Oct 24, 2025
Akka.NET + Kubernetes: Everything You Need to Know
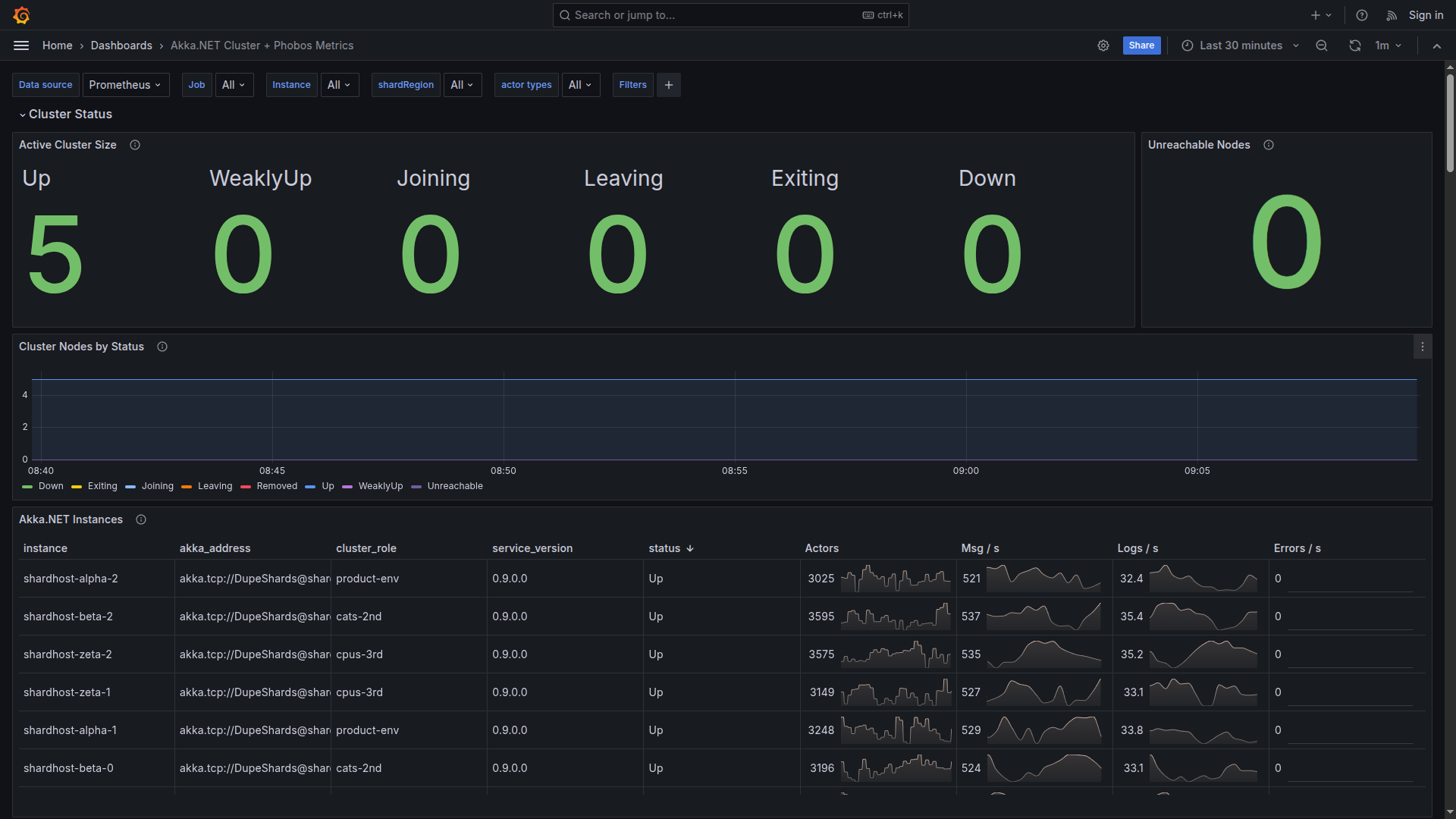
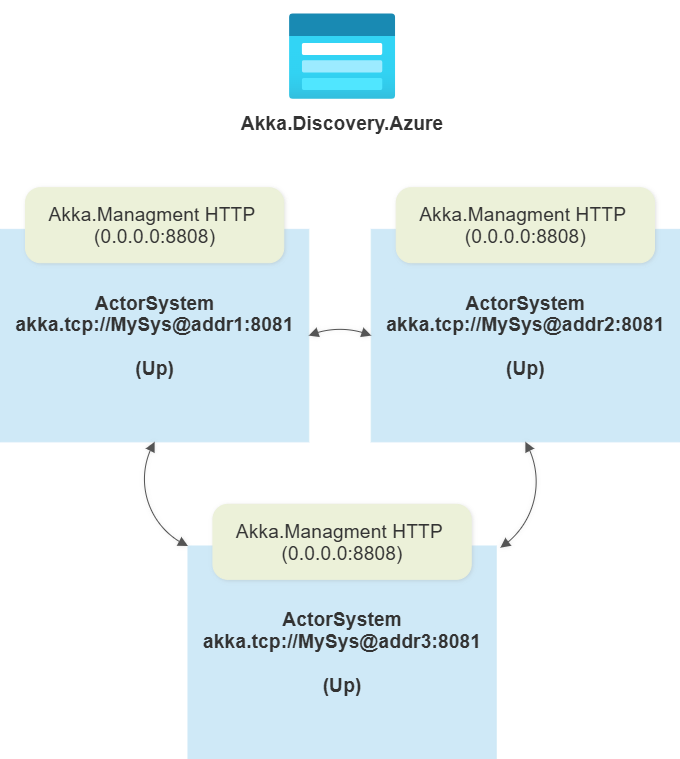
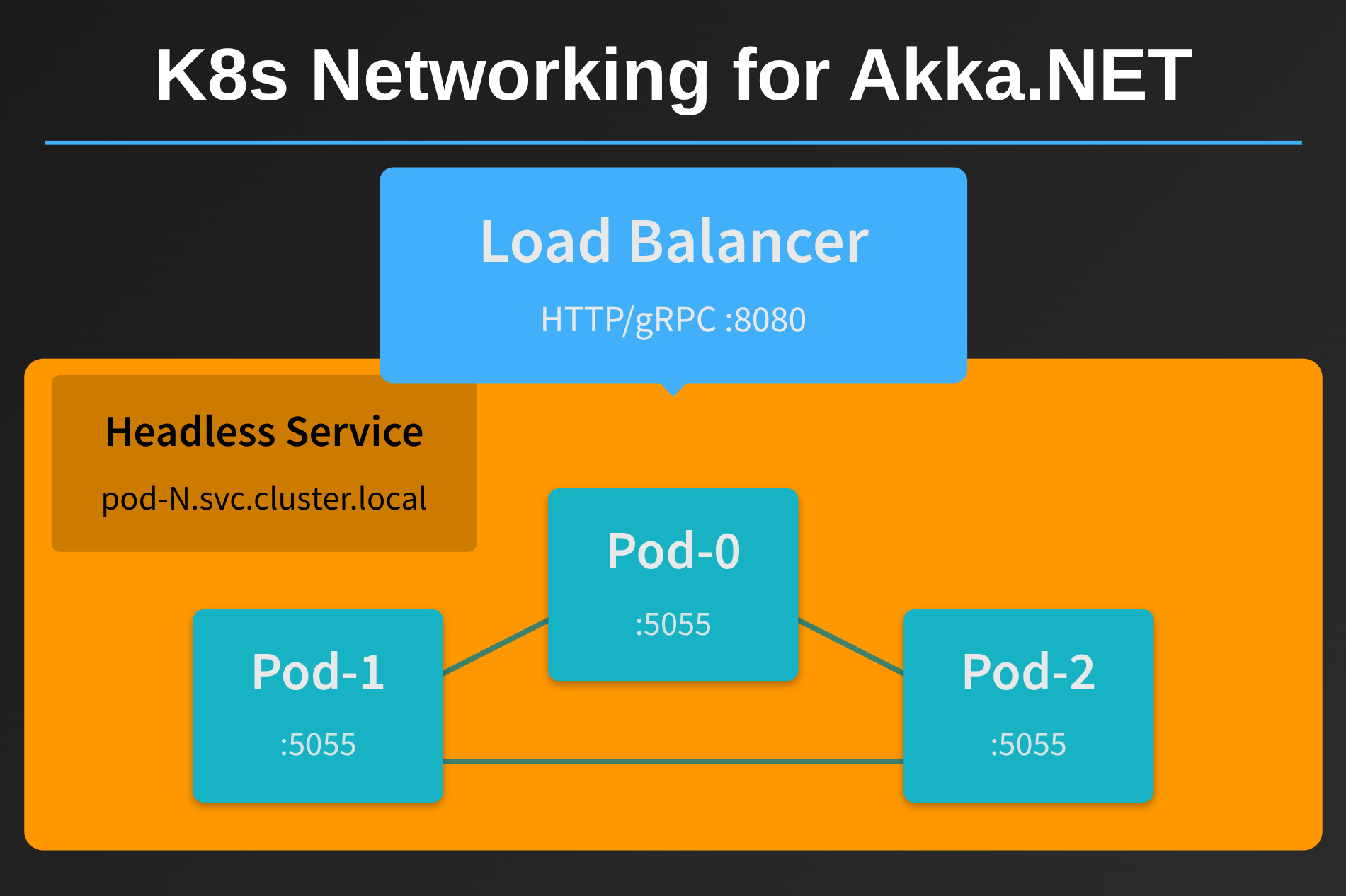
Running Akka.NET in Kubernetes can feel like a daunting task if you’re doing it for the first time. Between StatefulSets, Deployments, RBAC permissions, health checks, and graceful shutdowns, there are a lot of moving parts to get right. But here’s...