools we can use to attempt to detect and down permanently unreachable nodes:
- Petabridge.Cmd’s
cluster downandcluster down-unreachablecommands offer a human-supervised method of downing unreachable nodes; - The Split Brain Resolvers added to Akka.Cluster in Akka.NET v1.3.3 are an automated mechanism for safely downing unreachable nodes based on how long the node has been unreachable and a couple of different strategies designed to limit how aggressively nodes can be downed during severe network outages; and
- You can write a custom
IDowningProviderimplementation that can use domain-specific rules for determining when to down an unreachable node.
Here at Petabridge, we ship all of our applications with Petabridge.Cmd installed. If we’re building applications on public cloud environments and we intend on taking advantage of auto-scaling then we use the keep-majority split brain resolver strategy with the following configuration:
akka.cluster{
split-brain-resolver {
active-strategy = keep-majority
stable-after = 30s
}
down-removal-margin = 30s
}
This strategy won’t kick an unreachable node out of the cluster until it’s been unreachable for just over a minute. You can adjust the timeframe to be larger or use a different strategy altogether; it’s highly configurable.
I hope you’ve found this helpful!
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.

Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS