// BLOG
Designing Akka.NET Applications from Scratch Part 1: Go with the Flow
Writing Code That Ages Well
Since releasing Akka.NET 1.1 I’ve been spending more time sharpening the saw here at Petabridge. Combing over the ways we spend our time and money and quantifying the returns that provides to us and to our customers. As it turns out, quantifying this is rather difficult for reasons that are all-too-common in the business world: data silos.
Our “business output” is measured and recorded in a number of disparate, disconnected, off-the-shelf systems. For example: We record our sales through Stripe and Quickbooks Online, but we never correlate them with the end-user interactions with Akka.NET Bootcamp, our YouTube videos, or our blog.
We want a complete picture of what really lead to a sale or to a successful deployment of Akka.NET, because that helps tell us what were good investments of our resources. So in order to do this I started designing a business intelligence application called “Brute” designed to perpetually stream information from all of these sources into a consolidated view. The first version of it is extremely simple but we have plans to expand what it does and the number of systems it can connect to.
Designing an Akka.NET Application
I decided that “Brute” presented a good opportunity for Petabridge to dogfood Akka.NET, especially some of the new modules such as Akka.Streams and Akka.Cluster.Sharding. Thus I’ve spent the past few weeks in the design process writing specifications, models, and documentation.
Protocol-Driven Design
Here’s the catch with designing an Akka.NET application, or really, any actor-based application: your actors aren’t the correct place to begin the design.
Instead, you always want to start the design of any Akka.NET application with the flow of events and information that go through it.
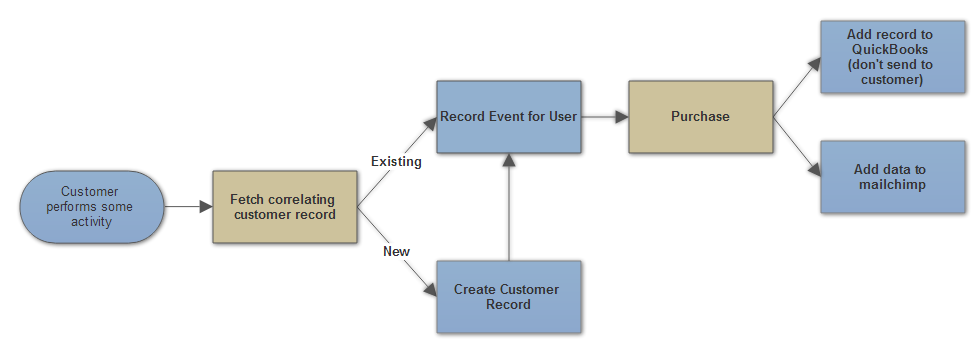
The chief idea behind this flow isn’t to get into the details of how to implement any particular feature of my Akka.NET application. It’s to describe how data moves through the system, what happens to it, and what we do with it, because this is the basis for our domain and actor model.
A data flow like this is the product of one or more user stories - all I’ve done is tell the story with a diagram. If I wanted to add support for some other types of special business events or reactions, I can easily append them to this diagram later. That’s because what this diagram is really describing is a protocol for how to treat events produced in Petabridge’s business domain.
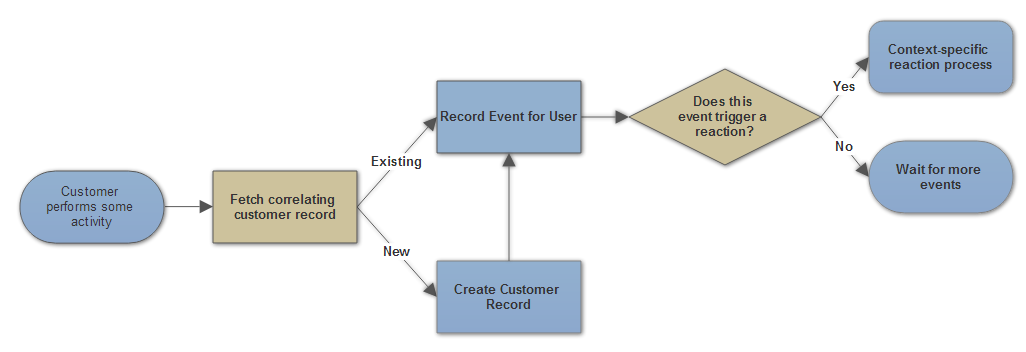
No matter how many types of data sources, types of reports, or possible reactions (i.e. recording a sale in QuickBooks, sending an email, etc) Brute supports it will always follow this protocol.
The number of message classes, actor classes, and the paths that messages take to make it from their origin to their final destination are implementation details. But now I have a really clear idea of what my application is trying to do, so when it comes time to begin implementing this I can always see where an actor fits into some stage of this protocol.
Protocol Composition
The above protocol isn’t the end of the story for how Brute is going to work; it’s just the beginning. Its job is to introduce the high-level goals of the system.
As it comes closer to implementation time we may discover all sorts of new requirements such as:
- Reliability - can’t lose messages if the network flakes out;
- Ordering - events may be delivered by external systems out of order;
- Routing - ensure that all events for a particular user all end up in the same place on the network (usually the same actor;)
- Consistency - need to make sure all participating nodes in an Akka.NET Cluster are made aware at the same time that something important happened; and
- Validation - what happens if we receive input and it isn’t clear what to do with it?
The high-level protocol for Brute does not and should not address these questions. That’s where the beauty of this design comes in - at any of the steps in the previous diagram we can build in protocols that address these issues where needed.
For instance, if I know that the actors who observe user activity might live over the network apart from the actors who persist data for individual users then I’m going to need an “at least once” or “exactly once” message delivery protocol at that stage in order to have a solution ready for any network reliability issues that might cause a message not to be delivered successfully the first time around.
Protocols can be composed together from many smaller parts in order to produce elegant and reliable high-level functionality.
N.B. Never try to jam all of the low-level details for how the system may work into your high-level protocol. It just creates upfront technical debt. Always let the high level protocol remain simple and deal strictly with the business domain.
Fitting Actors into the Protocol
Akka.NET’s chief architecture for most business applications is a “stream processing” model - there can be a large number of concurrent streams of data (1 message = 1 piece of data in the stream) and each one gets run through the protocol.
Think of the protocol as an instance - each time a user produces an event in a system connected to Brute this entire protocol runs end-to-end; and if the user produces a large number of events in rapid succession, then this protocol will be running continuously for each event until all of them have been handled.
So where do actors fit into this picture? We start at the highest level.
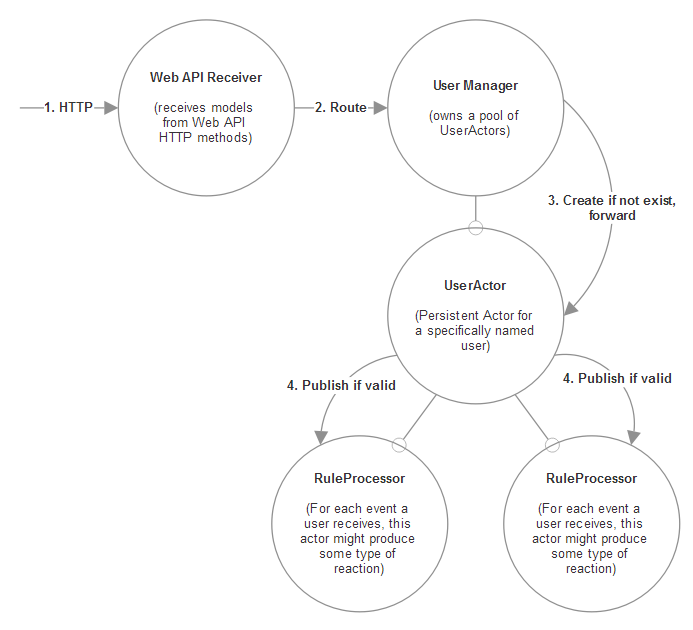
The number one design principle I adhere to when working with actors is the Single responsibility principle.
An actor should be tasked with doing exactly one thing.
So I have:
- a single actor for collecting events from the outside world via some sort of HTTP request processing system;
- a single one for managing the stateful
UserActors for each user; - the
UserActors themselves, who manage the history for each individual user; - and then finally the rule processors who decide whether or not a given event will trigger some sort of output from Brute - such as updating a report or sending a notification.
Each one of these actors correlates to exactly one stage of my high-level protocol. This is a good starting design, given that we haven’t written any code yet.
But what if the one thing an actor is responsible for is actually pretty complicated?
This is where the concept of the Akka.NET actor hierarchy begins to offer some big benefits; you still have a single “parent” actor responsible for the “complicated” thing, but it can decompose its parts into child actors.
We have a neat design pattern that addresses this type of “actor composition” concern directly: the fan-out pattern.
And this is where we’ll pick up in the next stage in our series: “Designing Akka.NET Applications from Scratch Part 2: Building an Effective Actor Hierarchy.” Subscribe to get the next post in our series.
Read the rest of the posts in this series:
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.

Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS