// BLOG
Meet the Top Akka.NET Design Patterns
Just the other day, I saw this tweet and knew this post was long overdue:
Is there any list of actor model design patterns ? @AkkaDotNET
— Laurent Lepinay (@foobarcode) June 24, 2015Quite understandably, people want to know what the design patterns in Akka.NET are! There are quite a few-our team has cataloged 30+ across various areas of the framework so far-but there is also that rarefied set of patterns that show up again, and again, and again.
These patterns cover four broad categories:
- Actor Composition
- Messaging
- Reliability
- Testability
Let’s get going.
Actor Composition Patterns
“Actor Composition” patterns are used to create groups of interrelated actors in order to accomplish specific goals. Patterns of this type help you think about how many actors you need, and how to structure the relationships between them in your hierarchy.
These patterns are aimed at allowing you to use Akka.NET’s supervision hierarchy to your advantage in order to achieve maximum reliability and transparency when working with actors. They will also make your architecture more intuitive.
Composition Pattern: Child-Per-Entity
The Child-per-Entity pattern occurs whenever some /parent actor is responsible for a domain of entities and elects to represent each entity as its own actor. The parent maintains a mapping to know which child actor corresponds with which domain entity. The /parent can then lookup/create/kill child actors as domain object enter or leave its going concerns.
Here’s what the Child-per-Entity pattern looks like:
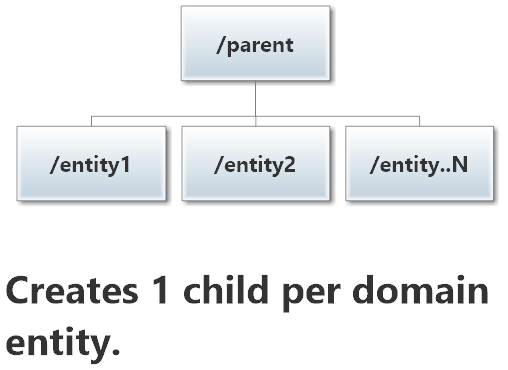
Use Cases
What are some common use cases where the Child-per-Entity pattern shows up?
The Child-per-Entity pattern is most useful in scenarios where each represented entity closely resembles the real-time state of another concurrent entity. Some common examples are:
- Stream processing, scraping, aggregation / accumulation: these are all cases where some large job needs to be broken down into its component parts for processing/counting/etc. Each of those components becomes a child.
- Real-time user or device activity: in this case, each user or device exists as a child of the parent.
- App authentication sessions: each session lives as a child of, say, a
SessionManagerActor.
Benefits
What benefits does the Child-per-Entity pattern offer you? Here are my top three reasons to use it:
- 1:1 correlation between domain model and actor model, which simplifies many stateful programming scenarios.
- Reliable stateful routing in clustered and network environments - every domain entity can map to one and only one destination actor.
- Simplified/smaller code footprint. Rather than write code to manage N number of entities at once, write an actor who manages exactly one instance of the entity and deploy N of them.
Example
Unless otherwise noted, all code samples in this post are from our Cluster.WebCrawler sample, which is available on GitHub in our professional Akka.NET code samples repo (and is also a great intro to Akka.Cluster). This is a scalable web crawler that downloads and parses a website, discovering new pages as it goes and crawling them too.
This is a perfect fit for the Child-per-Entity pattern! This is a case where our domain–CrawlJobs in this case–maps nicely to a set of child actors. Here is what the pattern looks like in code:
// WebCrawler.TrackingService.Actors.ApiMaster
// ... in SearchingForJob() ...
Receive<JobNotFound>(notFound =>
{
if (notFound.Key.Equals(JobToStart.Job))
{
OutstandingAcknowledgements--;
if (OutstandingAcknowledgements <= 0)
{
//need to create the job now
var crawlMaster = Context.ActorOf(Props.Create(() => new CrawlMaster(JobToStart.Job)),
JobToStart.Job.Root.ToActorName());
crawlMaster.Tell(JobToStart);
ApiBroadcaster.Tell(new JobFound(JobToStart.Job, crawlMaster));
}
}
});
In some code not shown (see full file here), the ApiMaster is checking to make sure there is no existing CrawlJob for the provided domain. Assuming there is not, we will receive the JobNotFound message in the handler above. At this point, ApiMaster is clear to begin crawling the domain. To do so, it creates a CrawlMaster actor as its child. The job of the CrawlMaster is to manage the entire process / sub-hierarchy of actors below it in order to get the domain its responsible for crawled.
One thing you may notice is that this is very little code to represent a potentially unbounded number of children. This is one of the beautiful things about the actor model–“cloneability.” Because the ActorSystem can create many parallel instances of the same actor definition, we get a small code footprint in terms of actors to define AND scale-out of those actors automatically. Sweet.
On to the next one!
Composition Pattern: Fan Out
Imagine that you need to use a network of servers to scale-out your processing power (as with Cluster.WebCrawler). What if you need to be able to deploy large hierarchies of actors onto remote machines to do the work, or if you need to have a large pool of actors carry out a long-running task. How would you model the interactions between the actors on these various machines? Stop and think about that for a minute.
Well,this is exactly what the Fan-out Pattern can help us do easily!
The Fan-out Pattern occurs when entire hierarchies of actors need to be able to be deployed in order to fulfill a task. Rather than have one actor responsible for creating a large number of children (as in the Child-per-Entity pattern), what we can do instead is have a single actor be deployed remotely. This actor is then responsible for creating a small number of children who create grandchildren and so on recursively.
Essentially, we deploy an actor who will unpack an entire processing hierarchy below them to do the real work. Here’s what that looks like:
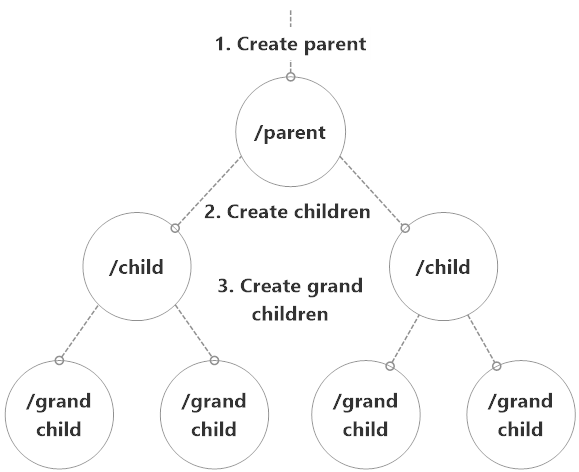
Use Cases
When is the Fan-Out Pattern the right tool for the job? I can think of two cases:
- You have parallel work loads that can be distributed across multiple machines, and/or…
- You want to refactor a complex operation into a series of small operations.
As we’ve discussed, parallelizing work is something the actor model is brilliant at. But the latter is less obvious–refactoring?
As we discussed in our primer on Akka.NET actor hierarchies, having actors live in a “family tree” is great for fault tolerance and reliability. BUT it’s also great for atomizing work–that is, taking a large stream of data and breaking it down recursively until it’s just tiny little pieces of work done by a single actor. That’s what we mean by “refactoring a complex operation.”
Benefits
The Fan-Out Pattern gives you three key benefits:
- Adds layers of local decision making and supervision away from the original parent. This reduces the likelihood of a large rolling restart taking down large parts of the system, while also…
- Makes it possible to deploy hierarchies of actors onto remote or clustered actor systems with a single command. When you’re working across multiple machines, it is much simpler to deploy one actor over the network and have it unpack its own hierarchy, than it is to try to create, remote deploy, and manage that entire hierarchy directly.
- Simplifies the design of actors at every level. The Fan-Out pattern is a great way to break up areas of responsibilities into small, discrete parts.
Example
Let’s see what that looks like in some code:
// WebCrawler.TrackingService.Actors.IO.CrawlMaster
private void BecomeReady()
{
if (Context.Child(CoordinatorRouterName).Equals(ActorRefs.Nobody))
{
// remote deploy DownloadCoordinator
CoordinatorRouter =
Context.ActorOf(
Props.Create(() => new DownloadCoordinator(Job, Self, DownloadTracker, 50))
.WithRouter(FromConfig.Instance), CoordinatorRouterName);
}
else //in the event of a restart
{
CoordinatorRouter = Context.Child(CoordinatorRouterName);
}
// ... edited for brevity ...
}
(See the full file for this code sample here.)
What’s going on here is that the CrawlMaster remotely deploys a pool of DownloadCoordinators. Each of these DownloadCoordinator actors then “fans out” or unpacks its own worker hierarchy of ParseWorker and DownloadWorker actors beneath it, to actually do the work.
This is what the Fan-Out Pattern looks like the context of this specific sample, where a work hierarchy is being remote deployed:
![]()
This is the essence of the Fan-Out pattern, and demonstrates the benefit of being able to remote deploy just one actor (DownloadCoordinator) to build a remote worker hierarchy. This is much easier than remote deploying and managing all the actors of that hierarchy from the deploying actor.
Why Use Akka.NET?
What are the compelling reasons for using Akka.NET? What sorts of problems can it solve for you and your company?
Click here to subscribe to our newsletter for more Akka.NET architecture insights.
Messaging Patterns
One of the crucial concepts to get right early on is thinking through how actors will communicate with each other. There’s only a small number of messaging patterns, but identifying the right pattern for each situation makes the difference between predictable, clear behavior and nonsense.
Let’s cover the workhorse of all messaging patterns: Pub-Sub.
Messaging Pattern: Pub-Sub
Publish-Subscribe (pub-sub) is very simple with Akka.NET and it’s a natural extension of the reactive programming style inherent to actors.
Conceptually, pub-sub is the same with actors as it is generally: a subscriber actor notifies a publisher that it would like to periodically receive updates on specific topics/types of messages when the publisher becomes aware of them. The publisher keeps track of its subscribers and follows through on its promise to push messages to them when it has updates on topics of interest to subscribers. Subscribers also have the option of unsubscribing from publishers at any time.
Here’s a quick visualization of what pub-sub looks like with actors:
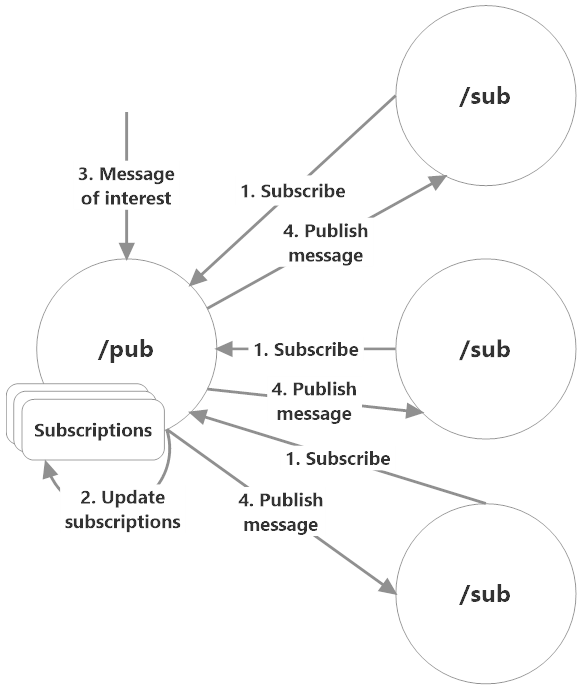
Use Cases
Pub-sub is used in stateful systems that deal in high frequencies and variety of messages, especially event-driven systems. But honestly, Pub-Sub is a staple of any distributed message-based system and you’ll find yourself using it all the time. This is the true workhorse of messaging, especially in remote/clustering contexts.
Benefits
So, what does pub-sub give you? There are two key benefits:
- Consolidated logic: The biggest benefit of pub-sub is that is consolidates all of the logic in topic subscription and publication into one place, keeping your the code footprint of your other actors (the subscribers) small and focused.
- Latency reduction: this benefit kicks in once you have actually distributed your application and are using Akka.Remote / Akka.Cluster. In a distributed environment like this, latency is a real issue that must be managed. There are many ways to deal with this, but one of the go-to options is pub-sub. Let’s explore this a bit more.
That’s right: in a distributed architecture, pub-sub is a latency reduction mechanism! How’s that work?
With pub-sub, all of the actors who need to do actual work into a position where they can just sit back and wait for messages to arrive. In a pub-sub environment no actor really needs to “seek out” work - work finds them instead!
This is because, once you’re using Akka.Remote and/or Akka.Cluster, the ActorSystems on each of your collaborating machines will be directly connected to each other via Helios socket server.
So what? Well, this means that up-to-date information will be pushed to subscribed actors as fast as the network and application can possibly allow. Your subscribers can now be designed under the assumption that they always have the most recent data for their subscriptions. Latency isn’t even a concern for us because that’s information we don’t have to fetch over the network. The overhead and latency of request/response is not there. Instead, the information is pushed into us as it is updated, so by the time our subscribers need the information to satisfy an operation, they already have the data.
This is a massive benefit of reactive programming: your subscriber actors just need to react to changes in state as they happen rather than having to go and actually request state from somewhere else.
Example
How do you implement pub-sub in Akka.NET? It’s trivially easy: have your publisher keep a HashSet of subscribers and Tell messages to them. Here’s an example, again from our trusty CrawlMaster, who uses pub-sub to ensure that clients which start long-running crawl jobs automatically receive updates about those jobs:
// WebCrawler.TrackingService.Actors.IO.CrawlMaster
public class CrawlMaster : ReceiveActor, IWithUnboundedStash
{
// ... edited for brevity
/// <summary>
/// All of the actors subscribed to CrawlJob updates.
/// </summary>
protected HashSet<IActorRef> Subscribers = new HashSet<IActorRef>();
private void Started()
{
Receive<StartJob>(start =>
{
//treat the additional StartJob like a subscription
if (start.Job.Equals(Job))
Subscribers.Add(start.Requestor);
});
// add new subscriber
Receive<SubscribeToJob>(subscribe =>
{
if (subscribe.Job.Equals(Job))
Subscribers.Add(subscribe.Subscriber);
});
// remove subscriber
Receive<UnsubscribeFromJob>(unsubscribe =>
{
if (unsubscribe.Job.Equals(Job))
Subscribers.Remove(unsubscribe.Subscriber);
});
// publish job status to subscribers
Receive<CrawlJobStats>(stats =>
{
TotalStats = TotalStats.Merge(stats);
PublishJobStatus();
});
}
// push latest status into subscribers
private void PublishJobStatus()
{
foreach (var sub in Subscribers)
sub.Tell(RunningStatus);
}
}
(See the full file for this code sample here.)
As you can see, the CrawlMaster just keeps a simple HashSet of its subscribers and pushes the latest status into them.
Reliability Patterns
One of the greatest benefits of using the actor model is its ability to form self-healing systems, even over the network. This is accomplished by taking advantage of the supervision and restart capabilities built into the framework!
And the go-to pattern here, to insure that failures are contained and don’t bubble up through the system? Meet the Character Actor.
Reliability Pattern: Character Actor
The name “Character Actor Pattern” was coined by Scott Hanselman during an interview with Aaron Stannard about Akka.NET, and it refers to a specific actor composition pattern that’s used to ensure system reliability by way of disposable children.
The Character Actor Pattern is used when an application has some risky but critical operation to execute, but needs to protect critical state contained in other actors and ensure that there are no negative side effects.
It’s often cheaper, faster, and more reliable to simply delegate these risky operations to a purpose-built, but trivially disposable actor whose only job is to carry out the operation successfully or die trying.
These brave, disposable actors are Character Actors.
Character actors can be temporary or long-running actors, but typically they’re designed to carry out only one specific type of risky operation. Often times character actors can be re-used throughout an application, belonging to many different types of parents. For example, you may have a utility character actor that handles making external network requests, and is then used by parent actors throughout your application for their own purposes.
By the way, this pattern has a much less fun name: it’s also called the “Error kernel pattern,” which is the name given to it in Erlang.
Here’s a diagram of the Character Actor Pattern:
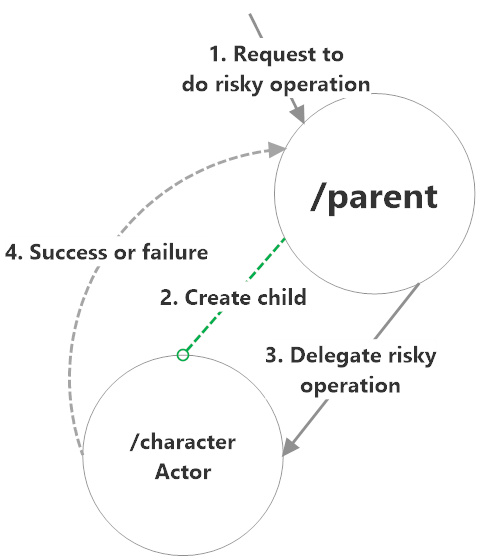
Use Cases
The Character Actor pattern is broadly applicable. Use it any time you need to do something risky such as network calls, file I/O, parsing malformed content, and so on. Any of these operations is a good candidate for a character actor.Character actors are most effective when used to provide protection and fault isolation to some other important type of actor, typically one containing some important state.
Benefits
There are three key benefits to using the Character Actor Pattern:
- Insulates stateful and critical actors from failures and risky operations;
- Makes it easy to cleanly introduce retry / backoff / undo semantics specific to each type of risky operation: since you have a character actor specific to each risky task, you have a well-defined place to put retry handling and related operations. These are specific to the task the Character Actor was created for and don’t need to be shared with the rest of your actors, meaning that the pattern…
- Reduces code: by letting the
SupervisionStrategyand actor lifecycle do most of the heavy lifting, you don’t need all sorts of exception handling code in your parent actors. Just let it crash, baby.
Example
The WebCrawler is chock-full of Character Actors! This is because it handles numerous different dangerous operations, ranging from making network calls to downloading and parsing (often malformed) HTML.
Let’s have a look at one, the ParseWorker responsible for using the HTML Agility Pack to parse the content that has been downloaded:
// WebCrawler.Shared.IO.ParseWorker
// ... edited for brevity ...
private void Parsing()
{
Receive<DownloadWorker.DownloadHtmlResult>(downloadHtmlResult =>
{
var requestedUrls = new List<CrawlDocument>();
var htmlString = downloadHtmlResult.Content;
var doc = new HtmlDocument();
doc.LoadHtml(htmlString);
//find all of the IMG tags via XPATH
var imgs = doc.DocumentNode.SelectNodes("//img[@src]");
//find all of the A...HREF tags via XPATH
var links = doc.DocumentNode.SelectNodes("//a[@href]");
/* PROCESS ALL IMAGES */
if (imgs != null)
{
var validImgUris =
imgs.Select(x => x.Attributes["src"].Value)
.Where(CanMakeAbsoluteUri)
.Select(ToAsboluteUri)
.Where(AbsoluteUriIsInDomain)
.Select(y => new CrawlDocument(y, true));
requestedUrls = requestedUrls.Concat(validImgUris).ToList();
}
/* PROCESS ALL LINKS */
if (links != null)
{
var validLinkUris =
links.Select(x => x.Attributes["href"].Value)
.Where(CanMakeAbsoluteUri)
.Select(ToAsboluteUri)
.Where(AbsoluteUriIsInDomain)
.Select(y => new CrawlDocument(y, false));
requestedUrls = requestedUrls.Concat(validLinkUris).ToList();
}
CoordinatorActor.Tell(new CheckDocuments(requestedUrls, DownloadActor, TimeSpan.FromMilliseconds(requestedUrls.Count * 5000)), Self);
});
}
(See the full file for this code sample here.)
After a little bit of setup, the ParseWorker has one job: parse the downloaded content. It loops over the downloaded content, pulls out links and images, and sends them back to its coordinator parent for further processing. All the logic related to parsing error handling and checking is entirely contained in ParseWorker, keeping that logic out of the rest of the system.
Testability Patterns
One of the keys to building successful large-scale applications on top of Akka.NET is learning how to leverage the Akka.TestKit and design actors who are capable of using it. (We’ll be releasing a primer on Akka.TestKit very soon, by the way. :)
Let’s zoom in on one specific pattern that you can use to design individual actor classes that can be tested easily using Akka.TestKit: the Reply-to-Sender Pattern.
Testability Pattern: Reply-to-Sender
Reply-to-Sender is one of those patterns that we use so naturally that we oftentimes don’t think about the benefits, but we’re going to explicitly spell them out here.
The Reply-to-Sender Pattern occurs when an actor (MyActor) is programmed to reply directly to its Sender field on receiving messages which merit a response, rather than replying back to a fixed ActorSelection, to Context.Parent, or generally to any other field.
This pattern makes it very easy to intercept message responses MyActor from the outside, by simply sending the message whose response we need to test from an actor capable of intercepting and asserting the message (hint: the TestActor).
This is an incredibly simple pattern, as you can see:
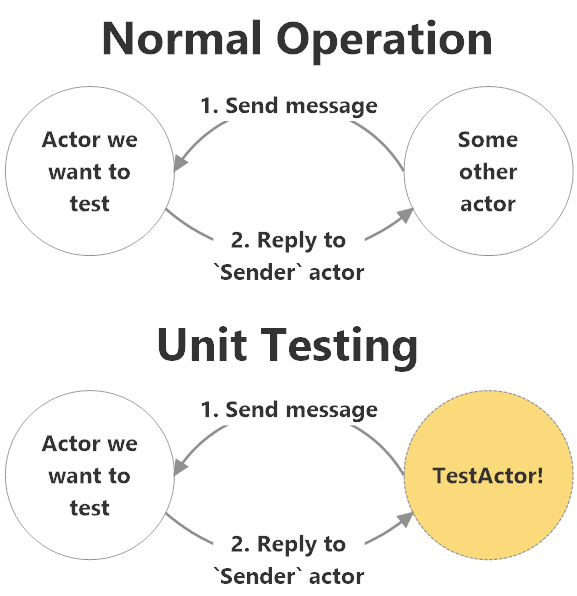
Use Cases
The Reply-to-Sender pattern is globally applicable for testing. It should be used in any instance where you want to be able to explicitly test the message replies from a specific actor.
Note: yes, Reply-to-Sender will make your actors easier to test, but it will ALSO make it easy to scale your application out over the network without rewriting your code! This comes from the wonderful combination of Akka.Remote, Akka.Cluster, and what’s known as “location transparency”. Learn more about location transparency and how to put it to work for you here.
Benefits
The benefit of the Reply-to-Sender pattern is how easy it becomes to intercept response messages from an actor you want to test. All you have to do is send the messages you want to test from an actor capable of intercepting the replies and making them accessible for test assertions.
Guess what? The built-in Akka.TestKit TestActor does this automatically!
Let’s see how.
Example
In this example, imagine we have an actor called IdentityStoreActor who is responsible for approving writes to the database to create users.
We’ll have IdentityStoreActor reply to Sender, which will set us up to easily test the behavior of this actor:
public IdentityStoreActor(Func<IUserRepository> userRepoFactory)
{
_userRepoFactory = userRepoFactory;
Receive<CheckForAvailableUserName>(name =>
{
var repo = _userRepoFactory();
var sender = Sender;
var result = repo.UserNameIsAvailable(name.DisplayName).ContinueWith(tr =>
{
repo.Dispose();
if (tr.Result.Payload == true)
{
return new UserNameAvailablity(name.DisplayName, true);
}
return new UserNameAvailablity(name.DisplayName, false);
}).PipeTo(sender); // REPLY TO SENDER
});
//other receive methods
}
Let’s say that a write is allowed if the username requested is available, and the write is refused when the requested username is taken.
We want to be able to inspect what this actor returns when we send in different user parameters–does it allow the user to be created when the username is already taken? Does it allow the write when the username is available? And so on.
Given that IdentityStoreActor will always reply back to the sender of the actor who sent it a CheckForAvailableUserName message, we can use this information to test the behavior from the outside by inspecting the message IdentityStoreActor sends in response to different types of CheckForAvailableUserName messages. Like this:
[Test]
public void IdentityStoreActor_should_not_find_nonexistent_user()
{
var identityActor = Sys.ActorOf(Props.Create(() => new IdentityStoreActor(_userRepoFunction)));
// generate a random username request
var userNameRequest = _checkUserNameFunc();
identityActor.Tell(userNameRequest); // TestActor is the implicit sender
// if true, ExpectMsg will assign the value checked (IsAvailable here) to the local var;
// otherwise it will return/assign false
var available = ExpectMsg<IdentityStoreActor.UserNameAvailablity>().IsAvailable;
// this random username should be available
Assert.True(available);
}
As you can see, Reply-to-Sender works in conjunction with the Akka.TestKit.TestActor, which automatically acts as the implicit sender of all messages sent to any of your actors during unit tests.
You can also see that this actor used the PipeTo pattern to handle async methods, which is the approach we recommend.
Remember: Reply-to-Sender will make your actors easier to test AND will make it easier to scale your ActorSystem out over the network using Akka.Remote and Akka.Cluster.
Let’s Go Deeper
These “fantastic five” patterns are just a few of the techniques that we teach in our Design Patterns course, which you should check out. That course goes deep on patterns in all these categories, when to use which, how to model a system from the ground up, and much more!
Do all these patterns and examples make sense? Can you see some places you can apply them in your projects? Leave a note below and let me know.
###
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.
Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS