// BLOG
Designing Akka.NET Applications from Scratch Part 2: Hierarchies and SOLID Principles
Decomposing Complex Domains into Understandable Actor Hierarchies
In the first post in this series, we discussed how the correct place to begin thinking about an Akka.NET application is actually with your data flows and organizing those into reusable “protocols”. Once that’s done, then it’s time to start slotting actors into some of the interaction points inside the protocol.
But what happens when certain types of interactions are complicated and can’t easily be expressed inside one actor? Or what happens if you need to accumulate state for each individual instance of the protocol?
Think of a protocol like a class. A protocol is a logical unit of encapsulation that expresses some defined behaviors, inputs, and outputs. And just like classes, protocols can be composed - one class can have members that are of another type of class. Small protocols can be combined with other protocols to build large, system-defining behaviors. This is generally how stream processing architectures are actually designed at scale.
An instance of a class is called an object in OOP. In protocol-driven design a “protocol instance” is an instance of a protocol, just like how a class is instance of an object.
Actor Hierarchies and Protocols
A protocol consists of multiple different interactions and can have totally different flows depending on the state of each particular protocol instance. Your Akka.NET actor system can theoretically run hundreds of thousands of concurrent protocol instances at the same time. It’s the goal of a well-designed actor hierarchy to make it performant and easy to manage.
So the first rule of thumb when it comes to designing an actor hierarchy is once again: separate your concerns.
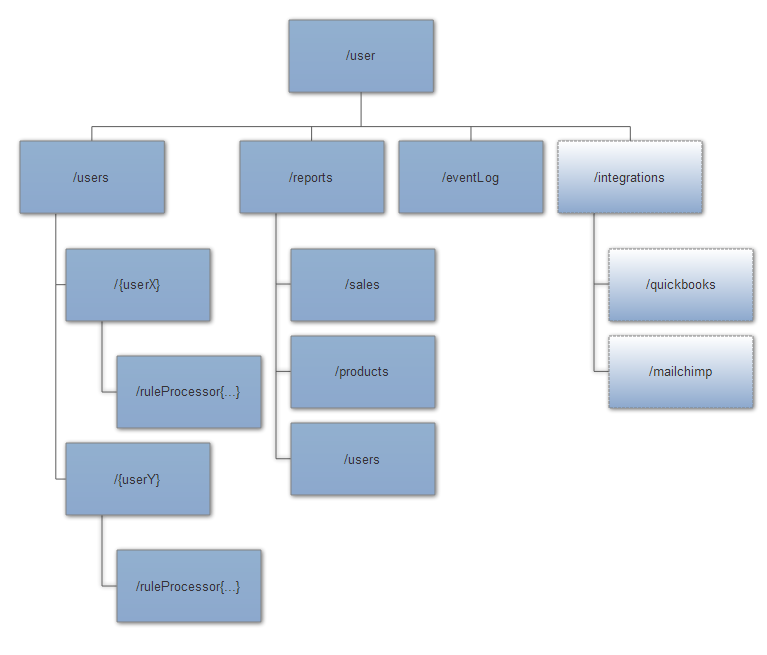
It’s pointless to attempt to design an entire end-to-end actor system before you’ve written any code, because you don’t know what you don’t know yet. We’re better off designing something highly generalized and simple that expresses what each of the concerns are, and that’s what I’ve done in the above diagram.
We know, reasonably well, that we’re going to need to:
- Process events for individual users;
- Compile these events into reports;
- Integrate with third party services (for both receiving and sending events;) and
- We’ll need some way of recording state changes to the system in a human-readable way.
That’s what this relatively simple hierarchy expresses: a generalized way of encapsulating all of the interaction points for our high level protocol into their own distinct, self-managing regions.
What’s also important about this diagram is what it doesn’t address:
- Location of each actor on the network;
- Types of messages received and produced by each actor;
- Interactions between actors on different portions of the hierarchy; and
- The entire full depth of the hierarchy down to the lowest, most concrete levels of responsibility.
The actors in these regions will inevitably interact with each other and in some cases we might partition off portions of this actor hierarchy over the network in accordance with relevant microservice design principles (fault and resource isolation; CAP) - but we don’t start by bringing any of that into the mix yet.
The goal is, first, to define the areas of responsibility of our application; each of the major areas should own its own actor hierarchy. That way its fault handling, actor implementation classes, and internal messaging can all be decided independently from the others.
Which brings me to the next big point.
Principles of Good Actor Hierarchy Design
There are three major principles of actor hierarchy design that are universally true:
- Never hard-code the design of one hierarchy into another;
- Always initiate communication through the top of the hierarchy; and
- Always delegate risky operations to leaf nodes (actors with no children.)
Avoid Hard-Coding of Actor Hierarchy Design
Suppose we have some Brute actors responsible for managing and persisting events for a particular end-user and we have some other actors responsible for integrations with third-party services. These two groups of actors will need to communicate with each other under some circumstances, but fundamentally they are separate concerns.
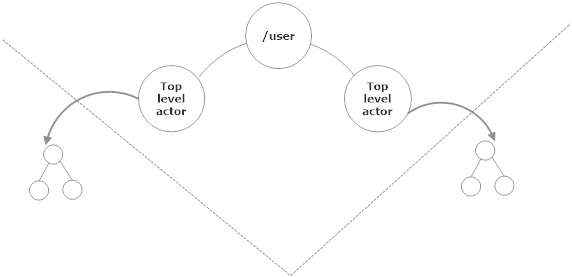
These two actor hierarchies should have no knowledge about each other’s implementation. They should know how to contact the top-level actor for either side of the hierarchy but that’s it.
The reason why we do this is to encourage loose coupling; in SOLID programming terms we do this for Liskov substitution and Dependency inversion. We should be able to change the underlying actor implementations (including adding new layers of children) in one hierarchy time without breaking any dependent hierarchies. The hierarchy is an abstraction that helps us hide those implementation details.
If one group of actors have to be pre-programmed or hard-coded with knowledge about how children, grand-children, and so forth are organized in another actor hierarchy then any changes to one actor hierarchy will inevitably affect the other. That’s poor design, and we avoid it by never baking that knowledge into the design of any actor classes.
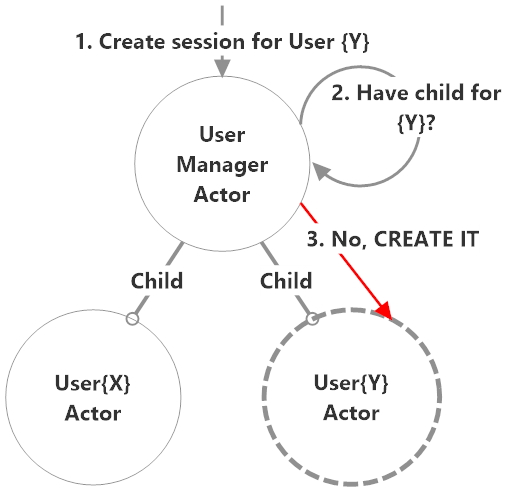
Actors should only be programmed with assumptions about the organization of their own children. No other hierarchy assumptions beyond than that.
Initiate Contact through the Top of the Actor Hierarchy
Given that our actors are programmed with no foreknowledge of how any other parts of the actor hierarchy work, how then do they communicate?
You can always communicate with any old actor via an IActorRef, but if you don’t have an IActorRef then the answer is simple: we communicate with the appropriate “top-level” actor as a means of accessing the concrete actor best-suited to process whatever work we require.
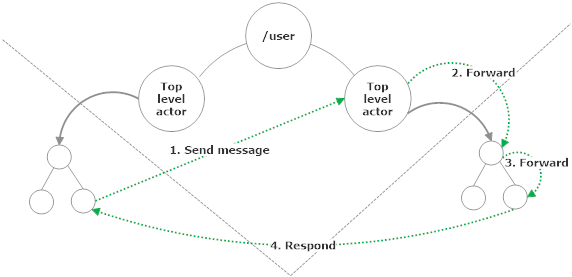
Top-level actors are considered to be interfaces to the rest of the underlying actor hierarchy. In most production systems, top-level actors are usually implemented as some type of router. Whether it’s literally a built-in Akka.NET router type or a user-defined actor that performs routing depends on the use case.
It’s OK to expose a top-level actor’s IActorRef in a configuration class; pass in the IActorRef as a constructor argument; or to have a low-level actor contact a top-level actor via ActorSelection. Any of these means are valid tools for imitating contact with a top-level actor, as they’re meant to be public interfaces and therefore Closed for modification (technically, this is the O on SOLID for Open/closed principle.)
We can always shuffle around the hierarchy underneath the top-level actor or we can extend the hierarchy to handle new types of messages, but we never ever rename the top-level actor or have it stop handling messages it used to in the past.
The top-level actor’s job is to direct the message to the right child, depending on the message’s content. And this can be done many times over throughout the depth of the hierarchy, until the appropriate leaf actor receives the message, handles it, and produces a response.
NOTE: Most parent actors facilitate this forwarding process using the
IActorRef.Forwardmethod, which preserves the current sender of the message when it’s delivered to the child. In other words, to the child it appears as though it received the message directly from the original sender. The parent actors who performed the routing are transparent. This is also how built-in Akka.NET routers work.
Any further communication between leaf node actors can be done directly to each other without going through the top again, because they have an IActorRef for each other and can send messages using that instead.
What this process of “communicating through the top” enables you to do is the following:
- Any actor can dynamically discover any other actor by sending a relevant message to the top-level actor of that hierarchy, making the locations of all concrete actors (ones that do actual work) fully transparent;
- Any actor hierarchy can be refactored, reorganized, or even redployed to a different position over the network without affecting any other hierarchy; and
- Exposes the Akka.NET
ActorSystemto external contexts, such as SignalR, ASP.NET, etc without having to leak implementation details to this systems. Since top-level actors are typically declared in external contexts (i.e. in yourStartup.csfile if you’re using OWIN), it’s easy to pass a reference to them to SignalR hubs or MVC controllers via dependency injection or other means. Those top-level actors can pass messages from the external contexts into the actor system and send replies back if needed (viaAsk<T>.)
Delegate Risky Work to Leaf Nodes (Actors With no Children)
The final high-level principle of good actor hierarchy design has more to do with fault-tolerance than loose coupling. The basic idea is simple: never allow an actor who has children to execute any “risky” operation directly; always delegate that operation to a child actor.
A “risky” operation is defined as anything that has a non-zero chance of throwing an exception under normal circumstances. Examples include:
- Network communication, including database calls;
- Working with files;
- Parsing documents that might be malformed or incorrectly versioned;
- Calling external unsafe code through COM interop or C++/CLI; or
- External assembly or runtime type-loading.s.
In all of these circumstances you know with certainty that having an exception occur is matter of when, not if. It doesn’t matter how frequently exceptions are thrown; all that matters is that they are possible.
N.B. Don’t go nuts with bulk-heading around possible exceptions; if an
OutOfMemoryExceptionis thrown yourActorSystemand the rest of your code is toast no matter what.
Risky operations are most safely executed inside “leaf node” actors, i.e. ones on the hierarchy that have no children of their own. The reason being is that the cost of restarting that actor is the least expensive.
When actors fail and restart, they are recreated in their original state as defined via the Props class that was used to create them.
What happens if an actor with children restarts? Their children are killed too, because they’re not part of the original state of that actor, as they’re all created at run-time. This behavior can be overriden by not calling the base.PreRestart method inside your own override of PreRestart on your actor class definition, but that’s besides the point, which is don’t design parent actors that can fail this way in the first place.
Delegate risky operations to leaf node actors so their failures can occur in total isolation from all other actors, and leave it up to the parents how to restart and resume working with those actors.
What About Distributed Akka.NET Applications?
Earlier in this article we mentioned not worrying about the network design of your hierarchy initially… Ok, well now that we roughly know what areas our actors should be segmented into and we have some general rules to follow in how they’re organized (the three principles above) the network needs to be taken into account.
And that will be the subject of part three of this series: “Designing Akka.NET Applications from Scratch Part 3: Choosing Your Network Architecture.”
Subscribe to get the next post in our series.
Read the rest of the posts in this series:
Observe and Monitor Your Akka.NET Applications with Phobos
Phobos automatically instruments your Akka.NET applications with OpenTelemetry — traces, metrics, and logs with built-in dashboards.

Enjoyed this post? Subscribe to our newsletter for more insights on distributed systems, Akka.NET, and .NET + AI.
// COMMENTS