// BLOG
Akka.NET vs. Kafka, RabbitMQ, and Other Messaging Systems
What's the difference between Akka.NET, Kafka, RabbitMQ, and other message-driven technologies? Can they work together?
A while back I created a thread on Twitter to attempt to explain the difference between Akka.NET and some other popular message-distribution and queuing technologies, such as Apache Kafka and RabbitMQ.
Common question I get from users who are just starting to look at @AkkaDotNET : why use something like Akka .NET and not Kafka / RabbitMQ? What's the differences between these two pieces of technology? Can they be used together? Or are they competing technologies?
— Aaron Stannard (@Aaronontheweb) January 29, 2019
I’m going to cover that in some more detail in this post because it’s a common question asked by many developers who are just starting to look into Akka.NET.
Differences between Akka.NET, Kafka, RabbitMQ, and Other Messaging Systems
Message brokers, enterprise message buses, message queues, event hubs, and so on - for the sake of simplicity, which I’m certain will enrage developers in some corners of the Internet, I’m going to lump these technologies together into a single category: these are message distribution systems.
The manner in which they distribute messages varies and for our purposes those differences are totally immaterial (sorry, vendors.) The point is: producers write messages into these systems and the goal is, with varying degrees of reliability, concurrency, and asynchrony, to distribute these messages for processing to one or more downstream consumers.
Message distribution systems are transports - they aren’t involved in the act of creating or consuming messages. Only in delivering and routing these messages from their sources and to their destinations.
Where Akka.NET differs: Akka.NET actors are fundamentally message processing and message producing technologies.
Akka.NET actors are responsible for managing business state or executing commands, both of which occur when an actor receives a message.
Where the confusion occurs, however, is because Akka.NET actors also have built-in transports - the IActorRef, the “actor reference,” used to send messages to an actor can deliver messages via in-memory messaging to other actors running locally inside the same process or to actors running in remote process via Akka.Remote. Akka.Remote’s default message delivery mechanism relies on a single TCP connection between two remote processes.
This is the fundamental difference - you can’t build an application using Kafka on its own as there would be nothing to produce or consume the messages. You could, however, build a stand-alone system that runs entirely on Akka.NET and uses Akka.Remote / Akka.Cluster to carry out all of the message distribution between different parts of the system AND all of the message production and processing needed to complete the work.
Other Differences
There are some other differences between message distribution tools like Kafka and Akka.NET that are worth noting:
Akka.NET doesn’t persist or guarantee delivery of messages by default whereas Kafka, RabbitMQ, and other technologies typically do. This is because the vast majority of messages in Akka.NET are passed in-memory between actors running locally in the same processes, thus reliability guarantees stronger than “at most once” delivery (the simplest and least expensive delivery option) aren’t needed very often. It’s worth noting, however, that across process boundaries Akka.NET developers often use AtLeastOnceDelivery actors in Akka.Persistence to make delivery state durable and resilient to network failures.
Kafka and other message distribution technologies, on the other hand, almost always distribute messages from one process to another - thus it’s necessary to provide some resiliency against network partitions and common hazards of inter-process communication by persisting messages and possibly guaranteeing their delivery.
Akka.NET actors are extremely inexpensive to create and destroy, thus it’s common for developers to have hundreds of thousands to millions of them running concurrently in a each process. As of writing this, on .NET Framework 4.5 a single Akka.NET actor takes up about 1.7kb of memory (we want to get that number down to ~1kb, ideally) - the memory footprint is going to likely be lower on .NET Core as a result of improvements made to the CLR and some of the base types themselves. The point is, however - they’re cheap and disposable resources, unlike a Kafka subscription.
Actors are usually kept around for as long as the business state they’re mutating is actually needed by the program - for instance: if you’re keeping track of click-stream activity on an eCommerce website in order to make personalized product recommendations for each individual user then you’d likely use the “child per entity” pattern to isolate the state for each individual, concurrent user inside its own actor. Once that user stops clicking on the website, messages stop being sent to that actor, the actor can receive a notification that it’s been idle for longer than X amount of time, the actor will choose to self-terminate, and that actor’s state is usually persisted and then the actor is terminated in order to free up resources for other actors who need to process messages.
Could Akka.NET be Used in Combination with Kafka, RabbitMQ, and Other Messaging Systems?
Akka.NET is very frequently used in combination with other messaging systems inside large-scale .NET applications. The most common reason is because Akka.NET naturally compliments a technology like Kafka on both the producer and consumer sides of the queue: it’s an efficient and effective tool for producing or consuming messages.
It’s common for Petabridge to see our customers using designs that intentionally leverage Kafka and Akka.NET simultaneously, like this one below:
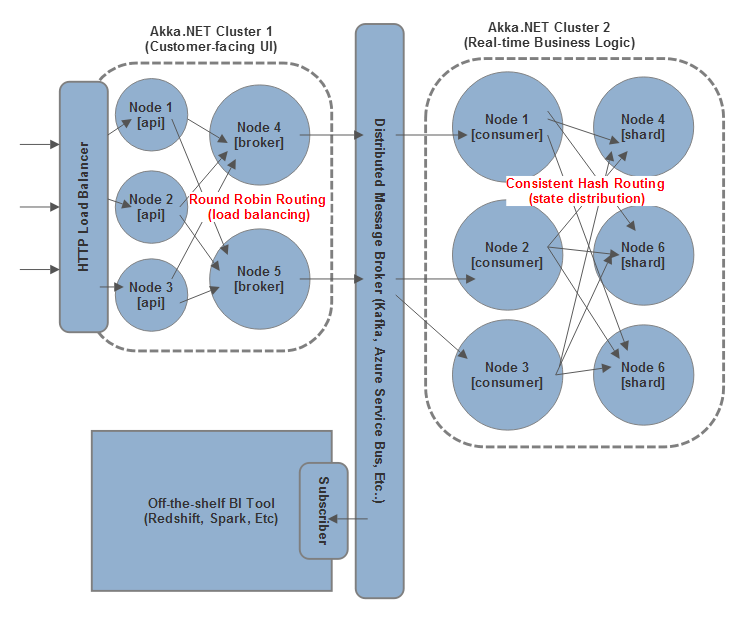
In this scenario, the application compromises of multiple services that are developed by independent teams and have to carry out some sort of real-time workload on behalf of customers. Some high-level examples of this: real-time search, dynamic pricing, messaging, monitoring, and so on - some of the typical use cases for Akka.NET and Akka.Cluster.
The front-end application, an independent Akka.NET cluster, might stream input from users to the back-end service, another real-time Akka.NET cluster performing state aggregation and reacting to changes in state.
In this scenario Kafka gets used as a layer for decoupling the two clusters from each other so one can be deployed without affecting the other - the business logic cluster consumes its data from the web UI cluster and produces updated outcomes in real-time, which in-turn might be consumed by other services not pictured on the diagram.
Kafka might also be used to pass along other relevant pieces of data to the business logic cluster from other services, such as third party integration services or other web APIs developed by different teams. Rather than having all of the developers in one company building one giant Akka.NET cluster, each product is broken out into its own cluster and Kafka gets used for cross-service messaging in scenarios where bi-directional messaging isn’t required. That’s just one example - there are many others.
I hope you’ve found this helpful, and as always: if you have questions please leave them in the comments below!
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.

Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS