Self-Healing Akka.NET Clusters
How Split Brain Resolvers ensure consistency even during network turbulence.
13 minutes to readWe just recently wrote about using Akka.Management to help automate Akka.Cluster formation in most runtime environments - this post deals with a similar theme: how Akka.Cluster’s built-in infrastructure deals with network failures that will inevitably occur inside any distributed application over a sufficiently long period of time.
Split Brains and Akka.Cluster
Specifically, we’re going to address how Akka.Cluster deals with split brains - a type of network failure that breaks a once-functioning cluster apart into smaller, isolated islands that can no longer communicate with each other.
Let’s dive in.
Network Partitions and Splits
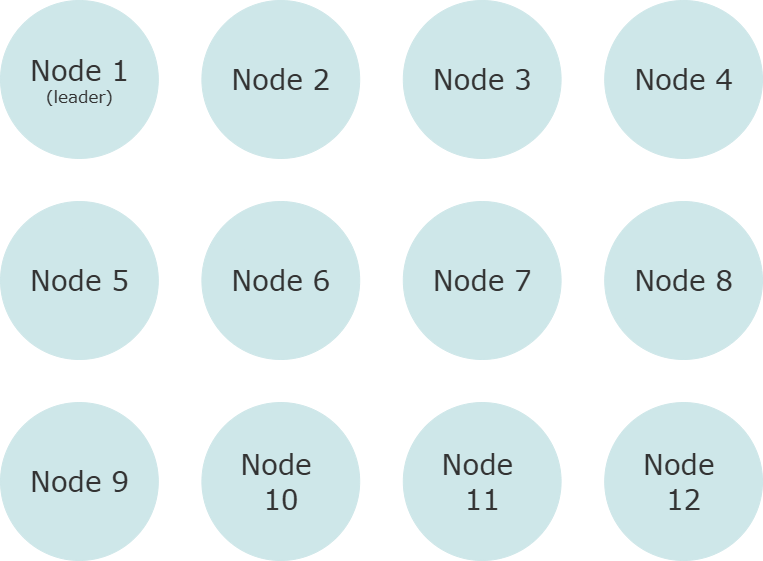
Suppose you have the following 12 node cluster initially.
A “partition” happens when some of the nodes in this network lose their ability to communicate with some of the others:
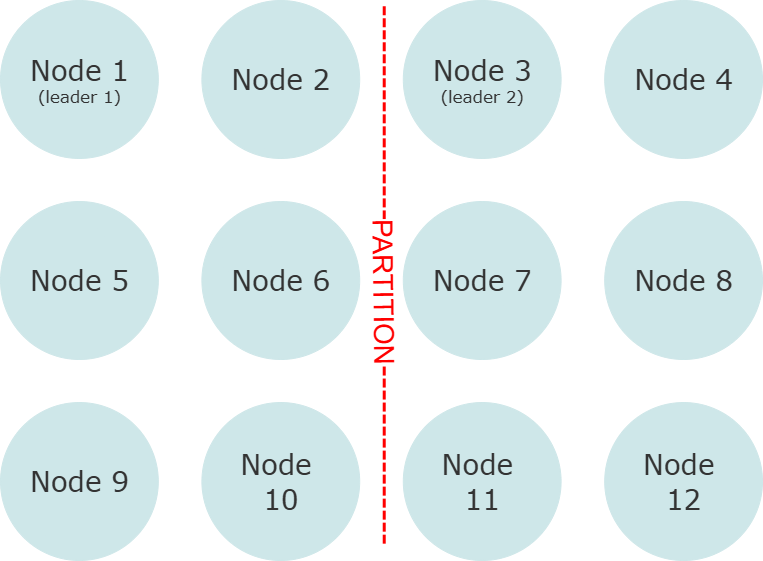
We have an even split: two groups of 6 nodes that can talk among themselves, but not to each other. This is a classic “split brain” scenario - most application telemetry would make it look like the application is still functioning normally at this point, but it’s not: it’s actually two separate instances of the application, each marching to the beat of their own drum.
What could cause a network split to form like this? In most cases, you don’t get a 50/50 split inside an application - only a failure in the hardware or software networking stack could cause that (i.e. the connection between two different racks in a data center being disrupted.)
In Akka.Cluster terminology, a network split happens when one or more nodes become “UNREACHABLE” - and you will see a bunch of angry-looking log messages to that effect in the Akka.Cluster system logs.
Typically, you’ll see much smaller, more isolated, and more random islands of connectivity form as a result of resources such as CPU or network bandwidth becoming constrained. Any of the fallacies of distributed systems can cause a split - and it’s a matter of when they will happen to you, not if.
Harm Caused by Split Brains
In some of our previous posts, such as “The Worst .NET Bug I’ve Ever Fixed,” we go into excruciating detail on how destructive these split brain scenarios can be for distributed applications: data loss, data corruption, and total loss of consistency within the application itself.
In Akka.Cluster, what this looks like:
- Multiple leaders forming in the cluster;
- Duplicate cluster singletons;
- Duplicate shards and persistent entities; and
- Data corruption and inconsistency throughout most persistent actors.
Therefore, it is crucial that we:
- Try to prevent split brains from forming (this is what tools like Akka.Management seek to do) and
- Resolve them if they occur as a result of runtime network failures.
Enter the “Split Brain Resolver” - Akka.NET’s distributed algorithms used for repairing these network splits even when nodes are unable to communicate directly with each other.
Split Brain Resolvers
Akka.Cluster enables the “keep majority” split brain resolver by default. Here’s how it works:
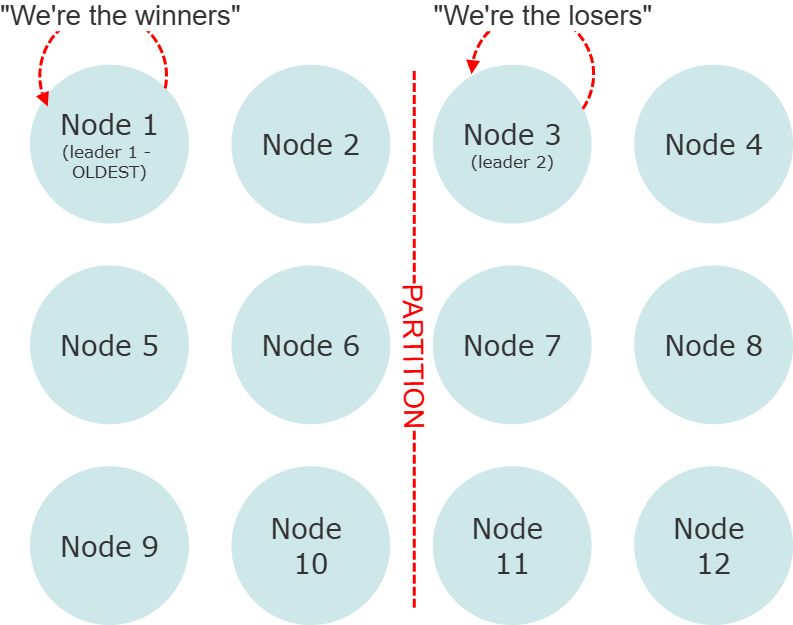
When the cluster splits, the goal of the “keep majority” strategy is to try to preserve the partition in the cluster that includes over 50% of the original nodes.
If there is no partition that matches this size, then all nodes will be DOWNed by the Akka.Cluster “leader” node in each partition, resulting in a full restart of the entire cluster.
In the event that there are two perfectly even-sized partitions, the partition that has the oldest surviving node will be declared the winner and will survive.
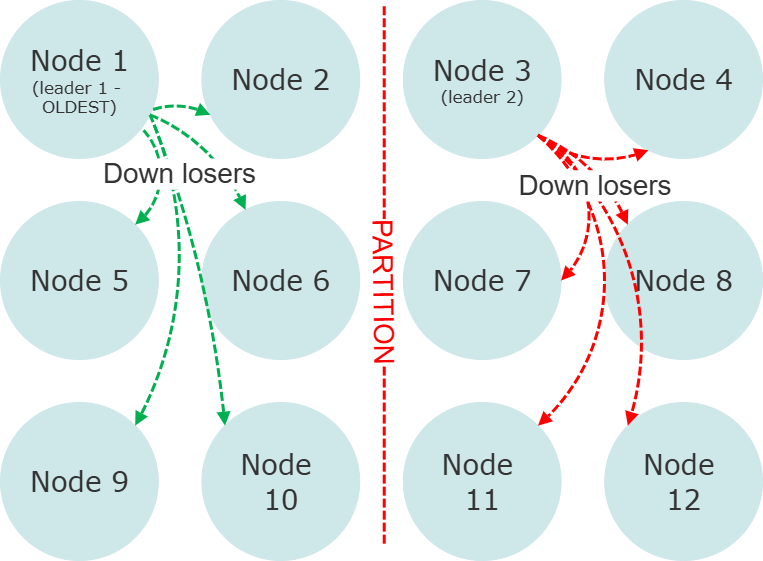
The key to making the SBR work effectively is that it runs, simultaneously, in all partitions that have alive nodes - and all SBR algorithm implementations use heuristics that are fairly reliable at determining winners and losers without any sort of direct communication1.
Each time a node is sent a DOWN command by the leader of their respective partition, that node will self-terminate and its process will exit2. The final state of the cluster once the SBR is done executing will look like this:
Default Split Brain Resolver Configuration
It’s trivial to configure the SBR via Akka.Hosting or via HOCON:
builder.Services.AddAkka("MyActorSystem", configurationBuilder =>
{
configurationBuilder
.WithRemoting("localhost", 8110)
.WithClustering(new ClusterOptions {
Roles = new[] { "myRole" },
SeedNodes = new[] { Address.Parse("akka.tcp://MyActorSystem@localhost:8110")},
SplitBrainResolver = SplitBrainResolverOption.Default // redundant, but uses the SBR.
});
});
Alternatively, you could install Akka.Coordination.Azure and use the LeaseMajority strategy instead of the default KeepMajority strategy:
builder.Services.AddAkka("MyActorSystem", configurationBuilder =>
{
var leaseOptions = new AzureLeaseOption {
ConnectionString = "<Your-Azure-Blob-storage-connection-string>",
ContainerName = "<Your-Azure-Blob-storage-container-name>";
};
configurationBuilder
.WithClustering(new ClusterOptions {
SplitBrainResolver = new LeaseMajorityOption{
LeaseImplementation = leaseOptions,
},
})
.WithAzureLease(leaseOptions);
});
The difference in this case being that the SBR will try to acquire a “lease,” a type of distributed lock, and whoever grabs that lock gets to determine the winner. This is a strategy that works really well for larger Akka.NET clusters in particular.
Akka.Cluster and Partition Tolerance
Partition tolerance is an essential pillar of the CAP theorem, thus it’s absolutely necessary that Akka.Cluster maintain some degree of partition tolerance in order to remain consistent and available.
Therefore, we use the following math to determine how long we can tolerate 1 or more nodes going UNREACHABLE before the Split Brain Resolver kicks in and starts killing them:
akka.cluster.failure-detector.heartbeat-interval = 1s- this is the failure detector interval the Akka.Cluster’s heartbeat system uses to test responsiveness from nodes inside the cluster. If a node doesn’t respond to heartbeats for 3-5s, that node will be marked asUNREACHABLEby the node who sent the original heartbeat. If the node starts responding to heartbeats again, it will be viewed asREACHABLEonce more - this means that the partition healed on its own (which is often the case.)akka.cluster.split-brain-resolver.stable-after = 20s- once at least 1 node gets marked asUNREACHABLE, a 20 second (configurable) countdown begins. If other nodes get marked asUNREACHABLEor maybe some of those nodes becomeREACHABLEagain, the timer will reset. But once we get to 0 without any additional changes in topology - the configured strategy will run and we’ll beginDOWNing nodes according to it.
In total it takes roughly 25 seconds for Akka.Cluster to begin making DOWNing decisions to resolve a network partition.
All of these values are configurable and adjustable via HOCON or Akka.Hosting.
down-all-when-unstable
An important setting that is enabled by default in Akka.Cluster:
akka.cluster.split-brain-resolver {
# Select one of the available strategies (see descriptions below):
# static-quorum, keep-majority, keep-oldest, down-all, lease-majority, (keep-referee)
# keep-referee - supported only with the old split brain resolver
active-strategy = keep-majority
# Decision is taken by the strategy when there has been no membership or
# reachability changes for this duration, i.e. the cluster state is stable.
stable-after = 20s
# When reachability observations by the failure detector are changed the SBR decisions
# are deferred until there are no changes within the 'stable-after' duration.
# If this continues for too long it might be an indication of an unstable system/network
# and it could result in delayed or conflicting decisions on separate sides of a network
# partition.
# As a precaution for that scenario all nodes are downed if no decision is made within
# `stable-after + down-all-when-unstable` from the first unreachability event.
# The measurement is reset if all unreachable have been healed, downed or removed, or
# if there are no changes within `stable-after * 2`.
# The value can be on, off, or a duration.
# By default it is 'on' and then it is derived to be 3/4 of stable-after, but not less than
# 4 seconds.
# supported only with the new split brain resolver
down-all-when-unstable = on
}
When down-all-when-unstable = on - we will keep track of how often the stable-after value is reset as a result of fluctuations in the network environment. If the cumulative duration of that stable-after value across all of its resets reaches 175% of its value (35 seconds,) then the leaders of each partition will issue a DOWN command to all nodes in the cluster: a full restart of everything.
This function is meant to act as a failsafe for severe problems that can happen in the runtime environment, such as hypervisor failures. When the network is fluctuating rapidly, then there’s no clear winners and losers. The SBRs are mostly interested in preserving consistency inside the cluster, not availability, therefore they’re going to err on the side of caution and DOWN everyone.
You can set down-all-when-unstable to a longer timespan value or you can disable it completely, but it is enabled by default.
What About the DOWNed Nodes?
So what happens to the DOWNed nodes in this scenario? Don’t we still need them? Well, yes, of course we do!
Akka.NET, just like any other production application, should be run beneath a process supervisor such as Windows Services, Kubernetes, Docker Compose, etc - and when that supervisor notices a process exit unexpectedly it will attempt to restart it.
And if we’re using tools like Akka.Management to guide cluster formation (a best practice) - the nodes being rebooted shouldn’t be able to join the existing cluster and serve traffic until their partition has been healed.
Other Split Brain Resolver Algorithms
Akka.Cluster ships with several SBR strategies that are readily available for use:
keep-majority- by default, keep whichever portion of the cluster has greater than 50% of the original nodes. Can also be configured to use a specific role (i.e. whichever partition has 50% > of allwebroles gets to live.)lease-majority- uses an Akka.CoordinationLeaseto determine who gets to pick winners and losers. Typically the largest partition gets to acquire theLeasefirst, but if that fails or there isn’t one - which surviving partition acquires theLeasegets to survive.static-quorum- keep any partitions that have at leastnnodes of a given role type alive.keep-oldest- whichever partition contains the oldest node gets to live. Works great with static seed nodes.down-all- whenever any node getsDOWNed, everyone getsDOWNed.
-
Because the very network partition we’re trying to resolve renders direct communication impossible. ↩
-
It’s possible to change this default behavior in Akka.NET, but the
CoordinatedShutdownmechanism will ensure that once a node leaves the cluster it terminates itsActorSystem, and once itsActorSystemis terminated then the process will exit. ↩
- Read more about:
- Akka.NET
- Case Studies
- Videos
Observe and Monitor Your Akka.NET Applications with Phobos
Did you know that Phobos can automatically instrument your Akka.NET applications with OpenTelemetry?
Click here to learn more.