Scaling Akka.Persistence.Query to 100k+ Concurrent Queries for Large-Scale CQRS
How we solved an acute event-driven scaling problem for users in Akka.NET v1.5.
One of our major engineering milestones for Akka.NET v1.5 (ships on February 28th, 2023):
Make CQRS a priority in Akka.Persistence
This blog post is about an interesting engineering challenge we had to solve to accomplish this for Akka.NET v1.5: supporting hundreds of thousands or even millions of concurrent Akka.Persistence.Query projection queries all targeting a single database.
Fundamentally - there are many different facets of Akka.Persistence and Akka.Persistence.Query scalability that needed solving, but this post fixates on an acute problem users have in production with Akka.Persistence.Query today: large numbers of concurrent queries absolutely melting down production-grade database deployments.
Users reported APQ knocking their databases out with as few as 3-4 thousand streaming queries running at rates of once every 1-3 seconds - with several nodes all running similar workloads (so in aggregate, perhaps closer 10k+ queries per second.)
Beginning in Akka.NET v1.5, we have eliminated this issue and have explicitly tested it up to 100,000 queries per second targeting a dinky SQL Server 2019 database running inside a Docker container. We suspect our design can scale up to support 10s of millions of concurrent queries (although for reasons I get into later, end-users should use different approach.)
Here’s what we did.
Background
Akka.Persistence makes it trivially easy for actors to become re-entrant across crashes, re-balancing onto new processes, and generally speaking making actor state durable. It uses an event-sourcing model that takes Akka.NET event types, serializes them into a binary representation, and stores them into simple key/value pair models on top of any supported database.
Today, Akka.Persistence supports many different database implementations - Azure, SQL Server, Postgres, Oracle, MySQL, MongoDb, Redis, EventStore, and others. Akka.Persistence uses a standardized read/write model:
Journal- all of the events that were produced by an actor processing message are event-sourced into the journal.SnapshotStore- not totally relevant to this post, but since the question may come up: the snapshot store is an optimization to help speed up recovery time for persistent actors. It allows actors to save a point-in-time representation of their state and that’s used as the starting point for actor recovery.
The Journal is the data structure we’re really interested in for this post, as this is the source Akka.Persistence.Query accesses in order to help create data-driven projections for end users.
The Journal is implemented as a single table, typically, with the following properties:
- All events belong to an entity with a globally unique
string PersistentId- determined by the end-user’s code; - All events are assigned a monotonically increasing sequence number (
SeqNo) to version the state and indicate its age; - All events are indexed by the tuple of
(PersistentId, SeqNo)on every platform; - All events include additional metadata: a unique
Orderingvalue (either a time-basedGuidor a Db-assigned timestamp), the serializerIdandManifestused to identify the payload in Akka.NET’s serialization system, and finally thebyte[]payload itself; and lastly - Each entry in the
Journalmay also include an arbitrary number of tags - these act secondary indicies for aggregating events across multiple independent entities.
Akka.Persistence is designed to make actor operations durable with a minimal amount of fuss - it is not designed to make the data human-readable or accessible for arbitrary reporting or business intelligence queries. In order to support those requirements using Akka.Persistence users create streaming “projection queries” using Akka.Persistence.Query to transform journaled events into separate read-only views of the data that are optimized for BI, reporting, analytics, human readability, or whatever the peritnent requirements are.
How Akka.Persistence.Query Works
Akka.Persistence.Query is built on top of Akka.Streams - and it’s designed to query events written by persistent actors into the Journal and make them available for projections or any other arbitrary use case.
Here’s a simple example of an Akka.Persistence.Query:
SqlReadJournal query = Context.System.ReadJournalFor<SqlReadJournal>(SqlReadJournal.Identifier);
query.EventsByPersistenceId(_targetPersistentId, startSeqNo, long.MaxValue)
.To(Sink.ActorRef<EventEnvelope>(Self, Done.Instance, exception => new Status.Failure(exception)))
.Run(_materializer);
This query will deliver a stream of EventEnvelopes, each one containing a deserialized message from the Journal for the entity actor with id _targetPersistentId beginning from offset long startSeqNo.
There’s 8 different query types that are supported by Akka.Persistence.Query:
CurrentPersistenceIds/PersistenceIds- gets the set of all knownPeristentIds in the database; the former gets all of the known ones up until now, the latter gets all of them continuously running in perpetuity until the application exits.CurrentEventsByPersistentId/EventsByPersistentId- gets all events for a specificPersistentIdstarting from an optionalOffset.CurrentAllEvents/AllEvents- queries all events from theJournalbeginning from an optionalOffset.CurrentEventsByTag/EventsByTag- queries all events from theJournalfor a specificstring Tagbeginning from an optionalOffset.
What’s important to note here is the Current_ prefix - those are “finite” queries: the stream will terminate when all of the events have been found.
The other queries, are “infinite” queries - they will continuously look for new events beginning from their last recorded Offset (all queries use offsets to paginate internally, by design.) It’s these infinite queries that are most interesting.
The execution flow for all persistence queries looks like this:
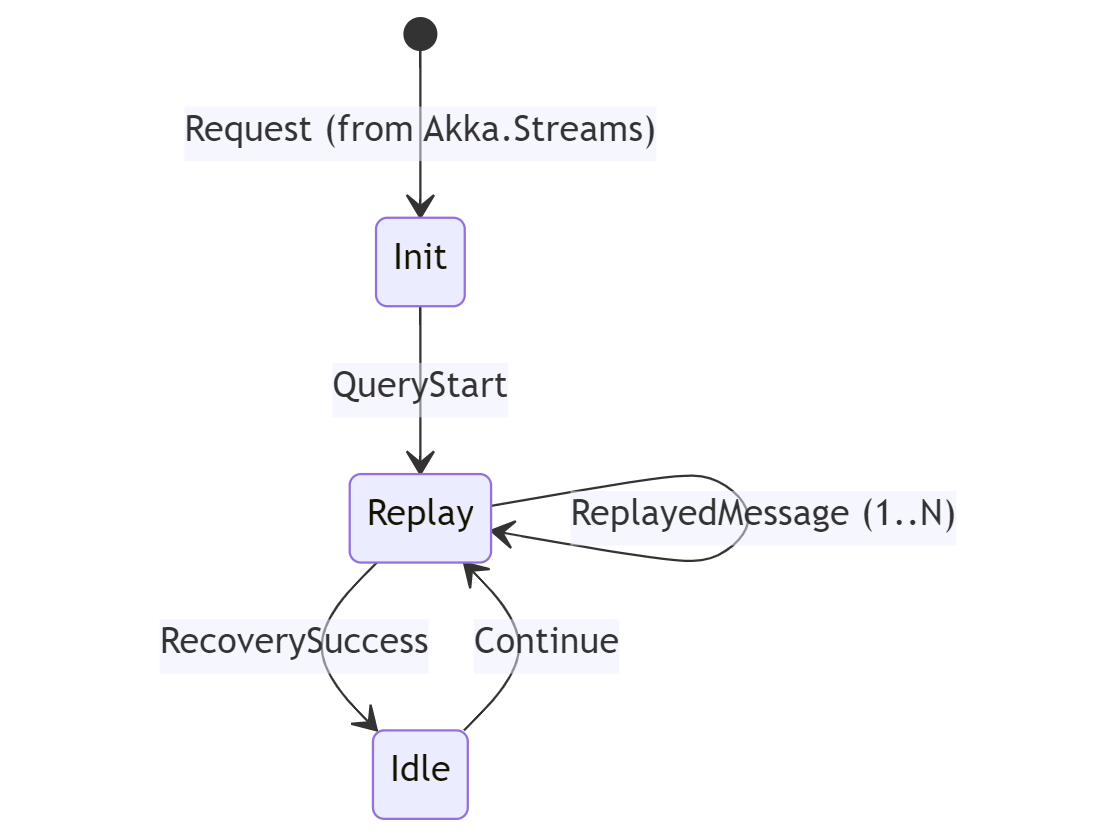
The Replay stage results in a query to the Journal, which opens a database connection, executes the query, and streams the deserialized results back to the Akka.Persistence.Query stream actors under the covers - sending a RecoverySuccess message once all events for that portion of the query have been successfully replayed.
For an infinite query, the Idle stage will periodically receive a Continue message on a timer in order to begin the next portion of the streaming query - and this will continue indefinitely until the stream or Akka.NET application is terminated.
It is this continuous polling of the database that creates a problem for Akka.NET v1.4 users.
Why Poll at All?
Why does Akka.Persistence.Query poll from the database rather than trying to use a “server push” model from the database?
- Most databases don’t expose any accessible means of subscribing to “new event” notifications - the SQL Server Service Broker and other equivalent technologies are typically not exposed on most installations, not enabled by default, and not easily accessible via the .NET drivers. Supporting this in a mainstream OSS project, therefore, is not feasible.
- The few databases that do expose new event notifications don’t scale subscriptions well or at all across partitions - Akka.Persistence.Redis originally used Redis Pub/Sub channels for driving query behavior. This worked ok until we added support for Redis clustering years later, which meant that several types of queries could no longer be supported (ones that spanned multiple shards.)
Polling “just works” because:
- Connections are typically short-lived;
- Queries are performantly modeled: no
JOINs, covered by an index, specific starting offset and a smallishLIMITof 100 typically; and - The polling interval is usually 1-3 seconds - not exactly enough to melt down a data-center.
That was the theory at least - but then it met the reality of end-user applications.
Problem: Connection Pool Saturation and Journal Contention
It’s quite common for Akka.NET users to have thousands, hundreds of thousands, or even tens of millions of persistent entity actors running in their system over the course of a given day. Some systems might have billions of these actors. It varies and we need to be able to support all reasonable end-user use cases.
Imagine a user who has 3,000 persistent entities that all periodically receive updates through the day - thus the Akka.NET user creates 3000 EventsByPersistentId Akka.Persistence.Query instances to create materialized views or projections of those events (i.e. turning event data into a read-optimized view for reporting, dashboards, user-facing applications, etc…)
What does that load look like?
3000 queries * 1s polling interval = 3000 queries per second
Now imagine you have 4 Akka.NET processes in a cluster all running a similar workload.
3000 queries * 1s polling interval * 4 nodes = 12,000 queries per second
All hitting the same database instance.
Databases are typically a single point of failure / single point of bottleneck in most software systems - this is because most databases are, by design, centralized single sources of truth. And these databases are subject to physical limits - such as the maximum number of open connections from clients at any given time.
Databases with a TCP connectivity model (i.e. all SQL databases) are going to be limited, at the very least, by the maximum number of ports on the database instance: 65,535. Most databases have a default connect limit that is considerably lower than the port limit. SQL Server’s, for instance, is 32,767 concurrent connections - 50% of the maximum port value.
Opening at least 12,000 connections per second is already putting us at ~40% of that limit - and that’s not considering any other traffic that can come from any other process with access to that database.
This is the danger zone - and it is very likely that this database is going to start timing out queries and causing availability problems throughout our application.
A second issue that can emerge if any of these entity actors are actively persisting events and the database uses a robust consistency model (i.e. any relational database): lock contention on the Journal’s table. This will cause both reads and writes to slow down.
The third and final issue is the simpler matter of load on the database - these Akka.Persistence.Query polling operations are going to be continuously executing throughout the lifespan of the Akka.NET application and that’s going to have side effects on other non-APQ queries that are waiting to run.
Users started reporting availability problems with Postgres around 3,000 queries per node - so now imagine what happens if someone wants to run 100,000 queries simultaneously? Under Akka.NET v1.4’s design - that would be very challenging if not outright impossible, to say the least.
What we are describing here is an acute problem in asynchronous software: backpressure.
Backpressure
I made an entire companion video explaining what backpressure is, its side effects, and how to manage it here - “Backpressure Explained”:
In normal, vanilla Akka.Peristence the Journal has some actors and functions that are designed to protect the database from connection pool saturation - rate limiters, circuit breakers, back-off, and more.
Akka.Persistence.Query, in Akka.NET v1.4, is YOLO-land - queries that needed to be executed were immediately sent to the Journal for asynchronous processing with absolutely no regard for the condition of the underlying database.
If the database starts timing out and failing requests the queries receive failure notifications back and shut themselves down or restart depending on how they were programmed by the end-user (see “Dealing with Failures in Akka.Streams.”)
This is our challenge - we have to have some means, at the level of Akka.Persistence.Query’s internal implementation, to prevent a large number of queries from absolutely melting down and end-user’s database. We have to introduce backpressure and back-off signaling internally inside Akka.Persistence in order to make sure that all queries execute without error and without rendering the database unavailable.
Reproducing the Problem
When Akka.NET users report a problem along the following lines (paraphrasing):
I’ve noticed that my application will fail to start up in our QA environment and Postgres starts having availability problems - I’m running approximately 3000 persistent queries. Why is this happening?
We will generally take your word for it - however, before we start making significant structural changes to components used by thousands of companies around the world: we have to do our homework first and reproduce the problem.
Thus I created a “crush test” - similar to how shipbuilder’s determine at what sea depth a submarine’s hull will lose its structural integrity and is crushed by the accompanying water pressure.
Crush test: https://github.com/Aaronontheweb/AkkaSqlQueryCrushTest
Goal of this test: find a point of pressure where SQL Server 2019, running inside a local Docker container, will get crushed to death by Akka.Persistence.Query using the latest version of Akka.NET v1.4.
Once that point is determined - we’re going to need to implement a backpressure support inside a prototype Akka.NET v1.5 distribution and re-test: were we able to withstand the pressure?
Control Results
Amazingly, SQL Server 2019 running in a dinky Linux docker container on my local development machine shrugged off our first test: 10,000 queries querying 1 event per second. Worked without any backpressure support whatsoever. Hats off to the SQL Server team.
So we decided to scale the test in two dimensions:
100,000 queries, querying 10 events, for a total of 100 events per query, at a rate of once per second - 10,000,000 events in total. We never shut any of the queries down even after they complete - they will continue to run in the background, constantly.
How did this test work out?
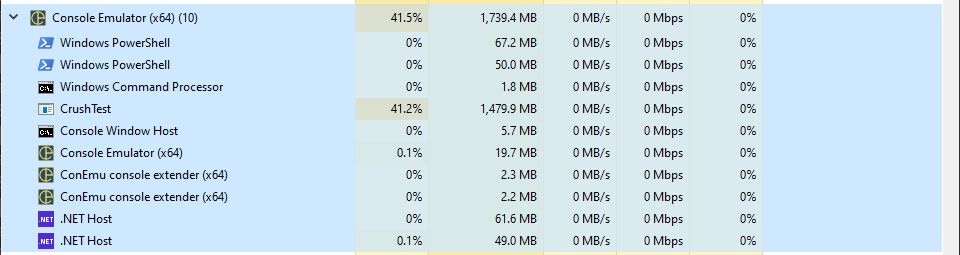
Our application quickly ramped up to about 40% CPU utilization on my 16-core AMD Ryzen machine and 1.5GB of RAM. The application was throttled by the rate at which SQL Server could complete queries / accept connections and began to fail less than a minute into the test - none of the queries ever recovered their 100 events successfully.
SQL Server was crushed. Now to find a solution to test.
Solution: Token Bucket Throttling
One of my favorite counter-intuitive ideas in asynchronous and concurrent programming is “slowing down to speed up” - that the application as a whole can complete measurably and consistently faster by reducing the number of operations that are allowed to run concurrently at any given time.
This phenomenon occurs usually when there’s an inescapable resource constraint inside a system; typically it’s something physical like bandwidth, disk I/O, or in this case the number of parallel queries SQL Server can complete at any given moment.
The idea is this: SQL Server can reasonably complete 100 queries per node concurrently with a very low amount of lock contention and minimal impact to the total connection pool. The entire application as a whole will be able to successfully complete all 100,000 queries with fewer errors AND overall faster end to end throughput if we limit the degree of parallelism.
What we’re discussing here is throttling - and it’s in the same school of thought as things like API rate limits.
Token Bucket Throttling
Token bucket throttling is how most API rate limits are enforced, and it operates on the following lines:
- Each request requires a certain number of tokens in order to execute - in Akka.Persistence.Query were going to weigh all requests the same, so 1 request = 1 token;
- In order for a client / query / etc to execute, it must receive a token - no token, no execution right now;
- Any unit of work that has a token can execute immediately;
- Any unit of work without a token must wait - and those waiters will be queued in FIFO order in Akka.Persistence.Query;
- When a unit of work completes - successfully or unsuccessfully - its tokens must be returned to the bucket; and
- When tokens are returned to the bucket, the waiters at the front of the queue receive them.
In the case of Akka.Persistence.Query, here’s what we implemented for all SQL plugins:
/// <summary>
/// Token bucket throttler that grants queries permissions to run each iteration
/// </summary>
/// <remarks>
/// Works identically to the RecoveryPermitter built into Akka.Persistence.
/// </remarks>
internal sealed class QueryThrottler : ReceiveActor
{
private readonly LinkedList<IActorRef> _pending = new();
private readonly ILoggingAdapter _log = Context.GetLogger();
private int _usedPermits;
private int _maxPendingStats;
public QueryThrottler(int maxPermits)
{
MaxPermits = maxPermits;
Receive<RequestQueryStart>(_ =>
{
Context.Watch(Sender);
if (_usedPermits >= MaxPermits)
{
if (_pending.Count == 0)
_log.Debug("Exceeded max-concurrent-queries[{0}]. First pending {1}", MaxPermits, Sender);
_pending.AddLast(Sender);
_maxPendingStats = Math.Max(_maxPendingStats, _pending.Count);
}
else
{
QueryStartGranted(Sender);
}
});
Receive<ReturnQueryStart>(_ =>
{
ReturnQueryPermit(Sender);
});
Receive<Terminated>(terminated =>
{
if (!_pending.Remove(terminated.ActorRef))
{
ReturnQueryPermit(terminated.ActorRef);
}
});
}
public int MaxPermits { get; }
private void QueryStartGranted(IActorRef actorRef)
{
_usedPermits++;
actorRef.Tell(Sql.QueryStartGranted.Instance);
}
private void ReturnQueryPermit(IActorRef actorRef)
{
_usedPermits--;
Context.Unwatch(actorRef);
if (_usedPermits < 0)
throw new IllegalStateException("Permits must not be negative");
if (_pending.Count > 0)
{
var popRef = _pending.First?.Value;
_pending.RemoveFirst();
QueryStartGranted(popRef);
}
if (_pending.Count != 0 || _maxPendingStats <= 0)
return;
if(_log.IsDebugEnabled)
_log.Debug("Drained pending recovery permit requests, max in progress was [{0}], still [{1}] in progress", _usedPermits + _maxPendingStats, _usedPermits);
_maxPendingStats = 0;
}
}
There is exactly one QueryPermitter per Journal inside a given ActorSystem - and by default we limit the number of concurrent queries to 100 via a HOCON setting (with Akka.Hosting support coming soon):
akka.persistence.query.journal.sql {
# Implementation class of the SQL ReadJournalProvider
class = "Akka.Persistence.Query.Sql.SqlReadJournalProvider, Akka.Persistence.Query.Sql"
# Absolute path to the write journal plugin configuration entry that this
# query journal will connect to.
# If undefined (or "") it will connect to the default journal as specified by the
# akka.persistence.journal.plugin property.
write-plugin = ""
# The SQL write journal is notifying the query side as soon as things
# are persisted, but for efficiency reasons the query side retrieves the events
# in batches that sometimes can be delayed up to the configured `refresh-interval`.
refresh-interval = 3s
# How many events to fetch in one query (replay) and keep buffered until they
# are delivered downstreams.
max-buffer-size = 100
# Determines how many queries are allowed to run in parallel at any given time
max-concurrent-queries = 100
}
This very closely follows the design of Akka.Persistence’s RecoveryPermitter - which is designed to protect the database during the recovery of a large number of persistent actors.
In addition to introducing this new QueryPermitter actor, we also needed to update the queries themselves to support them - so we changed all of the flows to follow a new pattern:
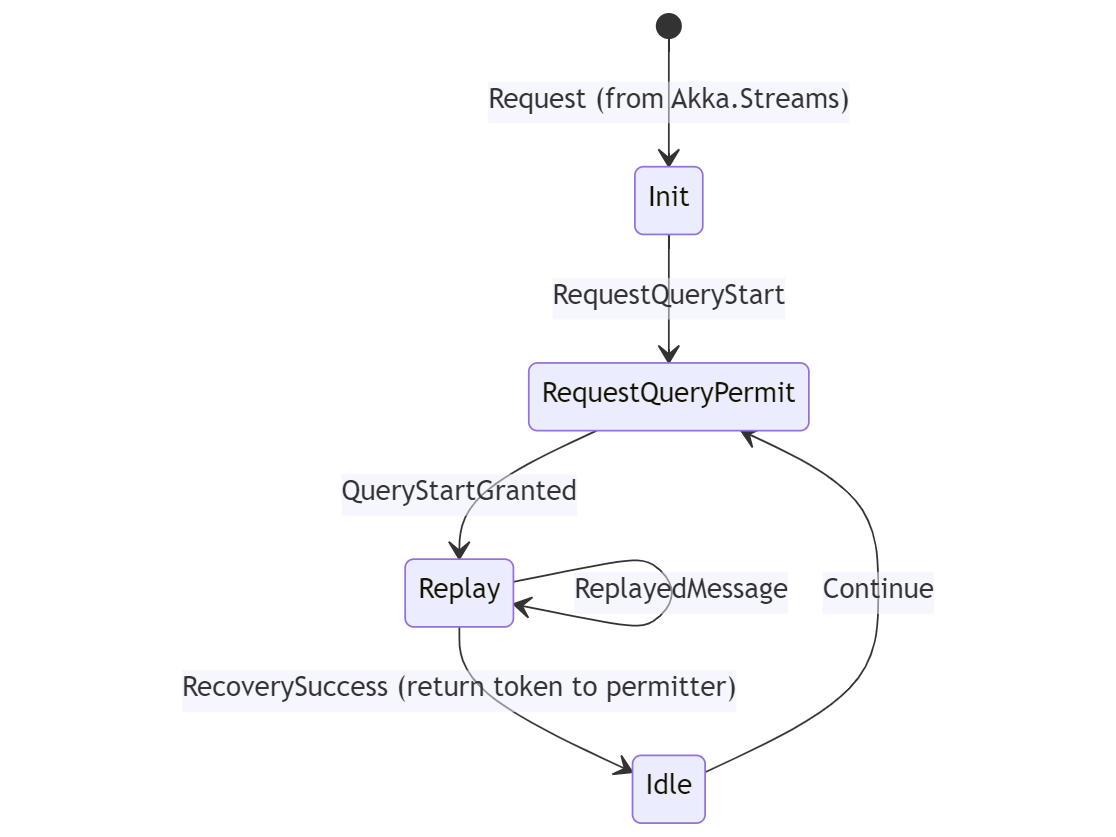
During the RequestQueryPermit state, queries wait until a token is granted to them by the QueryPermitter. Once the token is granted, the query will execute and return the token back to the QueryPermitter once we receive a RecoverySuccess message from the journal indicating that this leg of the query has run to completion.
The trade-off here is that the QueryPermitter is going to introduce additional queuing and latency into each query - but here’s why that probably doesn’t matter:
- For very low query volumes the overhead isn’t noticeable - Akka.NET in-memory messaging runs at millions of messages per actor per second; the delays involved in round-tripping to the
QueryPermitterare a rounding error compared to the overhead of querying the database; - For very high volumes - those queries were going to take a long time anyway and many would fail continuously as a result of database saturation. This approach guarantees that everything will complete successfully, even if there is some additional waiting involved.
With this change implemented and introduced in https://github.com/akkadotnet/akka.net/pull/6436, we needed to revisit our “crush test.”
Test Results
Using the exact same setup as our control, we used a local build of Akka.NET, Akka.Persistence.SqlServer, and Akka.Hosting to re-run the experiment.
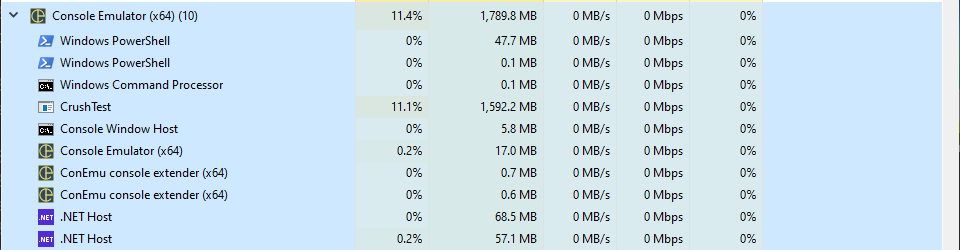
Done in 00:39:58.8746578
It took 40 minutes for the test to complete (more thoughts on that in a second) but there were zero errors and the application itself never ran at more than 11-12% CPU utilization. Memory usage was pretty close to our control (probably from the hundreds of thousands of actors all running in the background.)
This was a success!
To make this test complete more quickly we could have tuned some of the settings (i.e. max-buffer-size = 100, the default, would have reduced the total amount of queries needed by an order of magnitude) - but that was never the point of the test. Making sure Akka.Peristence.Query didn’t crush a lightly provisioned database instance was the point!
For what it’s worth, when I run this query with max-buffer-size=100 we complete in 8 minutes, 54 seconds.
Large Scale CQRS in Akka.NET
As of Akka.NET v1.5 it’ll be possible to run hundreds of thousands of parallel streaming queries against a shared database using Akka.Persistence.Query - but is that a good idea?
So that depends - I personally would probably run a single AllEventsQuery as a ClusterSingleton and have it meter out its events to individual projection actors inside the cluster using the PersistentId on the EventEnvelope as the shard key. That would be much less overhead than thousands of parallel EventsByPersistentId queries running continuously - but the downside would be that now the rate of processing for all projections is temporally coupled. Overall though, that design would allow for replaying of really large journals much more quickly than hundreds of thousands of continuously running small queries.
However, if I’m running ~3-4k EventsByPersistentId instances? I’d probably just run that workload without adding singletons and so on - Akka.Persistence.Query can handle that without much fuss, as we’ve now demonstrated.
I hope you enjoyed this post! Please leave any questions or comments you have might below!
If you liked this post, you can share it with your followers or follow us on Twitter!
- Read more about:
- Akka.NET
- Case Studies
- Videos
Observe and Monitor Your Akka.NET Applications with Phobos
Did you know that Phobos can automatically instrument your Akka.NET applications with OpenTelemetry?
Click here to learn more.