Now that we have AKka.CQRS running inside Docker containers, it’s time for us to tidy up some loose ends with our cluster.
For instance, what happens to our Akka.NET cluster when we abruptly kill one of our Docker containers? Or if we try rolling out an update while the cluster is still running? Are these the desired behaviors of our cluster, or unplanned behaviors?
Let’s find out.
Getting Started
To start this lesson, we need to checkout to the lesson3 branch in our git repository:
PS> git checkout lesson3
In the last lesson, we used docker-compose to create an Akka.NET cluster that uses MongoDb as a persistent store and runs a handful of Akka.Cluster nodes: a Lighthouse node, an Akka.CQRS.TradePlacers.Service node, and an Akka.CQRS.TradeProcessor.Service node.
If you aren’t still running your Docker cluster from the last lesson, let’s get it up and running again now:
PS> docker-compose up
Once your containers are up and running, let’s use Petabridge.Cmd’s pbm tool to get a readout of the current cluster by connecting to the Lighthouse node listening with Petabridge.Cmd.Host on 127.0.0.1:9110:
PS> pbm 127.0.0.1:9110 cluster show
You should see output similar to the following:
akka.tcp://AkkaTrader@47de931e9258:5110 | [trader,trade-events] | up |
akka.tcp://AkkaTrader@5fed9a122ad6:5110 | [trade-processor,trade-events] | up |
akka.tcp://AkkaTrader@lighthouse:4053 | [lighthouse] | up |
Count: 3 nodes
Let’s try something with our cluster and see if this behavior works for us… or not. Open Kitematic and kill the container running the akka.cqrs.traders image:
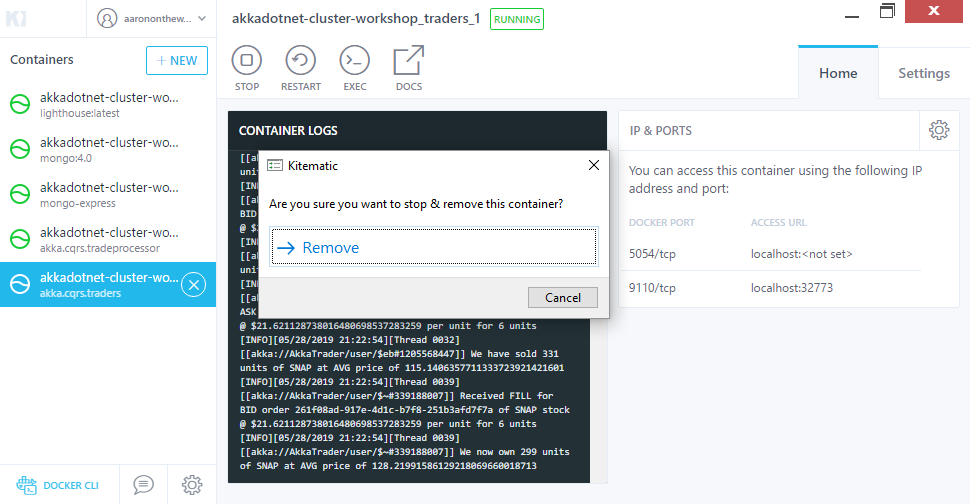
Once the container has been terminated and deleted, let’s try re-running the cluster show command:
PS> pbm 127.0.0.1:9110 cluster show
akka.tcp://AkkaTrader@47de931e9258:5110 | [trader,trade-events] | up | unreachable
akka.tcp://AkkaTrader@5fed9a122ad6:5110 | [trade-processor,trade-events] | up |
akka.tcp://AkkaTrader@lighthouse:4053 | [lighthouse] | up |
Count: 3 nodes
We now have an unreachable node, which means at least some of the nodes in the cluster are unable to contact it. In reality, this node is gone and it’s not coming back.
Well, let’s see what happens when we try running docker-compose up again in a new terminal window:
PS> docker-compose up -d
akkadotnet-cluster-workshop_mongo_1 is up-to-date
akkadotnet-cluster-workshop_lighthouse_1 is up-to-date
akkadotnet-cluster-workshop_mongo-express_1 is up-to-date
akkadotnet-cluster-workshop_tradeprocessor_1 is up-to-date
Creating akkadotnet-cluster-workshop_traders_1 ... done
Looks like we have a new akka.cqrs.traders node up and running again - so let’s see if this node was able to join the cluster.
PS> pbm 127.0.0.1:9110 cluster show
akka.tcp://AkkaTrader@47de931e9258:5110 | [trader,trade-events] | up | unreachable
akka.tcp://AkkaTrader@5fed9a122ad6:5110 | [trade-processor,trade-events] | up |
akka.tcp://AkkaTrader@64dd482c7091:5110 | [trader,trade-events] | joining |
akka.tcp://AkkaTrader@lighthouse:4053 | [lighthouse] | up |
Count: 4 nodes
Uh oh - the node is stuck in the joining stage, because the previous incarnation of the akka.cqrs.traders node is still marked as “up” but “unreachable” inside the cluster. And because reachability and membership in an Akka.NET cluster aren’t the same thing, the current leader of the Akka.NET cluster won’t make any changes to the current membership of the Akka.NET cluster until that unreachable down is dealt with.
So let’s do that using Petabridge.Cmd’s cluster down-unreachable command:
PS> pbm 127.0.0.1:9110 cluster down-unreachable
Proceeding with downing nodes [akka.tcp://AkkaTrader@47de931e9258:5110]
akka.tcp://AkkaTrader@47de931e9258:5110 is now Removed.
Downing complete.
Looks like the old traders node is gone now - let’s confirm that:
PS> pbm 127.0.0.1:9110 cluster show
akka.tcp://AkkaTrader@5fed9a122ad6:5110 | [trade-processor,trade-events] | up |
akka.tcp://AkkaTrader@64dd482c7091:5110 | [trader,trade-events] | up |
akka.tcp://AkkaTrader@lighthouse:4053 | [lighthouse] | up |
Count: 3 nodes
There we go - now our cluster is back to processing bids and asks for stock symbols once again.
However, it’s really inconvenient that a human being had to go into our cluster and clean up an unreachable node inside our Akka.NET cluster like this. Imagine if that happened in the middle of the night or on a holiday? Is there a better way of handling these types of network partitions?
Yes, there is: split brain resolvers.
Working with Split Brain Resolvers in Akka.Cluster
As we mention in our blog post “The Proper Care and Feeding of Akka.NET Clusters: Understanding Reachability vs. Membership:”
In Akka.Cluster there are two important, similar-looking concepts that every end-user should be able to distinguish:
- Node reachability - is this node available right now? Can I connect to it?
- Node membership - is this node a current member of the cluster? Is this node leaving? Joining? Removed?
When many users start working with Akka.Cluster, they operate from the assumption that these two concepts are the same. “If I kill a process that is part of an Akka.NET cluster, that process will no longer be part of the cluster.”
This assumption is incorrect and there’s an important distributed computing concept at work behind this distinction: partition tolerance.
By default, Akka.Cluster assumes that when a node becomes unreachable that it will only be unreachable temporarily. This is a good, safe default - because most network partitions are temporary in nature.
The most common causes of network partitions in high-traffic systems, in our experience:
- Node CPU spiking to 100% (messages get delivered, but node isn’t able to process them;)
- Network I/O device gets saturated (messages may not get delivered or processed;) and
- New node joins network and has to synchronize with other nodes during busy times, temporarily putting additional pressure on all of the original, highly utilized nodes.
Issues like being busy, crowding, or having a network device be saturated are temporary problems that usually resolve themselves quickly. Immediately knocking a node out of the network because it couldn’t respond to you for three seconds is a fantastic recipe for creating brittle systems that can’t tolerate routine network partitions. Thus, Akka.Cluster’s default position of not doing anything when a network partition occurs is pretty safe.
However, there are some important edge cases with respect to network partitions that are not addressed at all by Akka.Cluster’s default behavior:
- Process crashes;
- Hardware outages; and
- Rack or datacenter-level failures.
Some of these scenarios may necessitate human intervention at a hardware level in order to be resolved - however, it’d be unacceptable for our software solutions built on top of Akka.NET to just go down with the hardware. We must arm our applications with the ability to respond to these types of network partitions and heal itself automatically, even if we have to do it with degraded availability.
This is where Split Brain Resolvers in Akka.Cluster come into the picture.
Fundamentally, a split brain resolver is a type of algorithm that is designed to answer the question “when do we decide that an unreachable node is really no longer a functioning member of the cluster?”
So let’s install a split brain resolver into Akka.CQRS and see what it does. Open the Akka.CQRS.Infrastructure/Ops/ops.conf file and paste in the following HOCON:
# Akka.Cluster split-brain resolver configurations
akka.cluster{
downing-provider-class = "Akka.Cluster.SplitBrainResolver, Akka.Cluster"
split-brain-resolver {
active-strategy = keep-majority
}
}
This HOCON configuration enables a “keep majority” split brain resolver strategy, and here’s what that means:
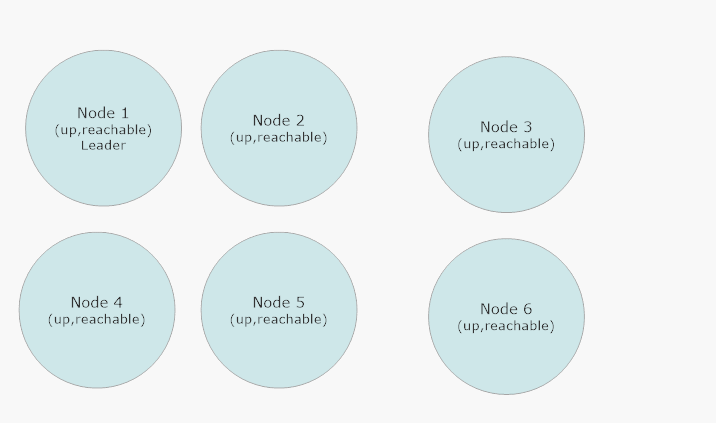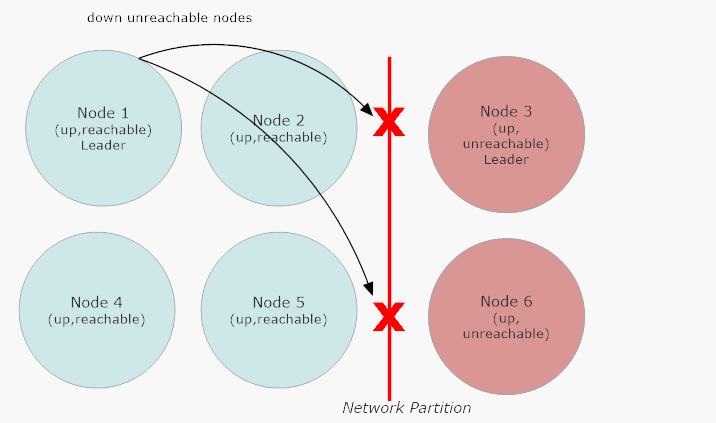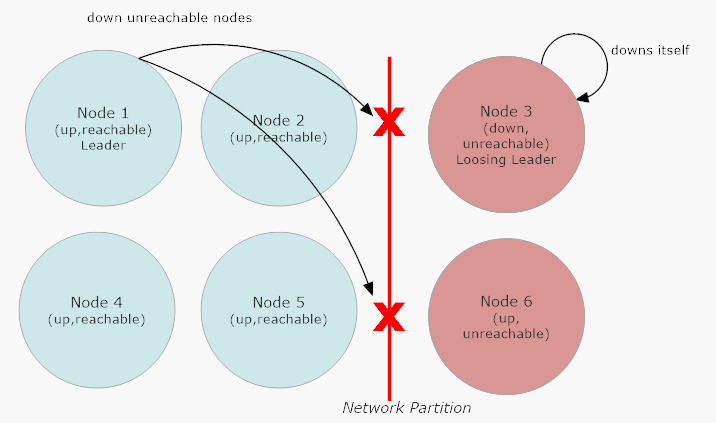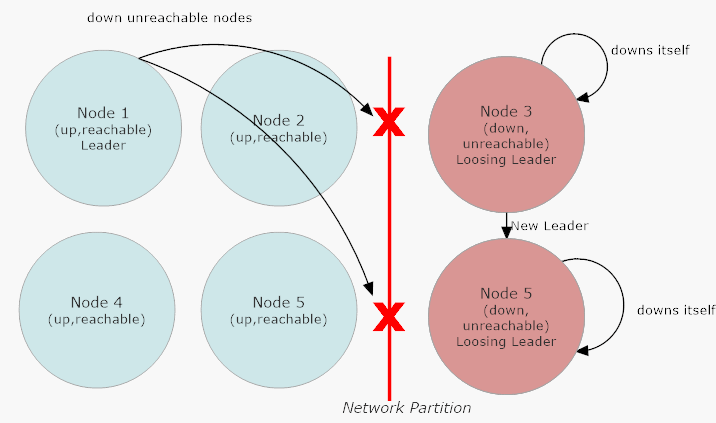
In the event that there’s a network partition, the “winning” side of the cluster is the side with the majority of nodes still reachable. Suppose we have a 6 node cluster and two nodes suddenly become unreachable at the same time because a network switch crashed - the two unreachable nodes in the “losing” side of the partition will have their own cluster leader, because the leader in Akka.Cluster is determined to be the reachable node at the top of the sort order for all of the member’s Addresses in the cluster. Therefore, there will be two leaders: a winning leader and a losing leader.
All of Akka.NET’s split brain resolver algorithms are designed to run on both sides of a network partition simultaneously: the winning side and the losing side. The winning side will kick the losers out of the remaining cluster and resume normal operations, the losing side will gradually kill itself by calling Down on each of its leaders until all of them are dead.
This way, new nodes will quickly be able to join the remaining “winning” side of the cluster without having to wait for a human to intervene and manually Down the unreachable members of the cluster.
Bonus Exercise: why did we pick keep-majority as our split brain resolver strategy? What are some of the other strategies we could have used? What are their trade-offs?
With our split brain resolver in-place, let’s rebuild our Docker images and retry our experiment from earlier in this lesson.
Call docker-compose and launch our cluster:
PS> docker-compose up
And let’s kill off the traders node again, once our cluster is up and running:
If we use pbm to view the current state of the cluster right away, we should still see that the trader node is unreachable:
PS> pbm 127.0.0.1:9110 cluster show
akka.tcp://AkkaTrader@2b870820e451:5110 | [trade-events,trade-processor] | up |
akka.tcp://AkkaTrader@ba95fa3652db:5110 | [trade-events,trader] | up | unreachable
akka.tcp://AkkaTrader@lighthouse:4053 | [lighthouse] | up |
Count: 3 nodes
However, if we wait for 45s seconds (the default combined interval needed for a split brain resolver to down and unreachable node out of the cluster - this is configurable) we’ll see the unreachable node disappear.
PS> pbm 127.0.0.1:9110 cluster show
akka.tcp://AkkaTrader@2b870820e451:5110 | [trade-events,trade-processor] | up |
akka.tcp://AkkaTrader@lighthouse:4053 | [lighthouse] | up |
Count: 2 nodes
That’s the split brain resolver at work, and now we no longer need to worry about doing this ourselves.
The next issue we need to address in order to ensure the smooth operation of our Akka.NET cluster is to introduce a measure of version-tolerance into the design of our messages going over the network and the state that we’re persisting to MongoDb.
Using Google Protocol Buffers to Version State and Messages
One of the more difficult problems in computer science, historically, has been the problem of versioning - whether it’s versionining programs in a backwards-compatible manner, messages, stored data, file formats, and so on.
In the case of Akka.NET versioning rears its head in two fronts:
- Akka.Remote - versioning messages in such a fashion that changes in existing message types can be introduced without needing to take a running Akka.NET cluster offline first and
- Akka.Persistence - versioning persisted events and snapshots in such a manner that they can be replayed and recovered by persistent actors long into the future.
Fortunately there is a solution that addresses both of these issues: serializing critical messages and events using a versioned schema such as Google Protocol Buffers, or protobuf for short.
Why Protobuf?
So why are we looking at replacing Akka.NET’s default, built-in serialization using JSON.NET for protobuf when it comes to our cross-service commands and events? What’s the benefit?
Take, for a moment, the Ask event - used to place a “sell” order on the orderBooks for a specific stock:
/// <inheritdoc />
/// <summary>
/// Represents a "sell"-side event
/// </summary>
public sealed class Ask : IWithStockId, IWithOrderId
{
public Ask(string stockId, string orderId, decimal askPrice,
double askQuantity, DateTimeOffset timeIssued)
{
StockId = stockId;
AskPrice = askPrice;
AskQuantity = askQuantity;
TimeIssued = timeIssued;
OrderId = orderId;
}
public string StockId { get; }
public decimal AskPrice { get; }
public double AskQuantity { get; }
public DateTimeOffset TimeIssued { get; }
public string OrderId { get; }
}
Suppose we have a new business requirement from product management where we need to include, on every trade order (Bid and Ask), a bool indicating whether or not this trade was purchased with margin debt. All we need to do is add a new field to these two messages and a new constructor parameter. Easy enough, right?
/// <inheritdoc />
/// <summary>
/// Represents a "sell"-side event
/// </summary>
public sealed class Ask : IWithStockId, IWithOrderId
{
public Ask(string stockId, string orderId, decimal askPrice,
double askQuantity, DateTimeOffset timeIssued, bool onMargin = false)
{
StockId = stockId;
AskPrice = askPrice;
AskQuantity = askQuantity;
TimeIssued = timeIssued;
OrderId = orderId;
OnMargin = onMargin;
}
public string StockId { get; }
public decimal AskPrice { get; }
public double AskQuantity { get; }
public DateTimeOffset TimeIssued { get; }
public string OrderId { get; }
public bool OnMargin { get; }
}
Believe it or not, this is a breaking binary change due to the change in constructor signature - if we were to send a copy of this new Ask message type to a machine that was still running with an older version of the Akka.CQRS library at run-time (hint: the odds of this happening are close to 100% during deployments), the machines running the old code would fail to deserialize these messages and therefore could not process them. This could also happen in the case of Akka.Persistence - a node with old code trying to replay a message saved with the new code by a different node would crash during Akka.Peristence recovery. These are scenarios we would rather avoid.
Polymorphic serialization - treating the C# and F# definitions of our messages as the wire formats, is what Akka.NET uses by default because it’s convenient to setup and help developers get started right away. However, as we’ve just shown: it can be brittle in production scenarios. All it takes is one developer with a ReSharper license and a hankering for adjusting some of your messages’ namespaces to blow up your wire format.
It’s perfectly fine to prototype and develop your Akka.NET application relying on polymorphic serialization at first, but as a best practice you are much, much better off moving to schema-based serialization before you go into production. Setting up Protocol Buffer definitions for all of your core message and event types is tedious the first time you do it, but there’s a massive payoff over the long run. Here are the key reasons why:
- Protobuf serialization and deserialization does not rely on reflection and meta-programming in C#, therefore it is orders of magnitude faster than JSON.NET or other polymorphic serialization techniques;
- Breaking protobuf wire compatibility is very difficult to do accidentally; and
- Protobuf messages compress really well, which provides bandwidth and storage savings.
If we take a look at the Protobuf definition for the Ask message from earlier:
message Ask{
string orderId = 1;
string stockId = 2;
double quantity = 3;
double price = 4; /* normally a decimal in C# - might have loss of precision here */
int64 timeIssued = 5;
}
This will be compiled into a C# type via the Protobuf compiler, and it could also be compiled into a compatible Java, C++, and many other language types. If I wanted to add that new “margin” field, I would just append that to the end of my message:
message Ask{
string orderId = 1;
string stockId = 2;
double quantity = 3;
double price = 4; /* normally a decimal in C# - might have loss of precision here */
int64 timeIssued = 5;
bool onMargin = 6;
}
Let’s compare how this works - on nodes with the updated protobuf Ask implementation, we would deserialize the onMargin property as expected and we’d translate it back into the Akka.CQRS.Events.Ask type (with the OnMargin property) that we showed earlier. On nodes who received this updated protobuf version of Ask, but weren’t running the updated protobuf definition themselves, they would simply ignore the onMargin property as though it didn’t exist and re-create the Akka.CQRS.Events.Ask message without the OnMargin property, because the old node doesn’t have that version of the type. This is where we want to be: version tolerance. Once all of the nodes in our cluster are updated with the latest message definitions the message-processing behavior will be consistent everywhere, but the act of rolling out the update will no longer compromise our availability.
Embracing Extend-Only Design with Protocol Buffers
The fundamental path to versioning any system well is to embrace “extend-only” design, or in the words of the Protocol Buffer C# Language Guide:
Sooner or later after you release the code that uses your protocol buffer, you will undoubtedly want to “improve” the protocol buffer’s definition. If you want your new buffers to be backwards-compatible, and your old buffers to be forward-compatible – and you almost certainly do want this – then there are some rules you need to follow. In the new version of the protocol buffer:
- you must not change the tag numbers of any existing fields.
- you may delete fields.
- you may add new fields but you must use fresh tag numbers (i.e. tag numbers that were never used in this protocol buffer, not even by deleted fields).
If you follow these rules, old code will happily read new messages and simply ignore any new fields. To the old code, singular fields that were deleted will simply have their default value, and deleted repeated fields will be empty. New code will also transparently read old messages.
In other words, never change the meaning or the required elements of an existing version of a message. No renaming fields. No changing their types. You should only ever add new content to an existing message type and stop using content that you no longer need going forward.
This is a technique that SQL DBAs have practiced with table schema for decades and it’s central to how file format preservation for most desktop applications works. Now, we’re going to apply it to our wire and persistence formats as well.
Implementing Protobuf Serialization in Akka.NET
Let’s take a look at the full /src/protobuf/Akka.Cqrs.proto file in the solution:
syntax = "proto3";
package Akka.CQRS.Serialization.Msgs;
enum TradeEvent{
BID = 0;
ASK = 1;
FILL = 2;
MATCH = 3;
}
/* Trading events */
message Bid{
string orderId = 1;
string stockId = 2;
double quantity = 3;
double price = 4; /* normally a decimal in C# - might have loss of precision here */
int64 timeIssued = 5;
}
message Ask{
string orderId = 1;
string stockId = 2;
double quantity = 3;
double price = 4; /* normally a decimal in C# - might have loss of precision here */
int64 timeIssued = 5;
}
message Fill{
string orderId = 1;
string stockId = 2;
double quantity = 3;
double price = 4; /* normally a decimal in C# - might have loss of precision here */
int64 timeIssued = 5;
string filledById = 6;
bool partialFill = 7;
}
message Match{
string stockId = 1;
string buyOrderId = 2;
string sellOrderId = 3;
double quantity = 4;
double price = 5; /* normally a decimal in C# - might have loss of precision here */
int64 timeIssued = 6;
}
/* used in Order structs */
enum TradeSide{
BUY = 0;
SELL = 1;
}
message Order{
string orderId = 1;
string stockId = 2;
TradeSide side = 3;
double quantity = 4;
double price = 5; /* normally a decimal in C# - might have loss of precision here */
int64 timeIssued = 6;
repeated Fill fills = 16;
}
message OrderbookSnapshot{
string stockId = 1;
int64 timeIssued = 2;
double askQuantity = 3;
double bidQuantity = 4;
repeated Order asks = 5;
repeated Order bids = 6;
}
message GetOrderbookSnapshot{
string stockId = 1;
}
message GetRecentMatches{
string stockId = 1;
}
NOTE: covering the particulars of Protobuf3 syntax is outside of the scope of this course, but you can familiarize yourself with it here.
All of these constructs define message types and enums that can be used to create cross-platform, highly compressed binary messages that we’re going to use to represent the commands and events defined in the Akka.CQRS library - and in order to do that we need to run the Protobuf compiler.
As fate would have it, if you run the build.ps1 script in the root of the repository this will download the Google.Protobuf.Tools package, which contains the protoc protobuf compiler.
We can run this compiler on all of our .proto definitions stored in the /src/protobuf folder.
Please run the following command:
PS> ./build.cmd protobuf
For reference, here’s the code from our build.fsx script that actually executes the protoc.exe commandline:
Target "Protobuf" <| fun _ ->
let protocPath =
if isWindows then findToolInSubPath "protoc.exe" "tools/Google.Protobuf.Tools/tools/windows_x64"
elif isMacOS then findToolInSubPath "protoc" "tools/Google.Protobuf.Tools/tools/macosx_x64"
else findToolInSubPath "protoc" "tools/Google.Protobuf.Tools/tools/linux_x64"
let protoFiles = [
("Akka.Cqrs.proto", "/src/Akka.CQRS/Serialization/Proto/")
("Akka.Cqrs.Pricing.proto", "/src/Akka.CQRS.Pricing/Serialization/Proto") ]
printfn "Using proto.exe: %s" protocPath
let runProtobuf assembly =
let protoName, destinationPath = assembly
let args = StringBuilder()
|> append (sprintf "-I=%s" (__SOURCE_DIRECTORY__ @@ "/src/protobuf/") )
|> append (sprintf "--csharp_out=internal_access:%s" (__SOURCE_DIRECTORY__ @@ destinationPath))
|> append "--csharp_opt=file_extension=.g.cs"
|> append (__SOURCE_DIRECTORY__ @@ "/src/protobuf" @@ protoName)
|> toText
let result = ExecProcess(fun info ->
info.FileName <- protocPath
info.WorkingDirectory <- (Path.GetDirectoryName (FullName protocPath))
info.Arguments <- args) (System.TimeSpan.FromMinutes 45.0) (* Reasonably long-running task. *)
if result <> 0 then failwithf "protoc failed. %s %s" protocPath args
protoFiles |> Seq.iter (runProtobuf)
This will generate two C# files:
/src/Akka.CQRS/Serialization/Proto/AkkaCqrs.g.cs- all types will be generated in the Akka.CQRS.Serialization.Msgs namespace./src/Akka.CQRS.Pricing/Serialization/Proto/AkkaCqrsPricing.g.cs- all types will be generated in the Akka.CQRS.Pricing.Serialization.Msgs namespace.
In order for us to actually make use of the generated protobuf C# types in Akka.NET, we’re going to need to implement our own serializer by subclassing from the SerializerWithStringManifest base class - and that’s exactly what we’ve done with the Akka.CQRS.Serialization.TradeEventSerializer class, which is currently commented out:
public sealed class TradeEventSerializer : SerializerWithStringManifest
{
public static readonly IEnumerable<Order> EmptyOrders = new Order[0];
public static Config Config { get; }
static TradeEventSerializer()
{
Config = ConfigurationFactory.FromResource<TradeEventSerializer>(
"Akka.CQRS.Serialization.TradeEventSerializer.conf");
}
public TradeEventSerializer(ExtendedActorSystem system) : base(system)
{
}
public override int Identifier => 517;
public override byte[] ToBinary(object obj)
{
switch (obj)
{
case Order ord:
return ToProto(ord).ToByteArray();
case Ask a:
return ToProto(a).ToByteArray();
case Bid b:
return ToProto(b).ToByteArray();
case Fill f:
return ToProto(f).ToByteArray();
case Match m:
return ToProto(m).ToByteArray();
case OrderbookSnapshot snap:
return ToProto(snap).ToByteArray();
case GetOrderBookSnapshot go:
return ToProto(go).ToByteArray();
case GetRecentMatches grm:
return ToProto(grm).ToByteArray();
default:
throw new SerializationException($"Type {obj.GetType()} is not supported by this serializer.");
}
}
public override object FromBinary(byte[] bytes, string manifest)
{
switch (manifest)
{
case "O":
return FromProto(Msgs.Order.Parser.ParseFrom(bytes));
case "A":
return FromProto(Msgs.Ask.Parser.ParseFrom(bytes));
case "B":
return FromProto(Msgs.Bid.Parser.ParseFrom(bytes));
case "F":
return FromProto(Msgs.Fill.Parser.ParseFrom(bytes));
case "M":
return FromProto(Msgs.Match.Parser.ParseFrom(bytes));
case "OBS":
return FromProto(Msgs.OrderbookSnapshot.Parser.ParseFrom(bytes));
case "GOBS":
return FromProto(Msgs.GetOrderbookSnapshot.Parser.ParseFrom(bytes));
case "GRM":
return FromProto(Msgs.GetRecentMatches.Parser.ParseFrom(bytes));
default:
throw new SerializationException($"Type {manifest} is not supported by this serializer.");
}
}
public override string Manifest(object o)
{
switch (o)
{
case Order ord:
return "O";
case Ask a:
return "A";
case Bid b:
return "B";
case Fill f:
return "F";
case Match m:
return "M";
case OrderbookSnapshot snap:
return "OBS";
case GetOrderBookSnapshot go:
return "GOBS";
case GetRecentMatches grm:
return "GRM";
default:
throw new SerializationException($"Type {o.GetType()} is not supported by this serializer.");
}
}
internal static Msgs.GetRecentMatches ToProto(GetRecentMatches g)
{
return new Msgs.GetRecentMatches(){ StockId = g.StockId};
}
internal static GetRecentMatches FromProto(Msgs.GetRecentMatches g)
{
return new GetRecentMatches(g.StockId);
}
// rest of methods
}
Uncomment the code inside the TradeSerializer.cs file before moving on.
The way this serializer works: for each message type we generate a string “manifest” - a short-hand that represents the type of message being sent over the wire in Akka.Remote or being saved to the database in Akka.Persistence. We save the manifest AND the Serializer.Identifer number of the serializer who generated that manifest together in the payloads managed by Akka.Remote and Akka.Persistence - that way the party who receives this message can use the same serializer and provide the same manifest as a hint to the serializer for how to deserialize this message from its binary representation back into a CLR type.
This design only works if the Serializer.Identifer numbers and Akka.NET serializer bindings are consistent on both sides of the wire, which we’ll now do by updating the Akka.CQRS/Serialization/TradeEventSerializer.conf HOCON config file to read like the following:
# Protobuf serializer for IWithTrace messages
akka.actor {
serializers {
trade-events = "Akka.CQRS.Serialization.TradeEventSerializer, Akka.CQRS"
}
serialization-bindings {
"Akka.CQRS.ITradeEvent, Akka.CQRS" = trade-events
}
serialization-identifiers {
"Akka.CQRS.Serialization.TradeEventSerializer, Akka.CQRS" = 517
}
}
This HOCON will be parsed automatically via the TradeEventSerializer.Config static property. The way the TradeEventSerialzier works is that it translates between the Protobuf-generated C# classes in the Akka.CQRS.Serialization.Msgs and the Akka.CQRS.Events namespace - that’s what all of the ToProto and FromProto static methods in this class do.
As for the serializer HOCON configuration, here’s what this does:
- Registers the
TradeEventSerializerunder thetrade-eventsshort-hand name; - Tells Akka.NET to serialize all
ITradeEventinterface messages marked with theTradeEventSerializer; and - Registers the
TradeEventSerializerwith a serialization ID of 517, which is also the hard-coded value built into the class itself. The ID number is arbitrary - but you just have to use an ID that isn’t already used by another serializer. IDs 1-100 are reserved for Akka.NET, but 101-999 are free for end-users to use.
The last thing we need to do is actually load this serializer inside our ActorSystems, and we can do this with a code update to Akka.CQRS.Infrastructure/AppBoostrap.cs:
config = config
.WithFallback(GetOpsConfig())
//.WithFallback(TradeEventSerializer.Config)
//.WithFallback(ClusterSharding.DefaultConfig())
//.WithFallback(DistributedData.DistributedData.DefaultConfig()) // needed for DData sharding
//.WithFallback(ClusterClientReceptionist.DefaultConfig())
//.WithFallback(DistributedPubSub.DefaultConfig())
.BootstrapFromDocker();
Uncomment the .WithFallback(TradeEventSerializer.Config) call before moving on.
Once this config is loaded via the AppBootstrap class then all of our ActorSystems will be able to process messages using the TradeEventSerializer without any issues. Any messages sent via Akka.Remote or Akka.Persistence that implement the IWithTrade interface will be serialized using these protobuf formats we’ve created.
Bonus Exercise: We currently don’t have a matching serializer for the Akka.CQRS.Pricing.Events, even though we have a valid protobuf definition for those events. Could you create a serializer for it?
Next
Now that we have tighter control over our message versioning and management of cluster member, it’s time to move onto: Lesson 4 - Advanced Akka.Cluster Techniques: DistributedPubSub, Sharding, and ClusterClient