.NET 7.0's Performance Improvements with Dynamic PGO are Incredible
Akka.Remote is 33% faster, Akka.NET v1.5 is 75% faster in-memory.
16 minutes to read- Dynamic Profile-Guided Optimization
- What Can PGO Optimize?
- Akka.NET v1.5 on .NET 7.0 with Dynamic PGO (Concurrency Impact on PGO)
.NET 7.0 was released to market last week and includes hundreds of major improvements across the board.
I ran Akka.NET’s RemotePingPong benchmark on .NET 7.0 shortly after installing the .NET 7.0 SDK - I’ll take every free lunch I can from the CoreCLR team.
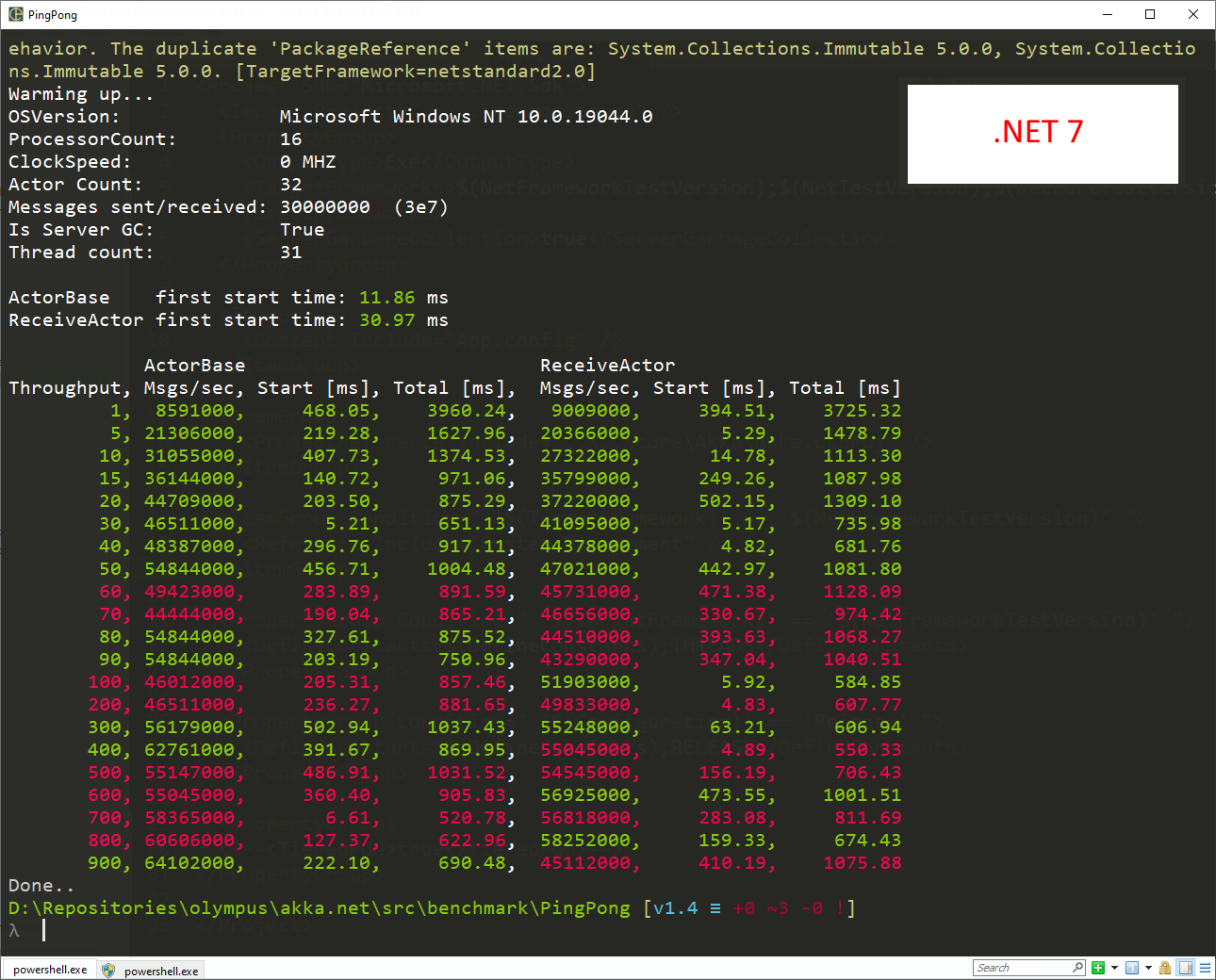
Here’s how the numbers compare between .NET 6.0 and .NET 7.0 for RemotePingPong:
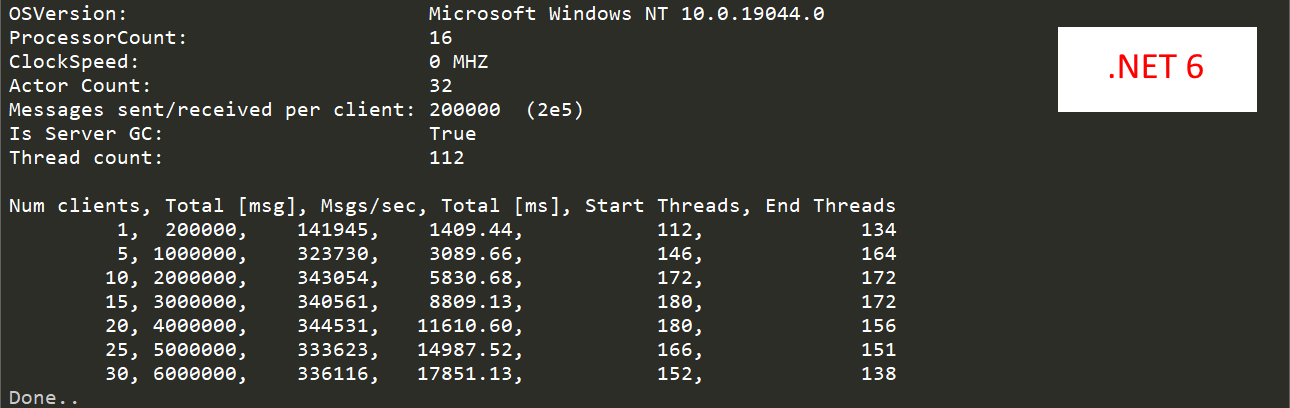
Akka.NET v1.4.45 performs at roughly 340,000 msg/s on my Gen 1 AMD Ryzen machine built in 2017.
The results on .NET 7.0:
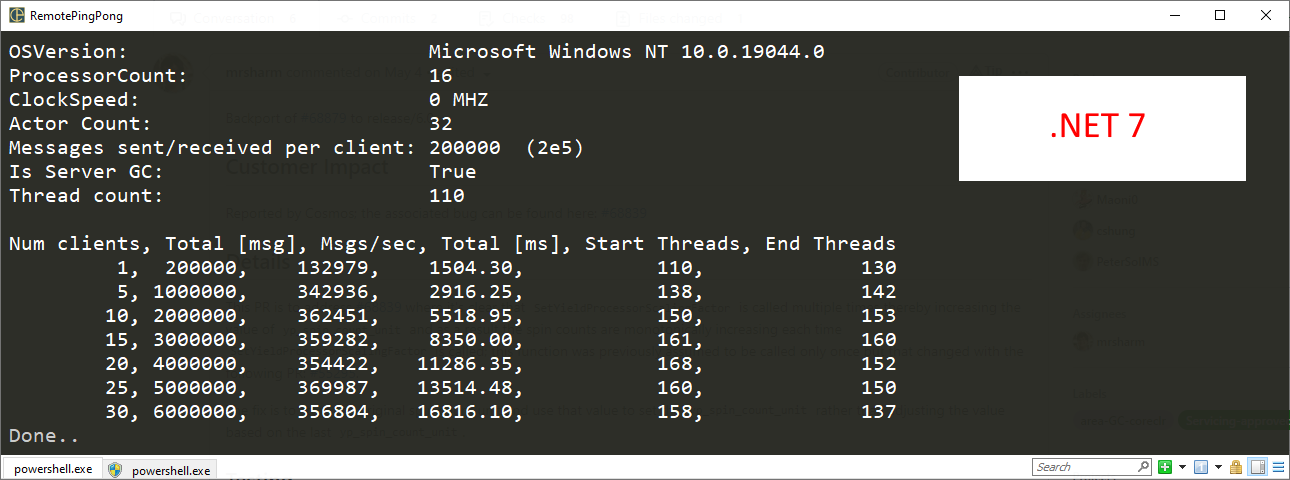
360,000 msg/s, a roughly 10% improvement. Not bad.
After posting the results on Twitter another Akka.NET user suggested that I try re-running the benchmark with Dynamic Profile-Guided Optimization (PGO) enabled, which received significant investment in .NET 7.0.
Have you turned on dynamic pgo?
— Onur Gümüş (@OnurGumusDev) November 11, 2022
The results? A shocking 33% improvement over .NET 6.0.
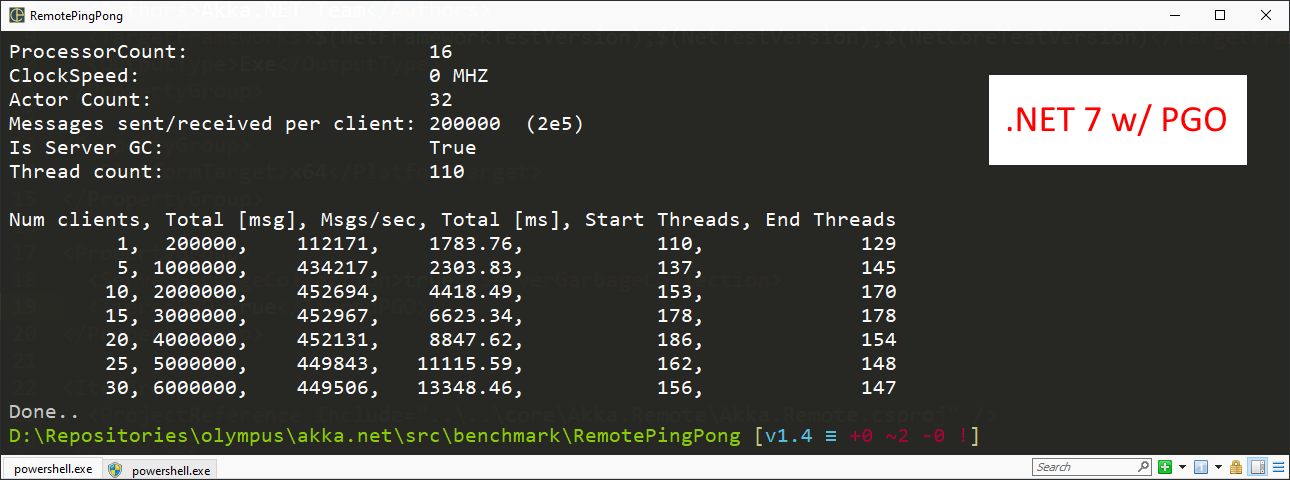
A shocking ~450,000 msg/s - all in exchange for doing basically nothing other than adding the following line to my .csproj files for the benchmark:
<PropertyGroup>
<TieredPGO>true</TieredPGO>
</PropertyGroup>
What’s going on with Dynamic PGO in .NET 7.0?!?
Dynamic Profile-Guided Optimization
Profile-Guided Optimization (PGO) is a compiler optimization technique that collects data on how a specific program executes and subsequently feeds that information into the compiler’s optimization process.
N.B. - I go into this in more details in the corresponding YouTube video “NET 7.0 Performance Improvements with Dynamic PGO are Incredible”.
There are two flavors of PGO used by the .NET Just-in-Time (JIT) compiler:
- Static PGO: these are optimization decisions that are made before the program runs based on its past performance - this can be used to help reduce program startup time, optimize symbols for shared libraries, and so on.
- Dynamic PGO: this is the big deal in .NET 7.0. Dynamic PGO allows the JIT to use profiling data to change the way code is compiled in the background at runtime, meaning that the code’s execution performance will change as the JIT utilizes information collected as a single instance of an application runs.
You can see from the PerfView data I gathered that the JIT is much more active when Dynamic PGO is enabled versus when it is not. This data is gathered using our in-memory messaging benchmark, PingPong.
.NET 7.0 JIT Stats without PGO
| Jitting Trigger | Num Compilations | % of total jitted compilations | Jit Time msec | Jit Time (% of total process CPU) |
|---|---|---|---|---|
| TOTAL | 4814 | 100.0 | 2054.1 | 0.5 |
| Foreground | 2232 | 46.4 | 434.1 | 0.1 |
| Multicore JIT Background | 0 | 0.0 | 0.0 | 0.0 |
| Tiered Compilation Background | 2582 | 53.6 | 1619.9 | 0.4 |
.NET 7.0 JIT Stats with PGO
| Jitting Trigger | Num Compilations | % of total jitted compilations | Jit Time msec | Jit Time (% of total process CPU) |
|---|---|---|---|---|
| TOTAL | 4793 | 100.0 | 3113.0 | 1.1 |
| Foreground | 2232 | 46.6 | 777.1 | 0.3 |
| Multicore JIT Background | 0 | 0.0 | 0.0 | 0.0 |
| Tiered Compilation Background | 2561 | 53.4 | 2335.9 | 0.8 |
Tradeoffs
From the data above we can see that the JIT on .NET 7.0 without PGO only used ~2s of total computation time and 0.5% of CPU. With Dynamic PGO enabled the .NET JIT took 3.1s of total computation time (30% increase) and 1.1% of total CPU (205% increase).
If I dug through the PerfView data more closely I suspect that the Dynamic PGO JIT results would also include larger allocation sizes too.
However, the benefits realized from enabling Dynamic PGO vastly outweigh the costs in our case - the extra second of JIT time was overcome by shaving off 10s of seconds from our benchmark throughput cumulatively.
What Can PGO Optimize?
We have a second benchmark in the Akka.NET project that we use for trying to measure the overhead of our dispatching system and actor base class overhead: PingPong.
This benchmark spins up 32 actors and increases the dispatcher.throughput value during each run - the greater the throughput value, the less context-switching (I explain this in “.NET Systems Programming Learned the Hard Way”), but there are some tradeoffs: when the throughput value grows too large we start seeing signs of actor starvation.
PingPong compares the performance, at each throughput run of two different actor types:
ActorBase- the most absolute bare-bones, no-frills actor type in Akka.NET;ReceiveActor- a strongly typed actor that usesReceive<T>delegates and predicates to improve the developer experience and ease-of-use of Akka.NET.
In terms of raw throughput the ActorBase should be faster since it has fewer moving parts, but due to some clever performance optimizations made to the ReceiveActor (delegate compilation and caching) the performance has always been pretty much dead even by our measurements over the years.
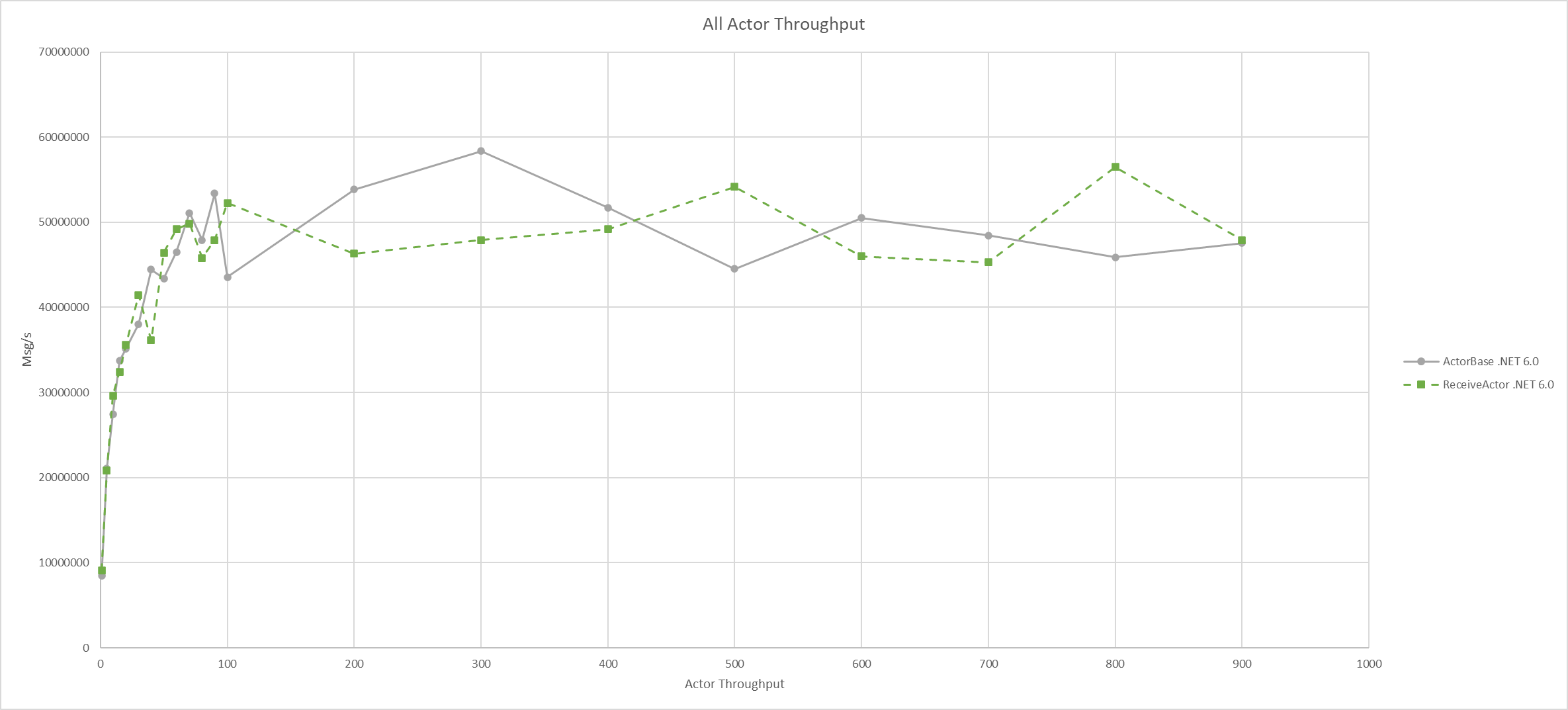
Here’s what the performance graphs of these actors on PingPong look like for both .NET 6.0 and .NET 7.0:
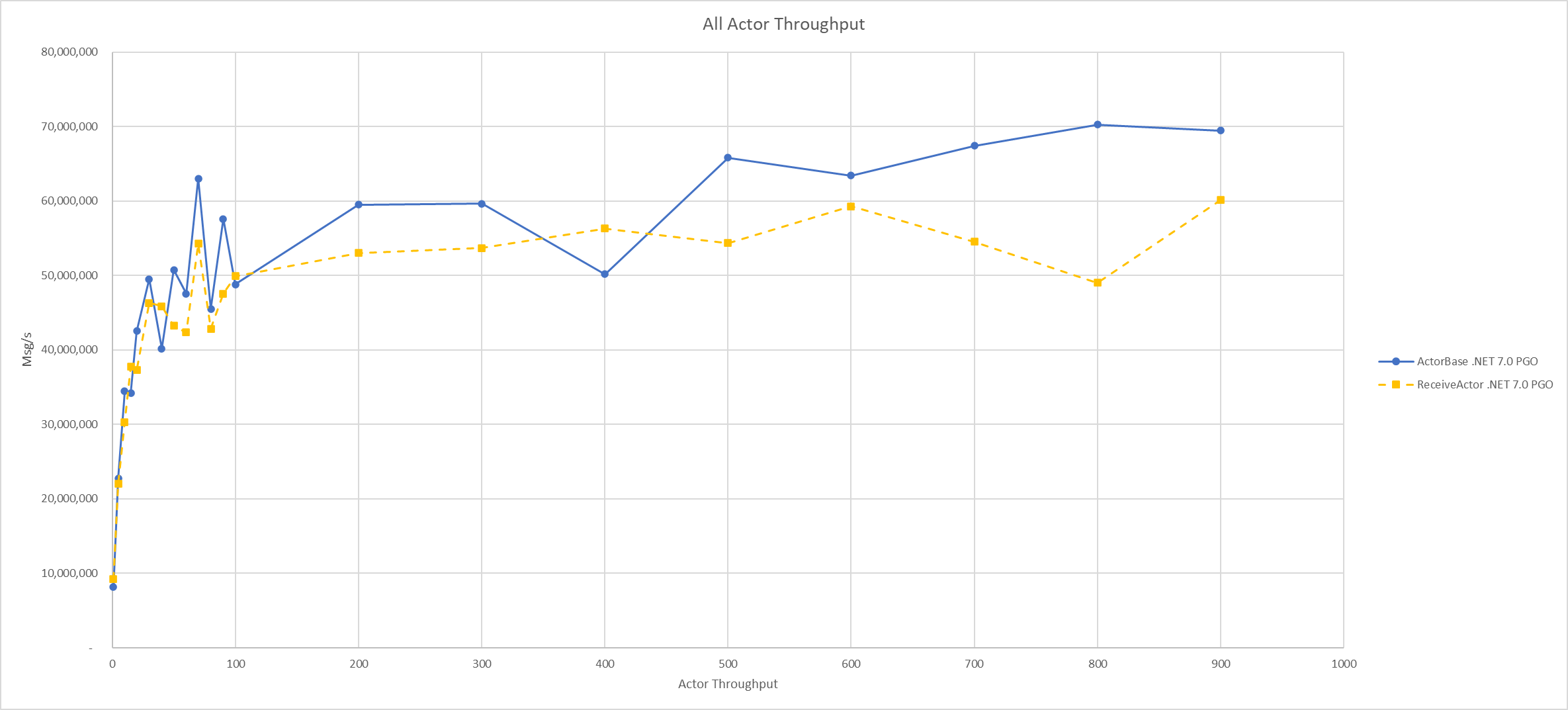
PGO Impact: ActorBase vs. ReceiveActor
On .NET 6.0, the maximum throughput of the ActorBase and ReceiveActor both peak around 58 million messages per second.
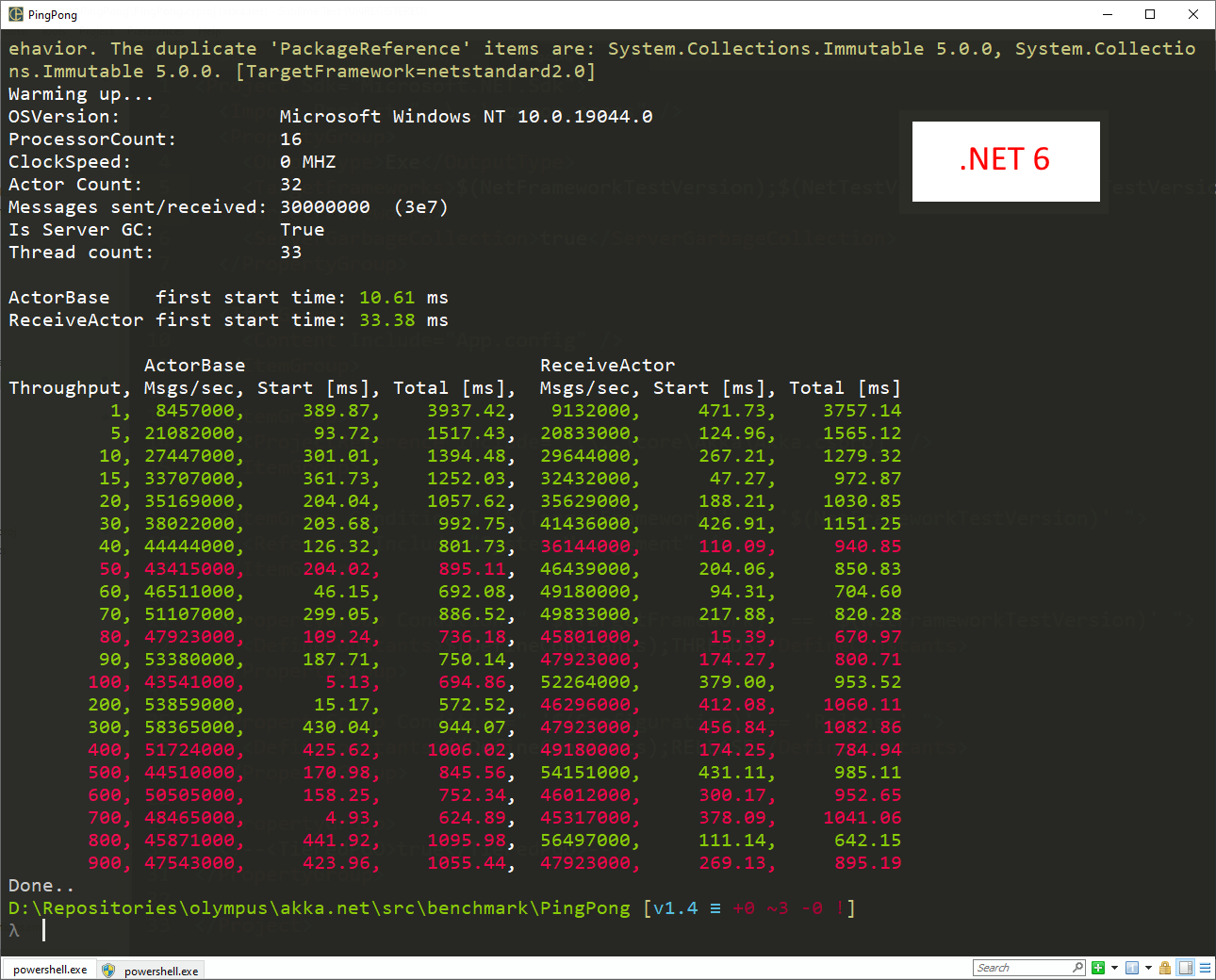
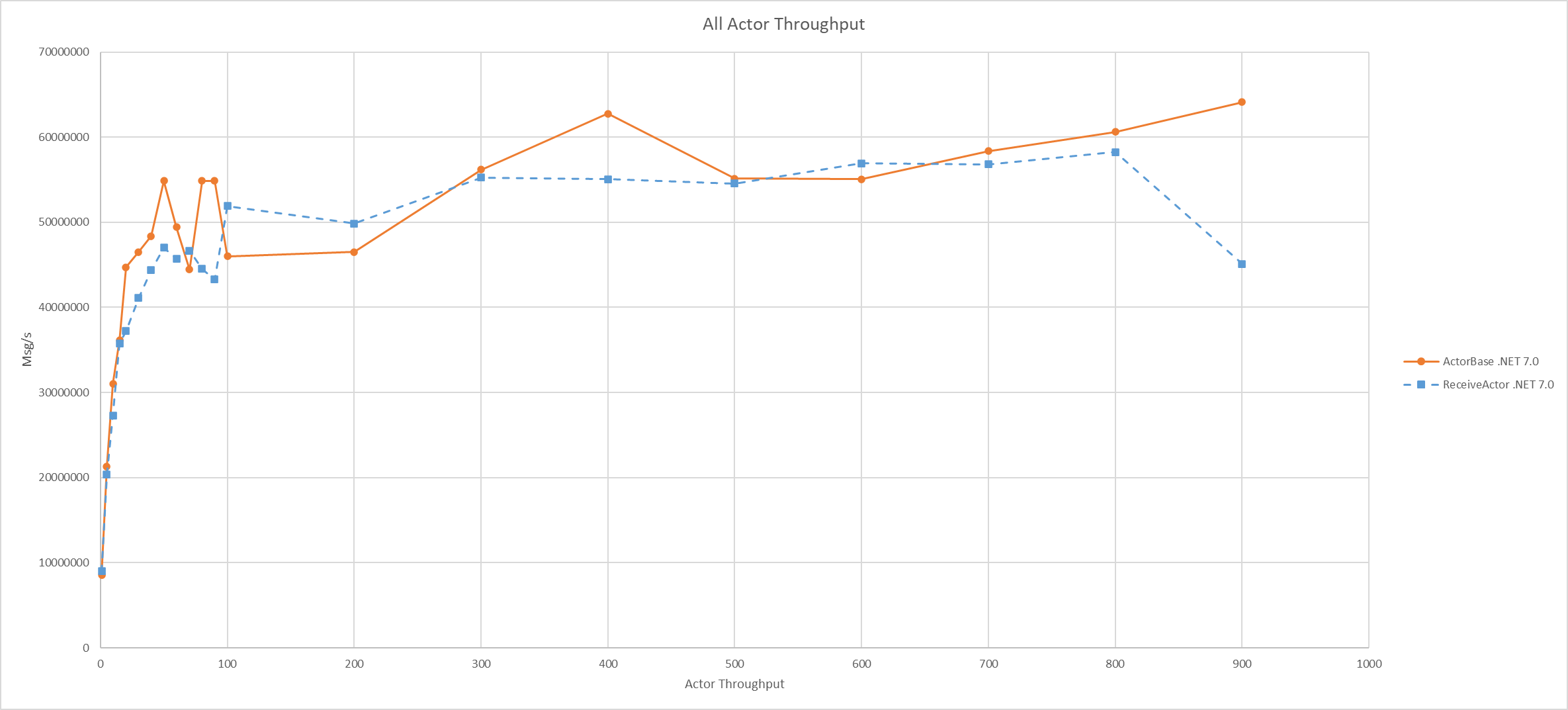
On .NET 7.0 - about 64 million messages per second, a roughly 10% improvement over .NET 6.0.
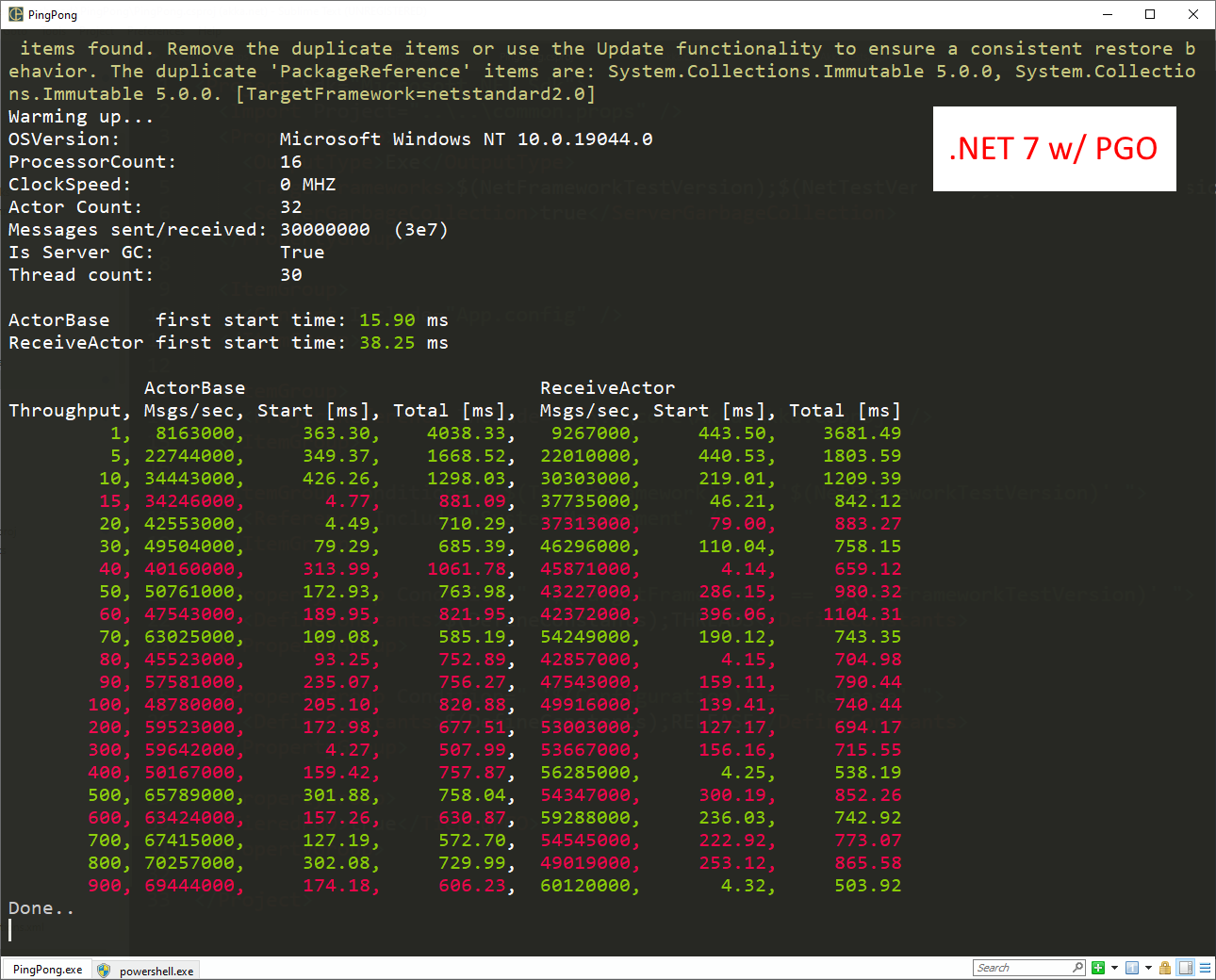
On .NET 7.0 with Dynamic PGO enabled - 70 million messages per second for the ActorBase, a ~20% improvement over .NET 6.0. But the ReceiveActor performance is about the same as it was without PGO enabled. Hmmm.
If we put the raw numbers into a plot, we can see that on .NET 7.0 and .NET 6.0 without PGO the performance numbers are pretty comparable between the two actor implementations.
.NET 6.0
.NET 7.0
.NET 7.0 with PGO
But with Dynamic PGO enabled on .NET 7.0, we can see a clear divergence in performance - the ActorBase consistently outperforms the ReceiveActor minus one outlier:
Why the Divergence?
Why does the ActorBase now suddenly outperform the ReceiveActor after years of demonstrable parity between the two?
I think the answer lies in how simple the underlying implementations are:
public class ClientActorBase : ActorBase
{
private readonly IActorRef _actor;
private readonly TaskCompletionSource<bool> _latch;
private long _received;
private readonly long _repeat;
private long _sent;
public ClientActorBase(IActorRef actor, long repeat,
TaskCompletionSource<bool> latch)
{
_actor = actor;
_repeat = repeat;
_latch = latch;
}
protected override bool Receive(object message)
{
if(message is Messages.Msg)
{
_received++;
if(_sent < _repeat)
{
_actor.Tell(message);
_sent++;
}
else if(_received >= _repeat)
{
// Console.WriteLine("done {0}", Self.Path);
_latch.SetResult(true);
}
return true;
}
if(message is Messages.Run)
{
var msg = new Messages.Msg();
for(int i = 0; i < Math.Min(1000, _repeat); i++)
{
_actor.Tell(msg);
_sent++;
}
return true;
}
if(message is Messages.Started)
{
Sender.Tell(message);
return true;
}
return false;
}
}
The ClientActorBase uses simple pattern matching using built-in language constructs - this could be refactored to use a switch statement, but the original structure of the code predates C#7 when that was introduced.
The ClientReceiveActor, on the other hand:
public class ClientReceiveActor : ReceiveActor
{
public ClientReceiveActor(IActorRef actor, long repeat, TaskCompletionSource<bool> latch)
{
var received=0L;
var sent=0L;
Receive<Messages.Msg>(m =>
{
received++;
if(sent < repeat)
{
actor.Tell(m);
sent++;
}
else if(received >= repeat)
{
latch.SetResult(true);
}
});
Receive<Messages.Run>(r =>
{
var msg = new Messages.Msg();
for(int i = 0; i < Math.Min(1000, repeat); i++)
{
actor.Tell(msg);
sent++;
}
});
Receive<Messages.Started>(s => Sender.Tell(s));
}
}
Why, that looks even simpler than the ActorBase implementation! Very clean, easy to read, etc… But here’s what’s going on underneath the covers:
public void Match<T>(Action<T> handler, Predicate<T> shouldHandle = null) where T : TItem
{
EnsureCanAdd();
var handlesType = typeof(T);
AddHandler(handlesType, PredicateAndHandler.CreateAction(handler, shouldHandle));
if(handlesType == _itemType && shouldHandle == null)
_state = State.MatchAnyAdded;
}
private void AddHandler(Type handlesType, PredicateAndHandler predicateAndHandler)
{
TypeHandler typeHandler;
//if the previous handler handles the same type, we don't need an entirely new TypeHandler,
//we can just add the handler to its' list of handlers
if(!TryGetPreviousTypeHandlerIfItHandlesSameType(handlesType, out typeHandler))
{
//Either no previous handler had been added, or it handled a different type.
//Create a new handler and store it.
typeHandler = new TypeHandler(handlesType);
_typeHandlers.Add(typeHandler);
//The type is part of the signature
_signature.Add(handlesType);
}
//Store the handler (action or func), the predicate the type of handler
typeHandler.Handlers.Add(predicateAndHandler);
//The kind of handler (action, action+predicate or fun) is part of the signature
_signature.Add(predicateAndHandler.HandlerKind);
//Capture the handler (action or func) and the predicate if specified
_arguments.AddRange(predicateAndHandler.Arguments);
}
We are performing code emission, delegate compilation, pre-calculation of matching types, and caching of compiled delegates in their respective matching orders internally. This code was written in the era of .NET Framework 4.5 and was state of the art.
However, all of these clever constructs we created to outsmart a much simpler .NET runtime and JIT compiler are now self-defeating in an era where the JIT can simply do it better.
As Rich Lander, one of the senior members of the CoreCLR team put it on Twitter:
"God grant me the serenity to realize that .NET is a cloud runtime and that the light of the JIT angel warms me and reveals the path of virtue I will take."
— Rich Lander (@runfaster2000) November 12, 2022
Stephen Toub shares the word on this ...https://t.co/rb3rxI4iiN pic.twitter.com/6yo560Mkf2
With Akka.NET’s internals we will need to literally go back to basics in light of these JIT improvements - clever optimizations don’t benefit from underlying runtime improvements anymore. Simpler is better.
Akka.NET v1.5 on .NET 7.0 with Dynamic PGO (Concurrency Impact on PGO)
All of the data we’ve presented so far has been using Akka.NET v1.4.45, which is the current stable version of Akka.NET - what about the alphas of Akka.NET v1.5 that are under active development?
Akka.NET v1.5 includes a significant performance improvement we can observe in our PingPong benchmarks:
Add IThreadPoolWorkItem support to ThreadPoolDispatcher
- this change uses newer .NET APIs that allow actors to significantly reduce the amount of context switching. We can observe how significant that is in terms of overall performance in our .NET 7.0 PingPong results using Akka.NET v1.5:
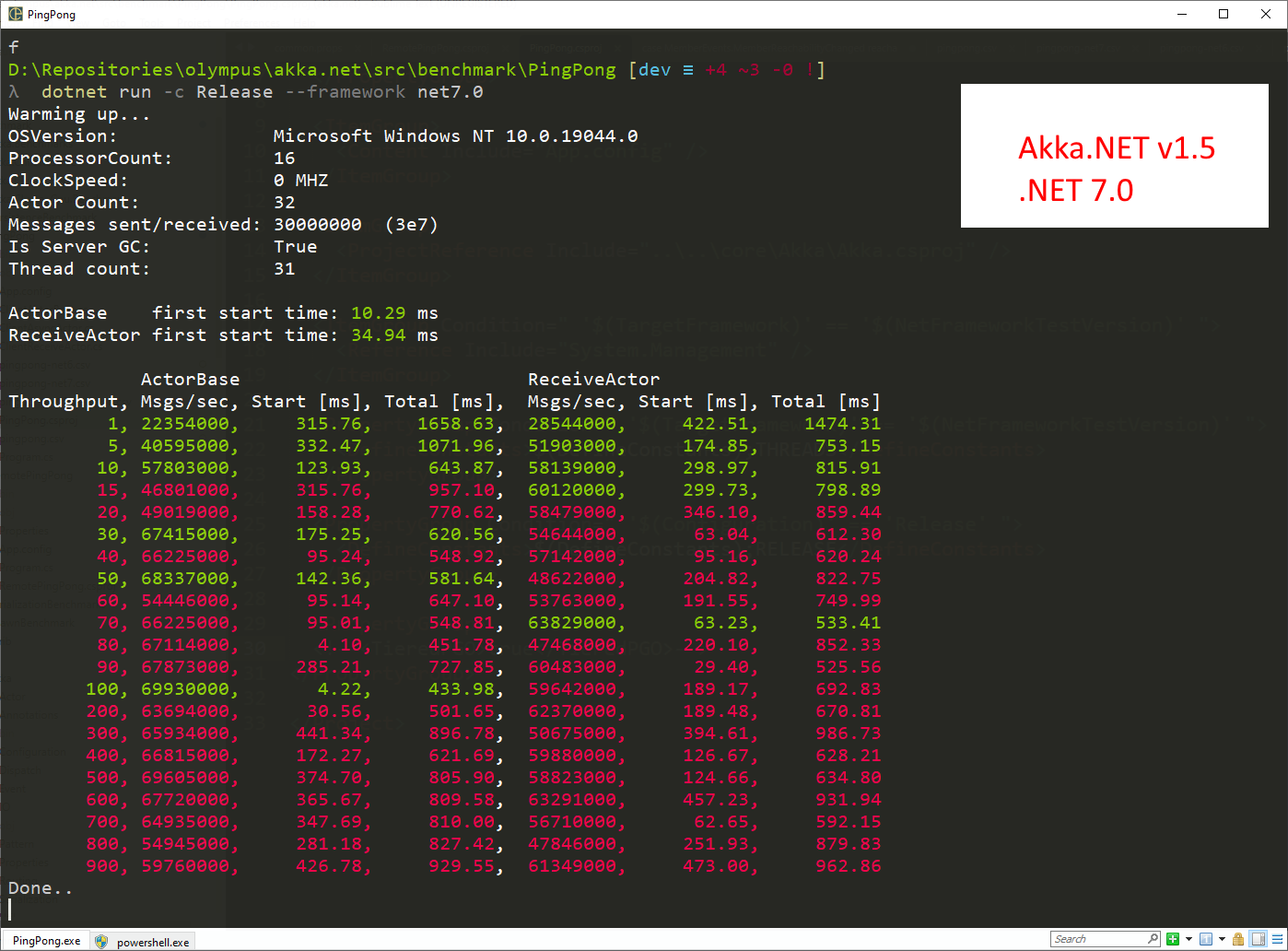
Approximately 70m messages per second for ActorBase and 64m for ReceiveActor - not bad. This performance is on-par with Akka.NET v1.4 on .NET 7.0 with PGO enabled.
What happens if we enable Dynamic PGO on Akka.NET v1.5?
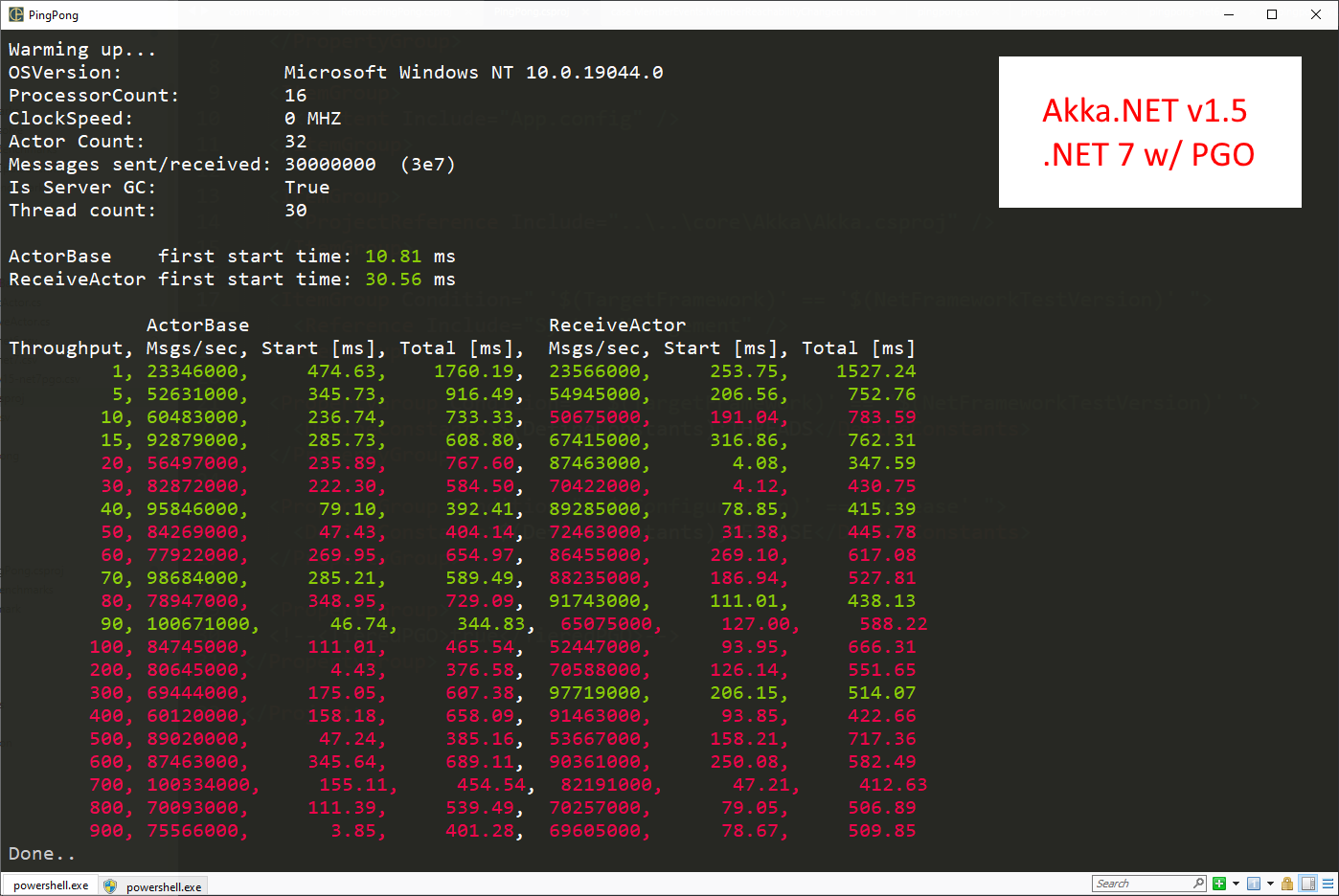
100m messages per second for ActorBase and 97m messages per second for ReceiveActor - a 75% improvement over Akka.NET v1.4 on .NET 6.0. That is incredible!
Here is what I suspect is happening here: tiered JIT compilation and PGO perform are able to gather more accurate data or generate more effective improvements when the same code is being executed on the same CPUs over and over again. I haven’t verified this by looking at the generated code myself or digging through the PerfView events, but that’s my armchair quarterback take.
.NET 7.0 is a very exciting development for Akka.NET users and .NET users alike - I strongly encourage you all to consider upgrading to it ASAP.
If you liked this post, you can share it with your followers or follow us on Twitter!
- Read more about:
- Akka.NET
- Case Studies
- Videos
Observe and Monitor Your Akka.NET Applications with Phobos
Did you know that Phobos can automatically instrument your Akka.NET applications with OpenTelemetry?
Click here to learn more.