Jan 19, 2023
2022 Akka.NET Year-in-Review and Future Roadmap
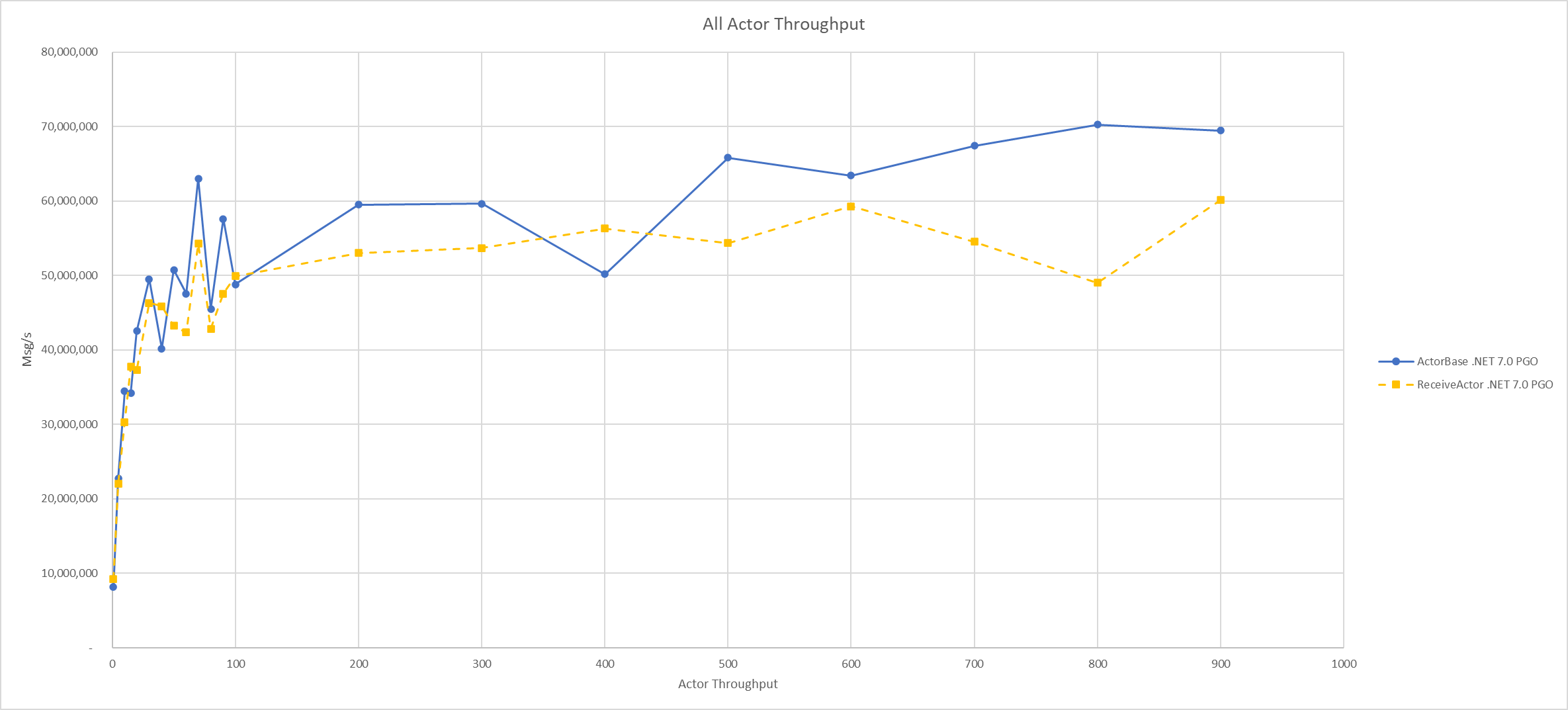
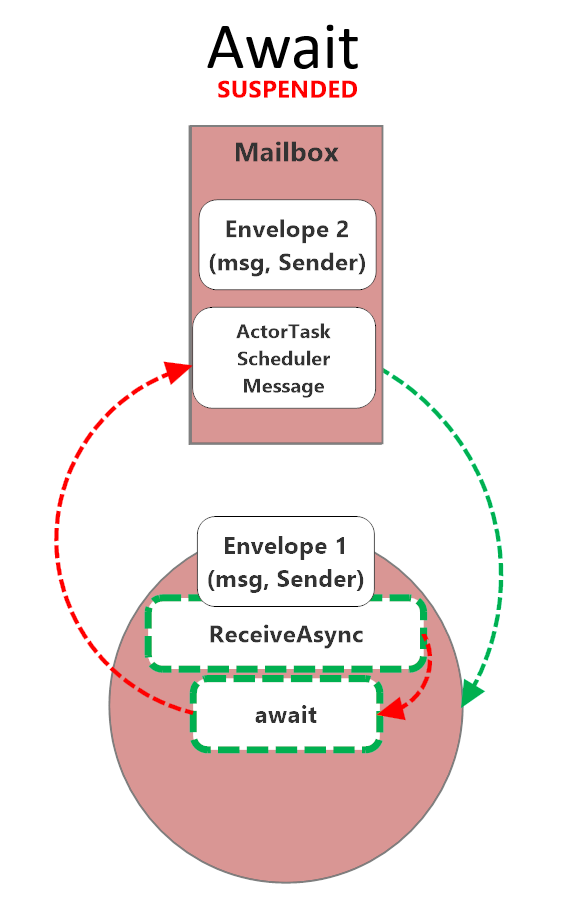
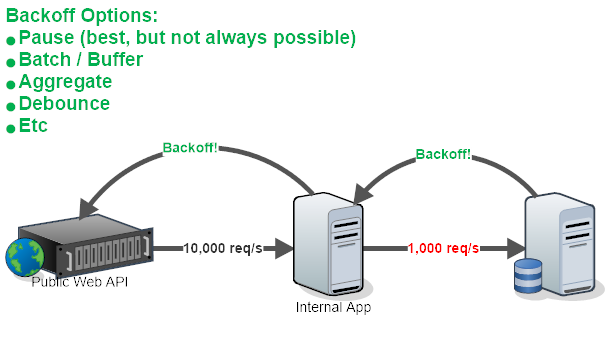
Author’s Note: Petabridge turned 8 years old this month and over the years I’ve only written a couple of articles about our internal processes for developing software and running an open source software business. In late 2021 we began using...