Akka.NET + Kubernetes: Everything You Need to Know
Production lessons from years of running Akka.NET clusters at scale
37 minutes to read- Why Akka.NET and Kubernetes Are a Great Match
- The Big Decision: StatefulSets vs. Deployments
- Configuring Akka.NET for Kubernetes
- RBAC: Giving Pods Permission to Discover Each Other
- Health Checks: Liveness vs. Readiness
- Securing Akka.Remote with TLS Certificates
- Using Petabridge.Cmd as a Sidecar Container
- Graceful Shutdowns and terminationGracePeriodSeconds
- Pod Resource Limits and Horizontal Pod Autoscaling
- Putting It All Together
Running Akka.NET in Kubernetes can feel like a daunting task if you’re doing it for the first time. Between StatefulSets, Deployments, RBAC permissions, health checks, and graceful shutdowns, there are a lot of moving parts to get right.
But here’s the thing: once you understand how these pieces fit together, Kubernetes actually makes running distributed Akka.NET applications significantly easier than trying to orchestrate everything yourself using ARM templates, bicep scripts, or some other manual approach.
We’ve been running Akka.NET clusters in Kubernetes for years at Petabridge—both for our own products like Sdkbin and for customers who’ve built systems with over 1400 nodes. We’ve learned a lot the hard way, and this post is all about sharing those lessons so you don’t have to make the same mistakes we did.
This isn’t a hand-holding, step-by-step tutorial. Instead, I’m going to focus on the critical decisions you need to make, the pitfalls to avoid, and the best practices that actually matter when running Akka.NET in production on Kubernetes.
Why Akka.NET and Kubernetes Are a Great Match
Kubernetes gets an unfair amount of hate in the .NET community. People treat it like this impossibly complex piece of machinery when, in reality, it’s quite a bit simpler to work with than trying to manually orchestrate distributed applications using cloud-specific tools. But why is Kubernetes particularly well-suited for Akka.NET?
StatefulSets: Built for Stateful Applications
Kubernetes has a concept called a StatefulSet, which is specifically designed for applications that maintain state in memory. This is exactly what Akka.NET does with actors and Akka.Cluster.Sharding! StatefulSets provide several key benefits:
- Stable, reusable identities: Every pod in a StatefulSet has a predictable DNS name that persists across restarts
- Ordered, one-at-a-time updates: When you deploy a new version, StatefulSets replace pods sequentially rather than all at once
- No split-brain scenarios: Because updates happen gradually, you avoid the virtual IP swap problem where you suddenly have two separate clusters
These characteristics align perfectly with how stateful distributed systems need to operate.
Simplified Mesh Networking
Akka.NET, like Microsoft Orleans and other peer-to-peer frameworks, builds mesh networks where every node needs to communicate with every other node. In traditional cloud environments, setting this up involves:
- Configuring firewall rules so all processes in a deployment can communicate with each other
- Managing private networks with reachable address spaces between instances
- Coordinating security groups
- Fighting with VPN configurations
Kubernetes headless services make all of this trivial. They create an internal address space that allows pods to discover and communicate with each other seamlessly across multiple physical nodes. No additional firewall configuration required.
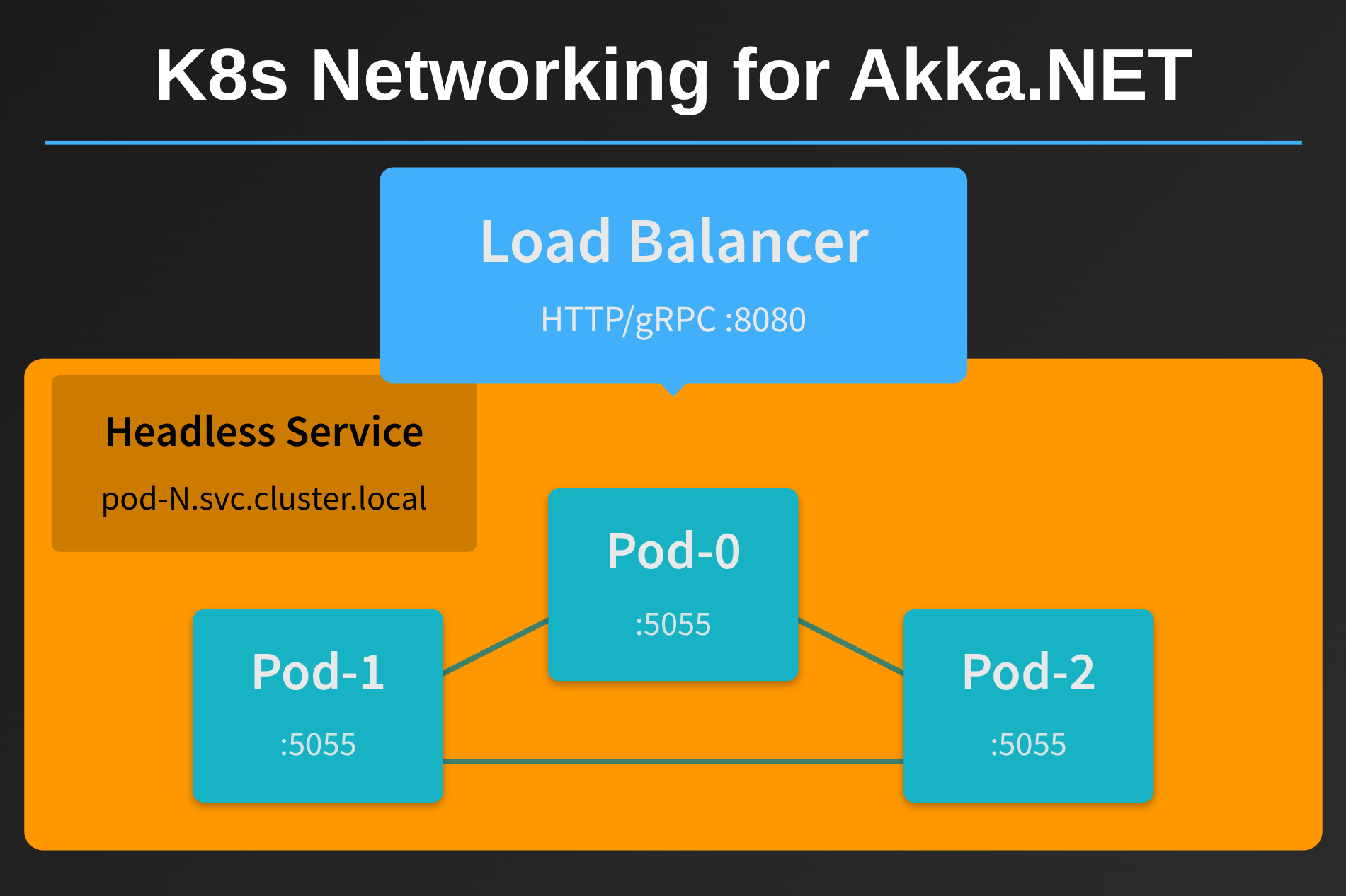
Graceful Transitions and Health Checks
One of the things I’ve really grown to appreciate about Kubernetes is how well it supports graceful transitions for stateful applications. When you’re shutting down an Akka.NET node, you don’t want to just pull the rug out from under it by instantly killing the process. There might be:
- In-flight messages being processed
- Cluster sharding rebalancing operations in progress
- Cluster singletons that have to be moved
- Persistence operations that need to complete
- State that needs to be handed off to another node
Kubernetes provides several mechanisms to support this:
terminationGracePeriodSeconds: Gives your application time to shut down cleanly- Readiness and liveness probes: Control when traffic starts and stops flowing to your pods
- Pre-stop hooks: Execute custom cleanup logic before termination
These features complement Akka.NET’s built-in graceful shutdown capabilities perfectly.
Zero-Downtime Rolling Upgrades
Kubernetes makes it very easy to orchestrate zero-downtime deployments. You introduce a new Docker image tag with your updated application, tell Kubernetes to use it, and configure your deployment strategy to gracefully introduce the new version. As long as your pods pass their health checks, the deployment continues. If they fail, the deployment stops and you can roll back.
This is exactly what Akka.NET applications need: controlled, gradual updates that don’t disrupt the cluster.
The Big Decision: StatefulSets vs. Deployments
When you’re setting up Akka.NET in Kubernetes, the first major decision you’ll face is whether to use StatefulSets or Deployments. Both work, but they have different tradeoffs that significantly impact how your cluster behaves during updates.

StatefulSet Advantages
Stable DNS Names: Each pod gets a predictable DNS name like drawtogether-0.drawtogether, drawtogether-1.drawtogether, etc. This makes seed-based cluster formation possible without Akka.Management.
Built-in Ordering: Updates happen sequentially, which can be useful for certain types of migrations or when you need strict ordering guarantees.
StatefulSet Disadvantages
Here’s where things get interesting. The biggest problem with StatefulSets is how they handle rolling updates - and somewhat ironically, they create significantly more cluster churn than you’d expect if you’re using Akka.Cluster.Sharding.
Let me show you what happens during a StatefulSet rolling update:
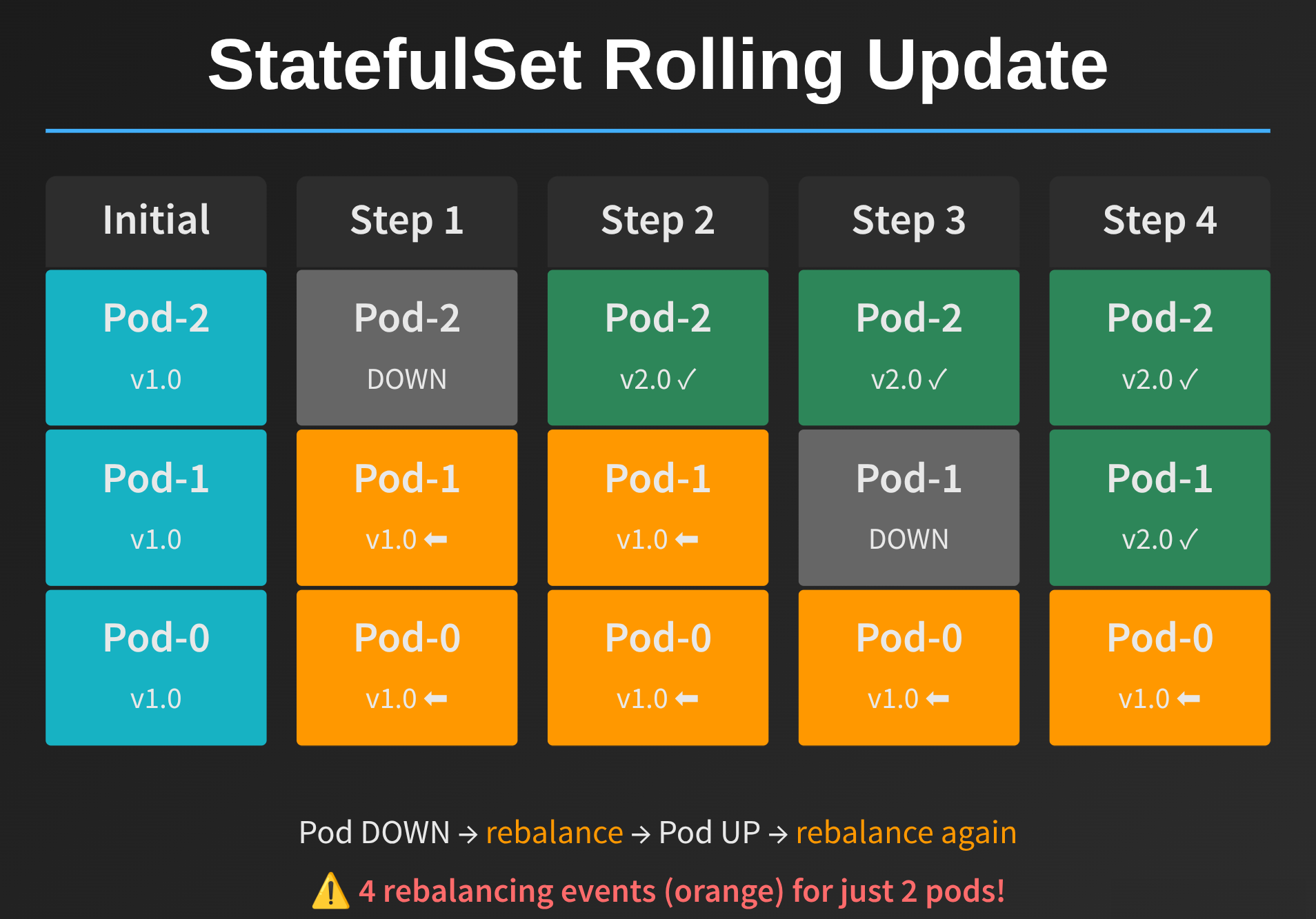
Notice the problem? Every pod gets rebalanced twice:
Pod-0leaves the cluster, all of its shards get instantly rebalanced to the surviving pods;Pod-0rejoins the cluster (with the new version);Pod-1leaves the cluster and rebalances all of its shards, which includes half of the original shards fromPod-0!Pod-1rejoins the cluster (with the new version); andPod-2leaves the cluster and forces an immediate rebalance of its shards, which includes all of the shards fromPod-0originally.
This puts tremendous pressure on Akka.Cluster.Sharding and creates a lot of unnecessary persistence / remoting activity.
The other major issue we ran into with StatefulSets at Petabridge: when deployments fail, you have to manually intervene to fix them. If a pod fails its liveness check during a rolling update, the StatefulSet update process just halts. You can’t easily do an automated rollback like you can with Deployments.
For us on Sdkbin, this usually happened because our init container (which applied Entity Framework Core migrations) would fail, not because of Akka.NET itself. But regardless of the cause, having to manually fix failed StatefulSet updates in the middle of the night isn’t fun.
Deployment Advantages
Gentler Rolling Updates: Deployments use a “surge” strategy where they temporarily spin up additional pods with the new version before terminating old pods. This creates much less cluster churn:

Because the new pod comes online before the old pod terminates, most shards just get transferred directly from the old pod to its replacement. Notice how there are only 2 rebalancing events (shown in orange) compared to 4 with StatefulSets. Much cleaner.
Easy Rollbacks: If a deployment fails, Kubernetes can automatically roll back to the previous version. You don’t need manual intervention.
Better for Dynamic Scheduling: If you’re using tools like Karpenter to move pods to spot instances or optimize resource usage, Deployments work better because they use IP-based addressing instead of DNS.
Deployment Disadvantages
Requires Akka.Management: You can’t use static seed nodes because pod DNS names are dynamic. You must use Akka.Management with Akka.Discovery.Kubernetes.
Temporary Resource Increase: During deployment, you’ll temporarily have more pods running (e.g., 4 pods instead of 3). If your cluster is so resource-constrained that one extra pod breaks things, you have bigger problems than choosing between StatefulSets and Deployments.
Must Use IP Addressing: For Akka.Remote communication, you need to use pod IPs rather than DNS names. This isn’t really a disadvantage; K8s networking actually works better with IPs when using dynamic pod scheduling but it’s a difference worth noting.
Our Recommendation: Use Deployments
At Petabridge, we’ve moved from StatefulSets to Deployments for Sdkbin and generally recommend Deployments for new projects. The reduction in cluster churn and the automatic rollback capabilities more than make up for the requirement to use Akka.Management.
Here’s what the deployment strategy looks like in YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: drawtogether
namespace: drawtogether
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1 # Allow 1 extra pod during rollout
maxUnavailable: 0 # Keep all pods available during update
This configuration ensures you always have at least 3 pods running and temporarily allows a 4th pod to come online during updates.
Configuring Akka.NET for Kubernetes
Let’s look at the actual code you need to get Akka.NET working in Kubernetes. I’ll use DrawTogether.NET, our real-time collaborative drawing application, as the reference implementation.
Setting Up Akka.Management with Kubernetes Discovery
The core of cluster formation in Kubernetes relies on Akka.Management and Akka.Discovery.Kubernetes. Here’s the configuration from our AkkaConfiguration.cs:
public static AkkaConfigurationBuilder ConfigureNetwork(
this AkkaConfigurationBuilder builder,
IServiceProvider serviceProvider)
{
var settings = serviceProvider.GetRequiredService<AkkaSettings>();
builder.WithRemoting(settings.RemoteOptions);
if (settings.AkkaManagementOptions is { Enabled: true })
{
// Disable seed nodes so Akka.Management takes precedence
var clusterOptions = settings.ClusterOptions;
clusterOptions.SeedNodes = [];
builder
.WithClustering(clusterOptions)
.WithAkkaManagement(setup =>
{
// Leave hostname blank in Kubernetes - uses pod IP
setup.Http.HostName = settings.AkkaManagementOptions.Hostname?.ToLower();
setup.Http.Port = settings.AkkaManagementOptions.Port;
setup.Http.BindHostName = "0.0.0.0";
setup.Http.BindPort = settings.AkkaManagementOptions.Port;
})
.WithClusterBootstrap(options =>
{
options.ContactPointDiscovery.ServiceName =
settings.AkkaManagementOptions.ServiceName;
options.ContactPointDiscovery.PortName =
settings.AkkaManagementOptions.PortName;
options.ContactPointDiscovery.RequiredContactPointsNr =
settings.AkkaManagementOptions.RequiredContactPointsNr;
options.ContactPointDiscovery.ContactWithAllContactPoints = true;
options.ContactPointDiscovery.StableMargin = TimeSpan.FromSeconds(5);
}, autoStart: true);
// Configure Kubernetes discovery
switch (settings.AkkaManagementOptions.DiscoveryMethod)
{
case DiscoveryMethod.Kubernetes:
builder.WithKubernetesDiscovery();
break;
// Other discovery methods omitted for brevity
}
}
return builder;
}
Key Points:
-
Leave hostname blank: In Kubernetes, Akka.Management should use the pod’s IP address, not a DNS name. The discovery system works better this way. We ensure this by just supplying a null value for this entry in DrawTogether’s configuration.
-
Disable seed nodes: When Akka.Management is enabled, clear out any static seed node configuration. Akka.Management will handle cluster formation automatically.
-
Contact point discovery: The
ServiceNameandPortNamemust match your Kubernetes service configuration (we’ll see that in a moment).
How Pod Label Selection Works
Before we dive into the Kubernetes YAML, it’s important to understand how Akka.Discovery.Kubernetes actually finds which pods should join together to form a cluster.
When you call .WithKubernetesDiscovery() in your Akka.NET configuration, the discovery mechanism queries the Kubernetes API directly for pods, filtering by labels. Here’s the process:
- Queries the Kubernetes API for pods in the same namespace
- Filters pods by the label selector
app={ServiceName}whereServiceNamecomes fromContactPointDiscovery.ServiceName - Checks for the management port specified in
ContactPointDiscovery.PortName(default:management) - Returns the IP addresses and ports of matching pods to Akka.Management for cluster bootstrap
The key insight: Akka.Discovery.Kubernetes looks directly at pod labels, not Service selectors. By default, it searches for pods with the label app={ServiceName} where ServiceName is the value you configured in ContactPointDiscovery.ServiceName.
So if you configure ServiceName = "drawtogether", discovery will find all pods labeled with app: drawtogether in the namespace. Pods with different labels (like app: chat-service) will be ignored, even if they’re in the same namespace.
Default Label Selection Behavior
By default, Akka.Discovery.Kubernetes:
- Looks for pods in the same namespace as the pod running the discovery
- Filters pods using the label selector
app={0}where{0}is replaced byContactPointDiscovery.ServiceName - Looks for a port named
management(or whatever you specify inPortName) on those pods - Returns pod IPs (or DNS names for StatefulSets) that match these criteria
Customizing the Label Selector
If you need more control over which pods are discovered (for example, if you want to use different labels or add additional filtering criteria), you can customize the label selector using the KubernetesDiscoveryOptions:
builder.WithKubernetesDiscovery(options =>
{
options.PodLabelSelector = "app={0},environment=production";
});
The {0} placeholder gets replaced with your ContactPointDiscovery.ServiceName value. This example would only discover pods with both app: drawtogether AND environment: production labels. You can use any valid Kubernetes label selector syntax here.
Important: While your Kubernetes Service typically uses the same app: drawtogether selector to route traffic to the pods, the Service selector and the discovery label selector are technically independent. Discovery queries pods directly by labels—it doesn’t query the Service first. That said, keeping these selectors aligned is a best practice to avoid confusion.
This label-based selection is what prevents accidental cluster mixing. Multiple Akka.NET deployments in the same namespace will form separate clusters as long as they use different app labels.
Kubernetes YAML Configuration
Now let’s look at the Kubernetes side. First, the headless service that enables pod discovery:
apiVersion: v1
kind: Service
metadata:
name: drawtogether
namespace: drawtogether
spec:
publishNotReadyAddresses: true # Critical for cluster formation!
clusterIP: None # Makes this a headless service
ports:
- port: 8558
name: management # Matches PortName in Akka.Management
- port: 5055
name: akka-remote # For Akka.Remote mesh networking
- port: 8080
name: http # For external HTTP traffic
selector:
app: drawtogether
The publishNotReadyAddresses Setting is Critical
This is a pitfall you absolutely want to avoid1. By default, Kubernetes won’t publish DNS entries for pods until they pass their readiness checks. But if your readiness check includes an Akka.Cluster health check (which verifies the node has joined the cluster), you create a catch-22:
- Pod starts up
- Tries to discover other pods to form a cluster
- Can’t find other pods because their DNS entries aren’t published yet (they’re not ready either)
- Can’t join cluster because there are no other pods
- Fails readiness check because it hasn’t joined the cluster
- DNS entry never gets published
Deadlock.
Setting publishNotReadyAddresses: true breaks this cycle by publishing DNS entries immediately when pods start, before they’ve passed their readiness checks.
Deployment Configuration
For a Deployment-based setup (recommended), here’s the environment variable configuration:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: AkkaSettings__RemoteOptions__PublicHostname
value: "$(POD_IP)" # Use IP instead of DNS
- name: AkkaSettings__AkkaManagementOptions__Enabled
value: "true"
- name: AkkaSettings__AkkaManagementOptions__DiscoveryMethod
value: "Kubernetes"
For StatefulSets, you’d use DNS-based addressing instead:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: AkkaSettings__RemoteOptions__PublicHostname
value: "$(POD_NAME).drawtogether" # DNS-based addressing
RBAC: Giving Pods Permission to Discover Each Other
For Akka.Discovery.Kubernetes to work, your pods need permission to query the Kubernetes API and list other pods in the namespace. This is where Kubernetes RBAC (Role-Based Access Control) comes in.
You need three things:
- A ServiceAccount for your pods
- A Role that grants permission to list pods
- A RoleBinding that connects the ServiceAccount to the Role
Here’s the complete RBAC configuration from DrawTogether.NET:
apiVersion: v1
kind: ServiceAccount
metadata:
name: drawtogether
namespace: drawtogether
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: pod-reader
namespace: drawtogether
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-pods
namespace: drawtogether
subjects:
- kind: ServiceAccount
name: drawtogether
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
Then in your Deployment or StatefulSet spec:
spec:
template:
spec:
serviceAccountName: drawtogether # Use the ServiceAccount
With this RBAC configuration in place, when a pod starts up:
- It uses the
drawtogetherServiceAccount credentials - Calls the Kubernetes API to list pods in its namespace
- Filters the results by label selector
app: drawtogether - Checks each pod for the
managementport (port 8558) - Uses those pod IPs/DNS names as contact points for cluster formation
This is why the RBAC permissions specifically grant get, watch, and list verbs for pods—Akka.Discovery.Kubernetes needs to directly query and continuously monitor pods as the cluster scales up and down.
Health Checks: Liveness vs. Readiness
Kubernetes has two types of health checks, and understanding the difference is crucial:
Liveness Probes: Answer the question “Is this process alive?” If a liveness probe fails, Kubernetes will restart the pod. This should almost always return true unless something catastrophic has happened (like the actor system has shut down).
Readiness Probes: Answer the question “Is this process ready to accept traffic?” If a readiness probe fails, Kubernetes removes the pod from load balancers but doesn’t restart it. This should check whether the pod has access to all resources it needs to do its job.
Configuring Health Check Endpoints
We recently added comprehensive health check support to Akka.Hosting, including dedicated checks for Akka.Cluster and Akka.Persistence. Here’s how to configure them:
services.AddAkka("DrawTogether", (builder, provider) =>
{
builder
.WithAkkaClusterReadinessCheck() // Checks if node has joined cluster
.WithActorSystemLivenessCheck() // Checks if actor system is running
.WithSqlPersistence(
connectionString: connectionString,
// ... other persistence config ...
journalBuilder: j =>
{
j.WithHealthCheck(name: "Akka.Persistence.Sql.Journal[default]");
},
snapshotBuilder: s =>
{
s.WithHealthCheck(name: "Akka.Persistence.Sql.SnapshotStore[default]");
});
});
These integrate with ASP.NET Core’s Microsoft.Extensions.Diagnostics.HealthChecks system. Next, you need to expose them as HTTP endpoints for Kubernetes to call:
public static class HealthCheckEndpointsExtensions
{
public static IEndpointRouteBuilder MapHealthCheckEndpoints(
this IEndpointRouteBuilder endpoints)
{
// /healthz - all checks (diagnostic use)
endpoints.MapHealthChecks("/healthz", new HealthCheckOptions
{
Predicate = _ => true,
ResponseWriter = WriteHealthCheckResponse
});
// /healthz/live - liveness checks only
endpoints.MapHealthChecks("/healthz/live", new HealthCheckOptions
{
Predicate = check => check.Tags.Contains("liveness"),
ResponseWriter = WriteHealthCheckResponse
});
// /healthz/ready - readiness checks (persistence, cluster membership)
endpoints.MapHealthChecks("/healthz/ready", new HealthCheckOptions
{
Predicate = check => check.Name.Contains("ready"),
ResponseWriter = WriteHealthCheckResponse
});
return endpoints;
}
}
Then in Program.cs:
app.MapHealthCheckEndpoints();
Kubernetes Health Probe Configuration
In your Deployment/StatefulSet YAML:
livenessProbe:
httpGet:
path: /healthz/live
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /healthz/ready
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
The readiness probe runs more frequently (every 10 seconds) because it’s used to determine whether traffic should be routed to the pod. The liveness probe runs less often (every 20 seconds) and is more tolerant of failures.
Securing Akka.Remote with TLS Certificates
One thing we haven’t talked about much publicly before is how to secure Akka.Remote communication using TLS certificates stored in Kubernetes Secrets. In production environments, you don’t want your cluster nodes communicating over unencrypted channels, especially if they’re exchanging sensitive data.
Creating and Storing TLS Certificates
First, generate a self-signed certificate for local testing (in production, use certificates from your certificate authority):
# Generate a self-signed certificate
openssl req -x509 -newkey rsa:4096 -keyout akka-key.pem -out akka-cert.pem -days 365 -nodes
# Convert to PKCS12 format (.pfx)
openssl pkcs12 -export -out akka-node.pfx -inkey akka-key.pem -in akka-cert.pem -password pass:Test123!
# Create Kubernetes secret
kubectl create secret generic akka-tls-cert \
--from-file=akka-node.pfx=akka-node.pfx \
--namespace=drawtogether
Mounting the Certificate in Pods
In your Deployment/StatefulSet spec:
spec:
template:
spec:
containers:
- name: drawtogether-app
env:
- name: AkkaSettings__TlsSettings__Enabled
value: "true"
- name: AkkaSettings__TlsSettings__CertificatePath
value: "/certs/akka-node.pfx"
- name: AkkaSettings__TlsSettings__CertificatePassword
value: "Test123!" # This should really be fetched from a secret
- name: AkkaSettings__TlsSettings__ValidateCertificates
value: "false" # Set to true in production with real certs
volumeMounts:
- name: tls-cert
mountPath: /certs
readOnly: true
volumes:
- name: tls-cert
secret:
secretName: akka-tls-cert
C# Configuration for TLS
The configuration code automatically detects TLS settings and applies them to Akka.Remote:
private static void ConfigureRemoteOptionsWithTls(AkkaSettings settings)
{
var tlsSettings = settings.TlsSettings!;
var remoteOptions = settings.RemoteOptions;
// Load the certificate from the mounted path
var certificate = tlsSettings.LoadCertificate();
if (certificate is null)
throw new InvalidOperationException(
"TLS is enabled but no certificate could be loaded");
// Configure SSL through RemoteOptions
remoteOptions.EnableSsl = true;
remoteOptions.Ssl = new SslOptions
{
X509Certificate = certificate,
SuppressValidation = !tlsSettings.ValidateCertificates
};
// Update seed nodes to use akka.ssl.tcp:// protocol
if (settings.ClusterOptions.SeedNodes?.Length > 0)
{
settings.ClusterOptions.SeedNodes = settings.ClusterOptions.SeedNodes
.Select(node => node.Replace("akka.tcp://", "akka.ssl.tcp://"))
.ToArray();
}
}
With this configuration, all Akka.Remote communication between cluster nodes uses TLS encryption.
Using Petabridge.Cmd as a Sidecar Container
One of the most useful tools for managing and troubleshooting Akka.NET clusters in Kubernetes is Petabridge.Cmd, our free command-line tool for Akka.NET. We ship a pre-built Docker sidecar container that makes it trivially easy to include in your pods.
Enabling Petabridge.Cmd in Your Application
First, configure Petabridge.Cmd in your Akka.NET application:
builder.Services.ConfigureAkka(builder.Configuration,
(configurationBuilder, provider) =>
{
var options = provider.GetRequiredService<AkkaSettings>();
configurationBuilder.AddPetabridgeCmd(
options: options.PbmOptions,
hostConfiguration: cmd =>
{
cmd.RegisterCommandPalette(ClusterCommands.Instance);
cmd.RegisterCommandPalette(ClusterShardingCommands.Instance);
});
});
This binds Petabridge.Cmd to port 9110 (the default) inside your container.
Adding the Sidecar Container
In your Deployment/StatefulSet, add a second container alongside your application:
spec:
template:
spec:
containers:
- name: pbm-sidecar
image: petabridge/pbm:latest
- name: drawtogether-app
image: drawtogether
# ... rest of your application config
The sidecar container runs the Petabridge.Cmd client, which connects to localhost:9110 to communicate with your Akka.NET application.
Using Petabridge.Cmd
With the sidecar in place, you can exec into the pod and run Petabridge.Cmd commands:
# Exec into the pbm-sidecar container
kubectl exec -it drawtogether-0 -c pbm-sidecar -- /bin/sh
# Show cluster status
pbm cluster show
# View cluster sharding regions
pbm cluster sharding regions
# Get statistics for a specific shard region
pbm cluster sharding region-stats drawing-session
This is invaluable for troubleshooting and understanding what’s happening inside your cluster without needing to deploy custom monitoring tools.
Graceful Shutdowns and terminationGracePeriodSeconds
When Kubernetes needs to terminate a pod (during a deployment, scale-down, or node drain), you want your Akka.NET application to shut down gracefully. This means:
- Stop accepting new work
- Finish processing in-flight messages
- Hand off cluster sharding responsibility to other nodes
- Persist any final state to your database or event journal
- Shut down cleanly
Kubernetes provides the terminationGracePeriodSeconds setting to control how much time a pod has to shut down before it’s forcibly killed:
spec:
template:
spec:
terminationGracePeriodSeconds: 35
How This Works:
- Kubernetes sends a SIGTERM signal to your application
- Your application has
terminationGracePeriodSeconds(35 seconds in this example) to shut down - If it doesn’t shut down within that time, Kubernetes sends SIGKILL and forcibly terminates it
Akka.NET’s coordinated shutdown system automatically handles graceful termination when it receives SIGTERM. The sequence looks like this:
sequenceDiagram
participant K8s as Kubernetes
participant App as Akka.NET App
participant Cluster as Cluster Members
participant DB as Persistence Store
K8s->>App: Sends SIGTERM
App->>App: Fails readiness check
K8s->>K8s: Removes pod from load balancer
App->>Cluster: Initiates cluster leave
App->>DB: Persists final state
Cluster->>Cluster: Rebalances shards
App->>App: Shuts down actor system
App->>K8s: Process exits
Note over K8s: If > 35 seconds, SIGKILL
For Akka.NET applications with cluster sharding, 35 seconds is usually sufficient. If you have very large amounts of state to persist or complex shutdown logic, you might need to increase this value.
Pod Resource Limits and Horizontal Pod Autoscaling
One final consideration: setting appropriate resource requests and limits for your Akka.NET pods, and whether to use Horizontal Pod Autoscaling (HPA).
Resource Requests and Limits
resources:
requests:
memory: "512Mi"
cpu: "500m" # 0.5 CPU cores
limits:
memory: "4Gi"
# No CPU limit - Akka.NET can be very bursty during recovery
IMPORTANT: These are example values only.
Do NOT copy-paste these into production without profiling your actual workload.
Serious production Akka.NET applications, especially those using Akka.Persistence, Cluster.Sharding, or running A LOT of actors with in-memory state may require substantially more memory. An OOMKill during cluster rebalancing or persistence recovery can trigger cascading failures across your cluster.
Always monitor your actual memory usage in production and set limits with comfortable headroom.
Requests tell Kubernetes how much resources the pod needs to function normally. Kubernetes uses this for scheduling decisions.
Limits define the maximum resources the pod can consume. If a pod exceeds its memory limit, it gets OOMKilled. If it exceeds CPU limits, it gets throttled.
For Akka.NET applications, I generally recommend:
- Conservative memory requests: Start with what you know you need and monitor actual usage
- Generous memory limits: Akka.NET applications can temporarily spike memory usage during cluster rebalancing or message bursts
- Set CPU requests, but avoid CPU limits: Akka.NET can be extremely bursty, especially during pod initialization when actors are recovering state from Akka.Persistence. CPU throttling during these critical periods can cause recovery to take longer, leading to health check failures and potential failure cascades. Either set no CPU limit at all, or set it very high if your cluster policies require one
Horizontal Pod Autoscaling (HPA)
HPA can automatically scale your Akka.NET cluster based on metrics like CPU utilization or custom application metrics. However, be cautious with HPA for stateful Akka.NET applications:
Why HPA Can Be Problematic:
-
Cluster rebalancing overhead: Every time HPA scales up or down, Akka.Cluster.Sharding has to rebalance shards across the new pod count. Frequent scaling creates constant rebalancing.
-
Latency during rebalancing: While shards are moving, requests to those entities experience higher latency.
-
Persistence pressure: If your entities use Akka.Persistence, rebalancing means more entities rehydrating from storage.
When HPA Makes Sense:
- Your application has predictable traffic patterns (e.g., scale up during business hours, down at night)
- You use long cooldown periods (e.g., only scale every 10-15 minutes minimum)
- Your entities are relatively lightweight and cheap to move
Our Approach at Petabridge:
For Sdkbin, we don’t use HPA. We maintain a fixed cluster size that’s provisioned for peak load. We just don’t have high enough traffic to really merit investing in it.
If you do use HPA, configure it conservatively:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: drawtogether-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: drawtogether
minReplicas: 3
maxReplicas: 10
behavior:
scaleDown:
stabilizationWindowSeconds: 600 # Wait 10 minutes before scaling down
scaleUp:
stabilizationWindowSeconds: 300 # Wait 5 minutes before scaling up
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
Putting It All Together
Running Akka.NET in Kubernetes is absolutely viable and, in many ways, easier than alternative orchestration approaches. The key is understanding how Kubernetes features map to Akka.NET’s requirements:
- Use Deployments over StatefulSets for less cluster churn and easier rollbacks
- Configure Akka.Management + Akka.Discovery.Kubernetes for automatic cluster formation
- Set up proper RBAC so pods can discover each other
- Implement health checks that distinguish between liveness and readiness
- Use Kubernetes Secrets to secure Akka.Remote with TLS
- Add the Petabridge.Cmd sidecar for operational visibility
- Configure terminationGracePeriodSeconds to allow graceful shutdowns
- Set appropriate resource limits based on your actual workload
All of the code from this post is available in the DrawTogether.NET repository. Clone it, run it locally with Docker Desktop’s Kubernetes support, and experiment with different configurations.
If you’re building production Akka.NET applications in Kubernetes and need help, reach out to Petabridge. We’ve been doing this for years and can help you avoid the mistakes we made along the way.
Further Resources:
- Akka.Management Documentation
- Akka.Hosting Health Checks Video
- DrawTogether.NET Repository
- Petabridge.Cmd Documentation
-
Unless you’re using IP-based networking in K8s, in which case
publishNotReadyAddressesdoesn’t affect anything. ↩
- Read more about:
- Akka.NET
- Case Studies
- Videos
Observe and Monitor Your Akka.NET Applications with Phobos
Did you know that Phobos can automatically instrument your Akka.NET applications with OpenTelemetry?
Click here to learn more.