// BLOG
Distributing State in Akka.Cluster Applications
Consistent Hash Distributions and Clustered Routers
[!IMPORTANT] This blog post is out of date and the practices here are no longer recommended for state distribution with Akka.NET. Please see “Distributing State Reliably with Akka.Cluster.Sharding” instead.
One of the most frequently asked questions about Akka.Cluster I receive is “how do I reliably distribute state in an Akka.NET Cluster?”
Akka.Cluster is primarily for building highly available, soft real-time applications in server-side environments - and one of the concepts that is essential to delivering “soft real-time” is statefulness.
Stateful applications are becoming more and more common because they execute types of work that are infeasible and impractical with stateless CRUD applications, but they also introduce new types of challenges such as:
- How do I evenly distribute state across my cluster? No “hotspots.”
- How do I find the state I need within my cluster?
- What happens to my state if a stateful node goes down?
- How do I guarantee that my state is modified safely? Consistent histories for state, in other words.
We can address, at a high level, all of these questions using a tool built into Akka.Cluster: consistent hash routers and Cluster.Sharding.
Clustered Routers
The primary tool used for routing messages in Akka.Cluster is a “clustered” router - this is your typical Akka.NET router, but it has the ability to subscribe to the cluster’s gossip messages and dynamically update its routing table in accordance with which members in the cluster are available to do work.
So imagine we’re going to build a four-node cluster:
On node 1 we declare the following router syntax using HOCON:
/myRouter {
router = broadcast-group # routing strategy
routees.paths = ["/user/foo"] # path of routee on each node
cluster {
enabled = on
allow-local-routees = off
}
}
This router will allow any actor on node 1 to send a message to any actors living at the path /user/foo on any other node in the cluster except Node 1. If we want to include node 1 in its own router, we’d need to set allow-local-routees = on.
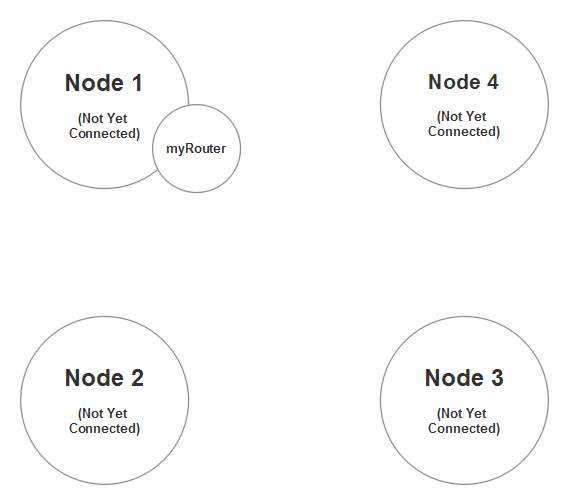
The router currently has no routees and can’t really do much until Node 1 forms a cluster with some of the other nodes on this diagram.
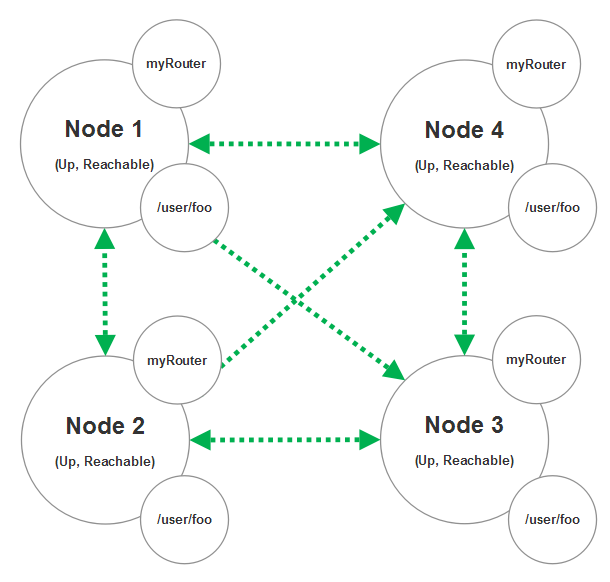
So we start up nodes 1, 2, and 4 and they form a 3-node cluster (node 3 still hasn’t attempted to join the cluster yet.)
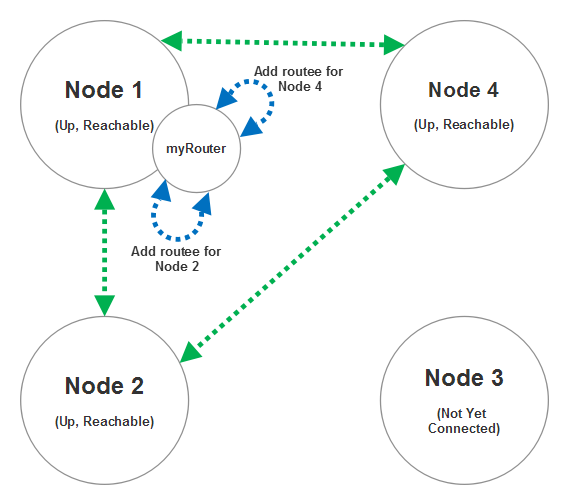
As nodes 2 and 4 join the cluster with node 1, the myRouter we declared will add routee entrees for /user/foo on nodes 2 and 4 once we receive gossip messages indicating that those two nodes have successfully joined the cluster and are fully reachable (can be contacted by all nodes in the cluster.)
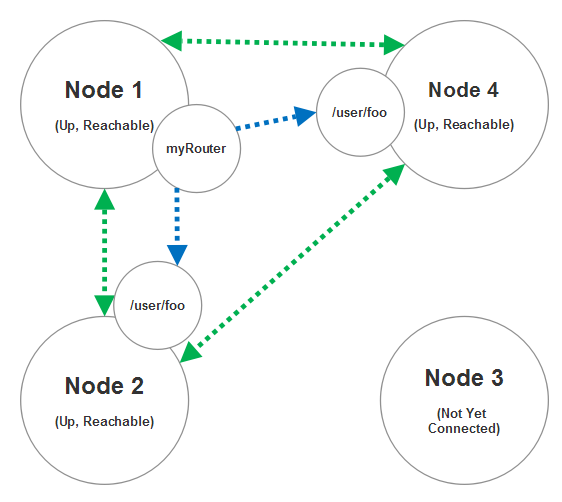
Now at this stage node 3 joins the cluster then another routee for node 3 will automatically be added to myRouter.
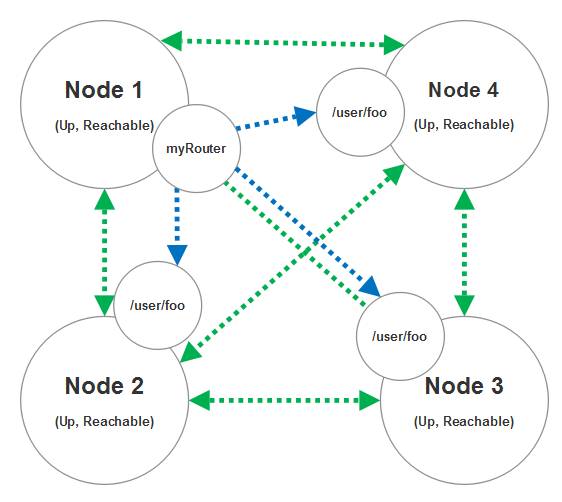
And just so we cover all of the use cases here, imagine that node 4 becomes temporarily unreachable as a result of a network partition of some sort. In this scenario the routee for node 4 will be removed from the routing table of myRouter and we won’t attempt to deliver any messages to node 4 until it becomes reachable again. A node can become reachable again if the network partition heals and the other nodes can connect to node 4 again.
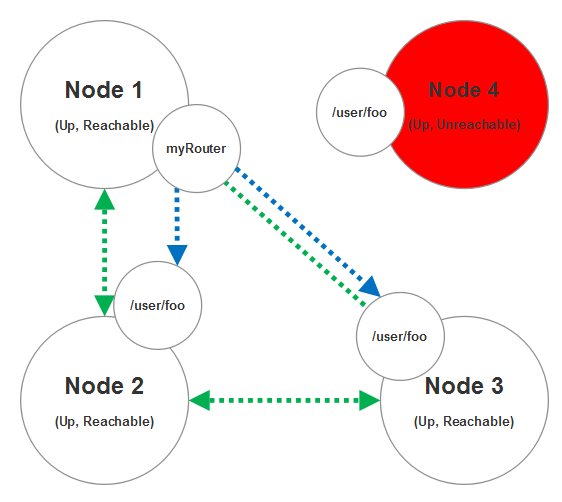
This is the basics for how a cluster router works - it’s a programmable router that expands and contracts its routing table based on which nodes are currently available in the cluster. Clustered routers work with virtually any routing strategy you can use with local actors in Akka.NET like broadcast, random, round robin, scatter gather, and so forth.
When it comes to distributing messages that change state, there’s a specific routing strategy that is perfectly suited to this: consistent hash routing.
Consistent Hash Routing and Distributions
Routing strategies like round robin and random are really designed for load-balancing work across actors that are typically stateless. What separates consistent hash routing from the other strategies is that it’s really the only strategy designed for distributing state equally across a number of actors and they guarantee that all messages corresponding to the same entity are routed to the same actor every time.
This is because of how consistent hashing functions like MD5 and Murmur3 work, which we’ll review in a moment.
In Akka.NET, in order to use a consistent hashing router you must either:
- Have all messages sent through that router implement the
IConsistentHashable; - Wrap all messages sent through the router inside a
ConsistentHashableEnvelope; or - Declare your consistent hash router programmatically and manually pass in a hashing function which covers all possible inputs. Here’s an example.
All of these mechanisms fulfill the same role - to extract a key that can be used as input in our consistent hashing function. Any message sent to a consistent hash router without one of these mechanisms in place isn’t guaranteed to be delivered at all.
What makes a hash function consistent?
A hash function can be described simply using the following notation:
hash(x) -> y
Where x is an input value, byte[] in this instance and y is a 64 bit long integer.
What makes a consistent hash function “consistent” are the following two properties:
- For a constant value of
xyou will have a constant value ofyacross all nodes in a network and - In a network of
nnodes all possible values ofy(we’ll call that valueH) can be evenly subdivided acrossnpartitions. If the value fornshould change, onlyH\nentries will be partitioned to a different node than the one they were on before.
These two properties make consistent hashing ideal for distributed caches, databases, and other distributed stateful applications because it means that for a given hash input of x, all nodes in a network can both independently route messages with that same hash key to the correct destination node without having to coordinate with each other on every message send.
They only need to coordinate when the network itself changes, which is what the clustered routers in the previous section are doing.
It’s easier to explain this with a visual - imagine we’re going to treat the entire hash range of a consistent hash router as a big ring or pie.
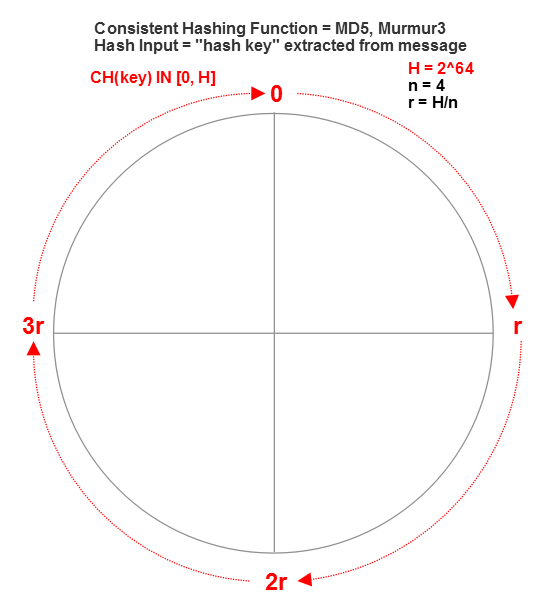
Given that a long integer is the output of our hash function we will have 2^64 possible different hash values (y) for all possible inputs of x. We can plot all of those hash values in a contiguous, clockwise ring (y=0,1,2… etc.) This is known as a “hash ring.”
Consistent hash distributions
Here’s where the distributed part comes in; suppose we’re going to have four nodes in our cluster who are each going to own a portion of that hash range. In that case we just divide our ring of 2^64 values by four and we get four equally sized (2^64/4) slices.
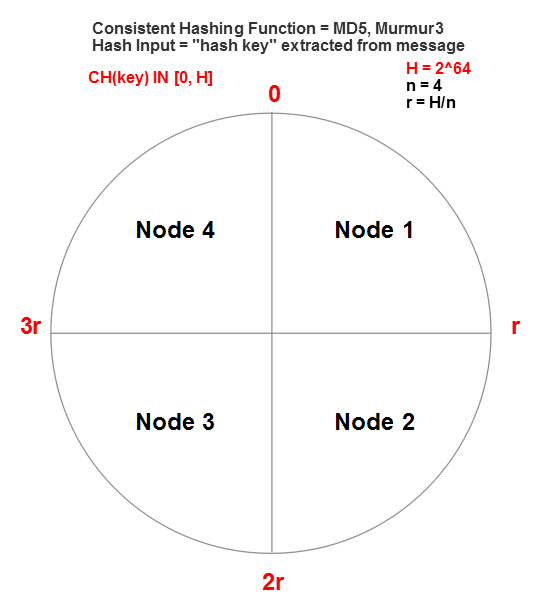
This is known as “ring-based partitioning,” which is a fancy way of saying “dividing the ring into equal sized slices.”
A consistent hash router inside Akka.NET represents its routing table this way. It maintaints a sorted dictionary of each starting position on the hash ring and which node corresponds with it.
So when we send a message to a consistent hash router, it applies the hash function to the hash key extracted from the message to determine which routee (an ActorSelection or an IActorRef) gets the message.
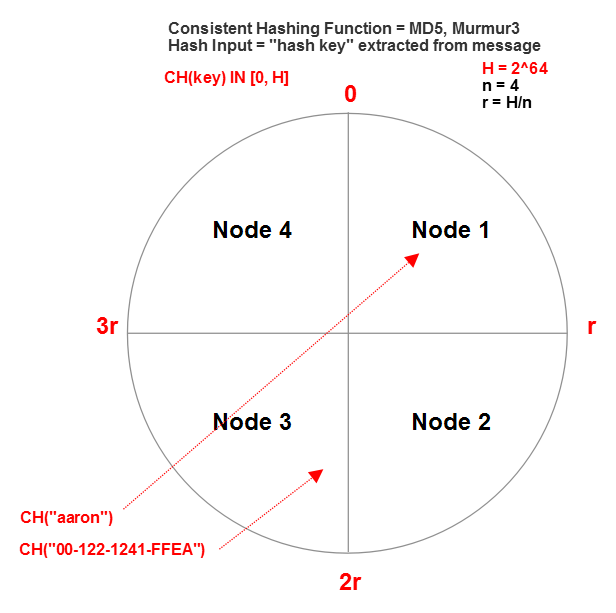
Every time the consistent hash router extracts the hash key “aaron” from its message, it will compute the exact same hash value and use that to route all messages that have the key “aaron” to the same actor every time.
Consistent hash routers in a cluster
Here’s what makes consistent hash routers so special - imagine if every single node in our previous 4-node Akka.NET cluster was running a hash router with the following configuration:
/myRouter {
router = consistent-hashing-group # routing strategy
routees.paths = ["/user/foo"] # path of routee on each node
cluster {
enabled = on
allow-local-routees = on #allowing local routees
}
}
This means that all four nodes are going to have a consistent hash router that can reach any node in the cluster, including itself.
Imagine if three nodes all receives a message that has a hash key value of “aaron;” all three of these nodes will correctly route their message to the same /user/foo instance inside the cluster, on node 3 in this instance.
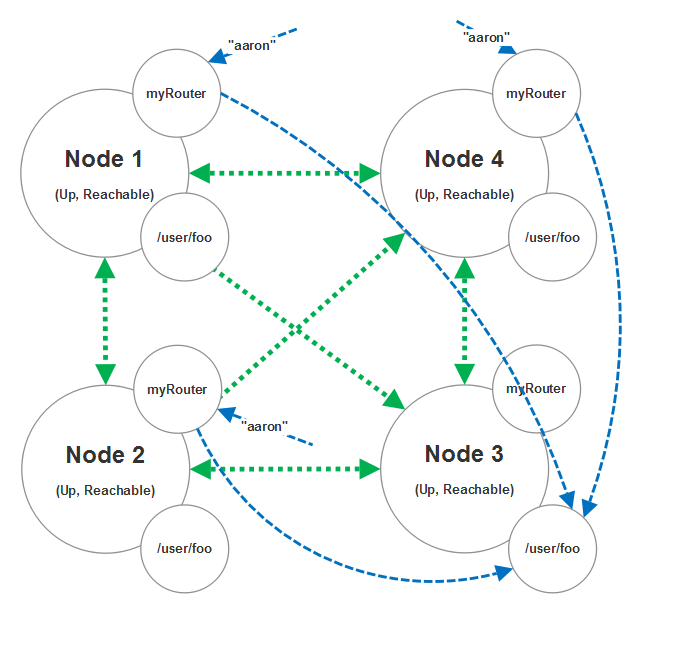
The reason why this works is because the hash table is identical on every instance of this router.
Repartitioning the hash range
Now what happens if a new node joins the cluster or an old node becomes unreachable? As we saw in the earlier section on how clustered routers behave we know that each router instance is going to have to adjust their routing table.
In the case of a consistent hashing router it means that H/n messages that were previously routed to one node will now be routed to a new node instead.
This “partition handoff” from one node to another can have an impact on the consistency with which your state is read and written during the handoff period. Akka.Cluster doesn’t provide a built-in way to manage this but Akka.Cluster.Sharding does provide some and it uses a similar state distribution method internally.
N.B. Parition handoffs is a rather nuanced area of discussion when it comes to distributed systems design and I can’t do it full justice here.
Designing your consistent hash routees correctly
Now for an important question: how do I guarantee that my state is managed safely?
The simplest and best practice for this is to guarantee that exactly one actor throughout the entire cluster is responsible for each stateful entity because then the actor model’s “one at a time” message processing and ordering guarantees does the work of linearizing all reads / writes against that entity in the form of messages.
The easiest way to see to that is to have the routee under your consistent hash router implement the “Child-per-Entity” pattern - which means that for each message arriving at the routee it checks to see if there is already a child actor corresponding to the entity for which that message belongs.
If a child already exists, we route the message to it. If a child doesn’t exist, we create it and then route the message to it.
Again though, Akka.Cluster.Sharding does much of this for you out of the box already so even though that module is currently in beta it might be worth considering taking a look at that.
I hope you’ve found this helpful and if you’d like to learn more about these sorts of subjects, we strongly encourage that you take our Akka.Cluster Webinar Training Course!
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.

Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS