Form Akka.NET Clusters Dynamically with Akka.Management and Akka.Discovery
A safer, superior choice to using seed nodes with Akka.Cluster
15 minutes to readAkka.Cluster is a very powerful piece of software aimed at helping .NET developers build highly available, low-latency, distributed software. At its core, Akka.Cluster is about building peer-to-peer networks—that’s what a “cluster” actually is: a peer-to-peer network that runs in a server-side environment controlled by a single operator.
What Clusters Need
This is a subject for another blog post, but what makes peer-to-peer networks a superior choice over client-server networks for high availability are the following:
- Horizontally scalable, because the “source of truth” is decentralized and distributed to the endpoints of the network (these are your actors running in each process) rather than centralized in a single location;
- Fault tolerant and resilient - having the source of truth decentralized and distributed also means that no single node in the network is so crucial that its disappearance is going to render the system unavailable; and
- Still supports inter-dependent services - you can still have multiple services with completely different purposes and code cooperating together inside a peer-to-peer network. This is what Akka.Cluster roles are for.
In order to build a peer-to-peer network, you need two primary ingredients:
- Topology-awareness - database-driven CRUD applications never need to do this. The load-balancer is aware of where the web servers are and the web servers are aware of where the database is, but that’s pretty much it. In a real peer-to-peer network, all applications need to know about each other and need to communicate with each other directly. These are what Akka.Remote (communication) and Akka.Cluster (topology) provide.
- Initial formation - there must be a strategy for processes to form a new peer-to-peer network or to join an existing one.
In this blog post, we’ll be discussing item number 2—how to make the formation and joining of Akka.Cluster networks more reliable, dynamic, and automated through the use of Akka.Management and Akka.Discovery.
Also, be sure to catch our companion video on today’s subject “Form Akka.NET Clusters Dynamically with Akka.Management and Akka.Discovery” (0:24:45)
The Problem with Seed Nodes
The default strategy for forming new Akka.NET clusters is using “seed nodes”—that is, a set of statically addressed nodes that everyone contacts when they first start up. This is usually baked into your Akka.NET configuration, such as in the following example:1:
public class AkkaSettings
{
public string ActorSystemName { get; set; } = "DrawTogether";
public bool LogConfigOnStart { get; set; } = false;
public RemoteOptions RemoteOptions { get; set; } = new()
{
// can be overridden via config, but is dynamic by default
PublicHostName = Dns.GetHostName(),
Port = 8081
};
public ClusterOptions ClusterOptions { get; set; } = new ClusterOptions()
{
// use our dynamic local host name by default
SeedNodes = [$"akka.tcp://DrawTogether@{Dns.GetHostName()}:8081"],
Roles = [ClusterConstants.DrawStateRoleName]
};
public ShardOptions ShardOptions { get; set; } = new ShardOptions();
public AkkaManagementOptions? AkkaManagementOptions { get; set; }
}
Typically, you want to run at least 3 seed nodes in order to protect your cluster against having single points of failure / split brains et al. In this simple example, we’re only running a single one.
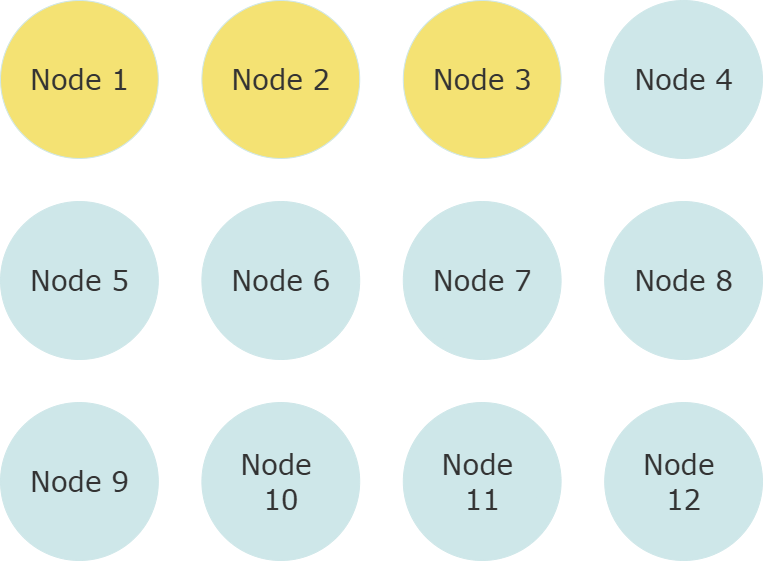
In this 12 node cluster, let’s suppose the first 3 nodes—our “minimum viable cluster”—are our seed nodes. Every node in the cluster should be running with identical seed node configuration values, including the seed nodes themselves—this is key to making them work reliably.
Under this configuration:
- When the cluster starts for the first time, everyone tries to join nodes 1-3;
- If a cluster does not exist, node 1—the first seed node on the list—must be available or a cluster will not form. This is a requirement imposed to ensure you can’t accidentally form more than one cluster at startup (creating a split brain) when you’re running with seed nodes.
- Node 1 will mark itself as the leader and then mark all of the other nodes as “Up” once it knows that they’ve all been able to successfully communicate with each other.
- Any additional nodes that attempt to join the cluster in the future only need to successfully reach one of the three seed nodes and they’ll be able to join.
This approach is both simple and largely automatic. However, it has a major weakness: it is static, and thus relies on these three nodes always being part of the current cluster to be effective.
What Happens When the Network Splits?
As I was getting ready to prepare our YouTube video for this post, one of our customers experienced a large disruption to their Akka.NET application as a result of two different Azure availability zones in the same region losing contact with each other. This resulted in 50% of their nodes each losing contact with each other.
In Akka.Cluster, a split brain resolver will take care of this situation typically—but there’s a problem: the seed nodes aren’t necessarily the oldest nodes in the cluster (due to previous rolling deployments), so they can get killed off by the SBR. And when they rebooted… Well, they formed a second cluster.
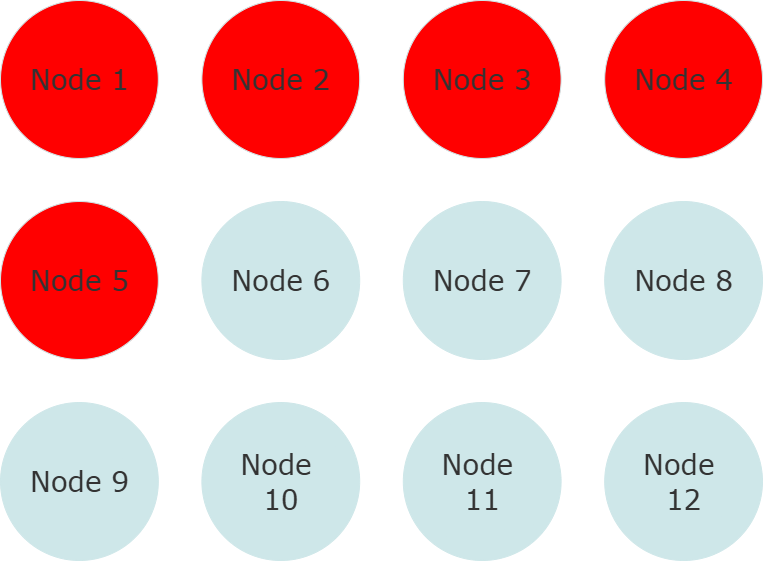
This is an extremely nasty problem. Your options for solving it are:
- Have your seed nodes be equally split between each rack—”let’s do static addressing even harder this time” or
- Use a service discovery system to dynamically resolve cluster members based upon who is actually available in the live environment.
Akka.Management and Akka.Discovery are option number 2.
What If Your Environment Doesn’t Support Static Addresses?
So, this is an important detail I missed entirely when filming “Form Akka.NET Clusters Dynamically with Akka.Management and Akka.Discovery“—what happens if your environment doesn’t support static addresses and you want to run Akka.Cluster?
This is a common use case with lightweight Platform-as-a-Service environments like Azure App Services—they don’t allow static addresses since all of the infrastructure is managed directly by the cloud provider.
Running Akka.NET clusters without static nodes was mostly infeasible prior to Akka.NET v1.5—when we shipped Akka.Management. This is because Akka.Management’s model for forming clusters is totally dynamic; it doesn’t care how IP addresses and host names are allocated.
How Akka.Management and Akka.Discovery Works
So, when we mention “Akka.Management,” we’re really talking about three components:
- The Akka.Management HTTP API - this is used to expose various private HTTP endpoints to callers;
- Akka.Discovery - a pluggable service discovery engine that is able to query the live environment and return a set of available members;
- The Cluster Bootstrapper - this is part of Akka.Management and is the only active user of the HTTP API system currently; it leverages the HTTP APIs and Akka.Discovery to determine who can form a cluster / who is in a cluster we can join right now, and then dynamically populates the set of seed nodes that Akka.Cluster can use to join.
All three of these components work together to dynamically discover seed nodes, safely determine if a new cluster should be formed or if there’s an existing one to join, and communicate this information to new members who attempt to join the cluster in the future.
Akka.Discovery
The Akka.Management repository and the core Akka.NET repository all contain several mature service discovery implementations:
Akka.Discovery.AwsApi- Akka.Cluster bootstrapping discovery service using EC2, ECS, and the AWS API.Akka.Discovery.KubernetesApi- Akka.Cluster bootstrapping discovery service using Kubernetes API.Akka.Discovery.Azure- Akka.Cluster bootstrapping discovery service using Azure Table Storage.Akka.Discovery.Configuration- built into the core Akka.NET library and we need to do a better job documenting it.
You can also choose to run multiple Akka.Discovery implementations in parallel if you wish.
Let’s use Akka.Discovery.Azure as an example.
Here’s what our sample configuration might look like, using some real Akka.Hosting code we use in production on DrawTogether.NET2:
public static AkkaConfigurationBuilder ConfigureNetwork(this AkkaConfigurationBuilder builder,
IServiceProvider serviceProvider)
{
var settings = serviceProvider.GetRequiredService<AkkaSettings>();
builder
.WithRemoting(settings.RemoteOptions);
if (settings.AkkaManagementOptions is { Enabled: true })
{
// need to delete seed-nodes so Akka.Management will take precedence
var clusterOptions = settings.ClusterOptions;
clusterOptions.SeedNodes = [];
builder
.WithClustering(clusterOptions)
.WithAkkaManagement(port: settings.AkkaManagementOptions.Port)
.WithClusterBootstrap(serviceName: settings.AkkaManagementOptions.ServiceName,
portName: settings.AkkaManagementOptions.PortName,
requiredContactPoints: settings.AkkaManagementOptions.RequiredContactPointsNr);
switch (settings.AkkaManagementOptions.DiscoveryMethod)
{
case DiscoveryMethod.Kubernetes:
builder.WithKubernetesDiscovery();
break;
case DiscoveryMethod.AwsEcsTagBased:
break;
case DiscoveryMethod.AwsEc2TagBased:
break;
case DiscoveryMethod.AzureTableStorage:
{
var connectionString = configuration.GetConnectionString("AkkaManagementAzure");
if (connectionString is null)
throw new Exception("AkkaManagement table storage connection string [AkkaManagementAzure] is missing");
builder.WithAzureDiscovery(options =>
{
options.ServiceName = settings.AkkaManagementOptions.ServiceName;
options.ConnectionString = connectionString;
});
break;
}
case DiscoveryMethod.Config:
{
builder
.WithConfigDiscovery(options =>
{
options.Services.Add(new Service
{
Name = settings.AkkaManagementOptions.ServiceName,
Endpoints = new[]
{
$"{settings.AkkaManagementOptions.Hostname}:{settings.AkkaManagementOptions.Port}",
}
});
});
break;
}
default:
throw new ArgumentOutOfRangeException();
}
}
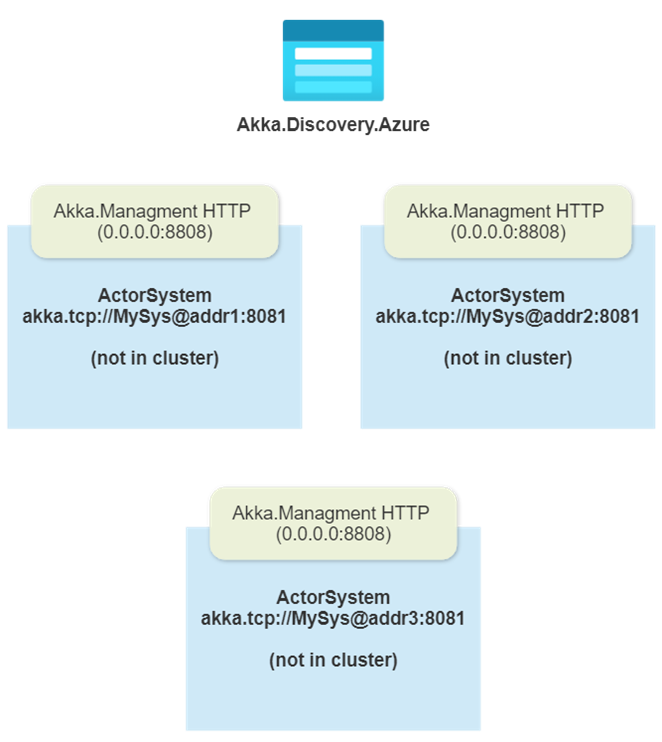
An important detail: you have to zero out the
SeedNodessetting before you launch Akka.Cluster if you want Akka.Management to work. Otherwise, Akka.Cluster will do its usual thing and try to use the seed nodes.
So all of our nodes launch without any seed nodes to join—Akka.Management and Cluster.Bootstrap are enabled though, so that’s going to cause us to begin querying the Akka.Discovery.Azure plugin for entries.
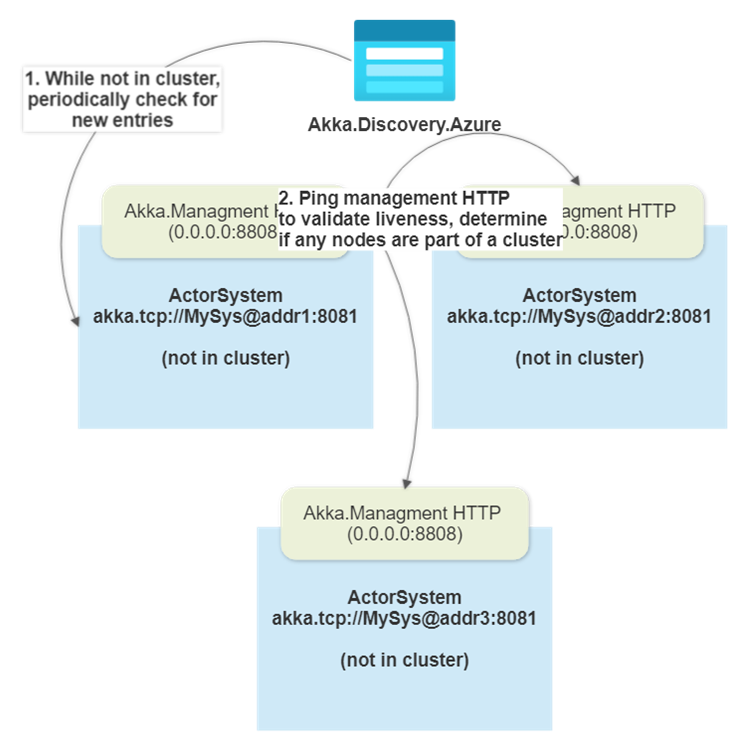
In addition to trying to read entries from Azure Table Storage, Akka.Discovery.Azure will also populate its own entry for the current node into the table. As we detect values from Akka.Discovery.Azure, the Cluster.Bootstrap machinery will ping the HTTP endpoints of those nodes to determine:
- If those nodes actually exist and
- Whether they are already part of a cluster OR are looking to form one.
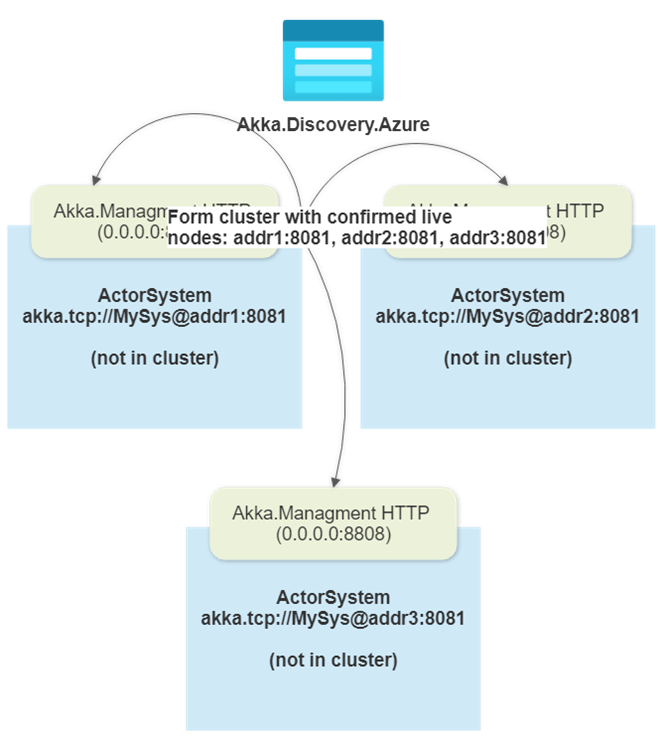
Once we satisfy the int requiredContactPoints value for Cluster.Bootstrap, a new cluster can form.
If there’s already an existing cluster present, then this setting doesn’t get used—we’ll just join that cluster straight away.
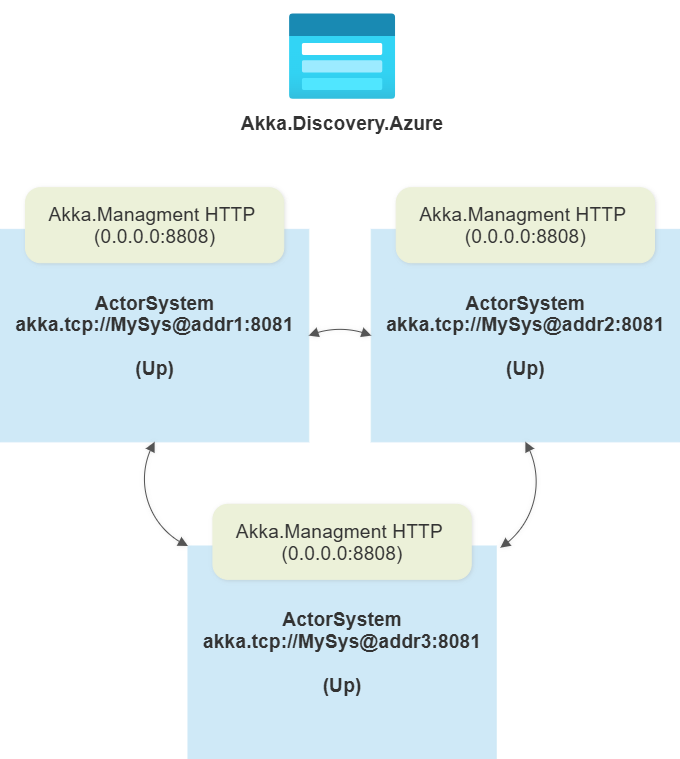
And now, we have a fully formed cluster!
Caveats with Akka.Management
Important details that we cover in the video:
- If you have fewer than
int requiredContactPointsdiscoverable via Akka.Discovery.Azure, a new cluster absolutely will not form—it will wait indefinitely until that number is reached. - If you set
requiredContactPointsto1—you are going to have a bad time. This 100% will result in split brains and other problems. Never do this. - An additional setting not shown in this code sample is
bool contactWithAllContactPoints—watch the video. This setting dials up the consistency requirements for forming a new cluster even higher. It stipulates that “if we discovered a contact point, its Akka.Management endpoint must have been successfully pinged or we can’t form a cluster.” If there are unreachable entries (i.e. node left and its entry is still visible inside Azure Table Storage for ~30s or so) we’re going to wait for them to get removed before we try to form a cluster.
Generally speaking, new clusters don’t get created during normal cluster deployments and operations. That only happens the first time a cluster is launched or after the entire cluster is shut down and brought back online. But, since we’re discussing disaster recovery scenarios here, making sure we only end up with a single cluster under all conditions is the goal. Akka.Management and Akka.Discovery will help you do that!
-
this configuration gets parsed by Microsoft.Extensions.Configuration, using values that are populated either in environment variables or
appSettings.json. You can see the project this is from here:DrawTogether/Config/AkkaSettings.cs↩ -
At the time of writing this post, this code is actually staged in an un-merged pull request: #206 - use Aspire + blob storage to run multiple local replicas - not working yet due to Aspire configuration issues. ↩
- Read more about:
- Akka.NET
- Case Studies
- Videos
Observe and Monitor Your Akka.NET Applications with Phobos
Did you know that Phobos can automatically instrument your Akka.NET applications with OpenTelemetry?
Click here to learn more.