
How do you keep your actor system from falling apart when things go wrong?
The short answer is Supervision.
What Is Supervision, and Why Should You Care?
What Is Supervision?
“Look at this mess you made. Now clean it up and start over!”
Just kidding. You’re doing great. Relax.
But I bet you’ve heard (and probably said) something similar before. That’s similar to supervision in the actor model: a parent monitors its children for errors, and decides how to clean up messes when they happen.

Why Should You Care?
Supervision is the basic concept that allows your actor system to quickly isolate and recover from failures.
Supervision from the top to the bottom of the actor hierarchy ensures that when part of your application encounters an unexpected failure (unhandled exception, network timeout, etc.) those failures will be contained to only the affected part of your actor hierarchy. All other actors will keep on working as though nothing happened. We call this “failure isolation.”
How is this accomplished? Let’s find out…
The Actor Hierarchy
First off, a bit of review from our actor basics overview: Every actor has a parent, and some actors have children.
Since parents supervise their children, this means that every actor has a supervisor, and every actor can also BE a supervisor.
Within your actor system, actors are arranged into a hierarchy. The overall hierarchy looks like this (we’ll go through piece by piece in a moment):
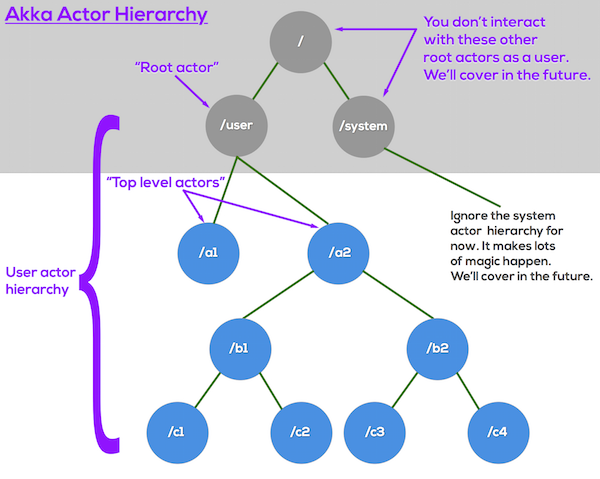
(Note: although this primarily uses examples from Akka.NET, it applies equally to JVM Akka.)
There’s a lot to digest here. Let’s break it down.
The Base of It All (the “Guardians”)
The “guardians” are the root actors of the entire system.
I’m referring to these three actors at the very top of the hierarchy:
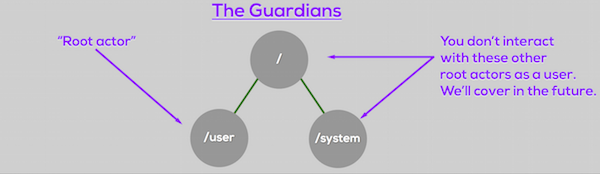
The / Actor
The / actor is the base actor of the entire actor system, and may also be referred to as “The Root Guardian.” This actor supervises the /system and /user actors (the other “Guardians”).
All actors require another actor as their parent, except this one. This actor is also sometimes called the “bubble-walker” since it is “out of the bubble” of the normal actor system. For now, don’t worry about this actor.
The /system Actor
The /system actor may also be referred to as “The System Guardian”. The main job of this actor is to ensure that the system shuts down in an orderly manner, and to maintain/supervise other system actors which implement framework level features and utilities (logging, etc). We’ll discuss the system guardian and the system actor hierarchy in a future post.
The /user Actor
This is where the party starts! And this is where you’ll be spending all your time as a developer.
The /user actor may also be referred to as “The Guardian Actor”. But from a user perspective, /user is the root of your actor system and is usually just called the “root actor.”
Generally, “root actor” refers to the
/useractor.
As a user, you don’t really need to worry too much about the Guardians. We just have to make sure that we use supervision properly under /user so that no exception can bubble up to the Guardians and crash the whole system.
The User Actor Hierarchy
This is the meat and potatoes of the actor hierarchy: all of the actors you define in your applications.
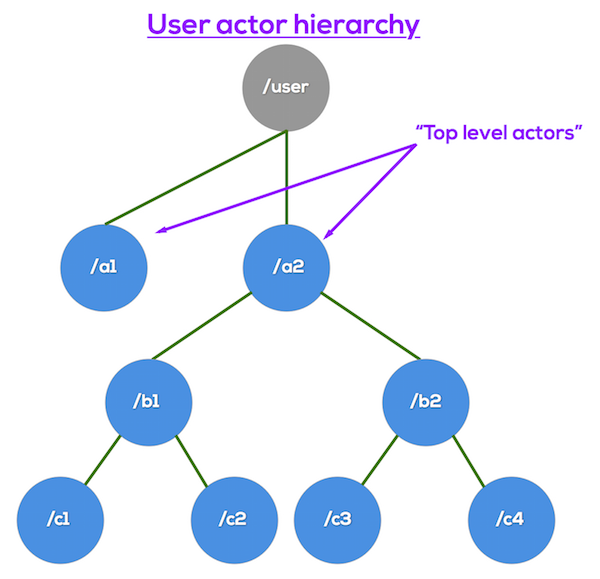
The direct children of the
/useractor are called “top level actors.”
Actors are always created as a child of some other actor.
Whenever you make an actor directly from the context of the actor system itself, that new actor is a top level actor, like so:
// create the top level actors from above diagram
ActorRef a1 = MyActorSystem.ActorOf(Props.Create<BasicActor>(), "a1");
ActorRef a2 = MyActorSystem.ActorOf(Props.Create<BasicActor>(), "a2");
Now, let’s make child actors for a2 by creating them inside the context of a2, our parent-to-be:
// create the children of actor a2 -- NOTE: this is inside actor a2!
ActorRef b1 = Context.ActorOf(Props.Create<BasicActor>(), "b1");
ActorRef b2 = Context.ActorOf(Props.Create<BasicActor>(), "b2");
Actor Path == Actor Position in Hierarchy
Every actor has an address. To send a message from one actor to another, you just have to know it’s address (AKA its “ActorPath”). To refresh your memory, this is what a full actor address looks like:

The “Path” portion of an actor address is just a description of where that actor is in your actor hierarchy. Each level of the hierarchy is separated by a single slash (‘/’).
For example, if we were running on localhost, the full address of actor b2 would be akka.tcp://MyActorSystem@localhost:9001/user/a1/b2.
One question that comes up a lot is, “Do my actor classes have to live at a certain point in the hierarchy?” For example, if I have an actor class, FooActor—can I only deploy that actor as a child of BarActor on the hierarchy? Or can I deploy it anywhere?
The answer is any actor may be placed anywhere in your actor hierarchy.
Any actor may be placed anywhere in your actor hierarchy.
Okay, now that we’ve got this hierarchy business down, let’s do something interesting with it. Like supervising!
How Supervision Works in the Actor Hierarchy
Now that you know how actors are organized, know this: actors supervise their children. But, they only supervise the level that is immediately below them in the hierarchy (actors do not supervise their grandchildren, great-grandchildren, etc).
Actors only supervise their children, the level immediately below them in the hierarchy.
When Does Supervision Come Into Play? Errors!
When things go wrong, that’s when! Whenever a child actor has an unhandled exception and is crashing, it reaches out to its parent for help and to tell it what to do.
Specifically, the child will send its parent a message that is of the Failure class. Then it’s up to the parent to decide what to do.
How Can the Parent Resolve the Error?
There are two factors that determine how a failure is resolved:
- How the child failed (what type of
Exceptiondid the child include in itsFailuremessage to its parent.) - What Directive the parent actor executes in response to a child
Failure. This is determined by the parent’sSupervisionStrategy.
Here’s the Sequence of Events When an Error Occurs:
- Unhandled exception occurs in child actor (
c1), which is supervised by its parent (p1). c1suspends operations.- The system sends a
Failuremessage fromc1top1, with theExceptionthat was raised. p1issues a directive toc1telling it what to do.- Life goes on, and the affected part of the system heals itself without burning down the whole house. Kittens and unicorns, handing out free ice cream and coffee to be enjoyed while relaxing on a pillowy rainbow. Yay!
Supervision Directives
When it receives an error from its child, a parent can take one of the following actions (“directives”). The supervision strategy maps different exception types to these directives, allowing you to handle different types of errors as appropriate.
Types of supervision directives (i.e. what decisions a supervisor can make):
- Restart the child (default): this is the common case, and the default.
- Stop the child: this permanently terminates the child actor.
- Escalate the error (and stop itself): this is the parent saying “I don’t know what to do! I’m gonna stop everything and ask MY parent!”
- Resume processing (ignores the error): you generally won’t use this. Ignore it for now.
The critical thing to know here is that whatever action is taken on a parent propagates to its children. If a parent is halted, all its children halt. If it is restarted, all its children restart.
Supervision Strategies
There are two built-in supervision strategies:
- One-For-One Strategy (default)
- All-For-One Strategy
The basic difference between these is how widespread the effects of the error-resolution directive will be.
One-For-One says that that the directive issued by the parent only applies to the failing child actor. It has no effect on the siblings of the failing child. This is the default strategy if you don’t specify one. (You can also define your own custom supervision strategy.)
All-For-One says that that the directive issued by the parent applies to the failing child actor AND all of its siblings.
The other important choice you make in a supervision strategy is how many times a child can fail within a given period of time before it is shut down (e.g. “no more than 10 errors within 60 seconds, or you’re shut down”).
Here’s an example supervision strategy:
public class MyActor : UntypedActor
{
// if any child of MyActor throws an exception, apply the rules below
// e.g. Restart the child, if 10 exceptions occur in 30 seconds or
// less, then stop the actor
protected override SupervisorStrategy SupervisorStrategy()
{
return new OneForOneStrategy(// or AllForOneStrategy
maxNumberOfRetries: 10,
duration: TimeSpan.FromSeconds(30),
decider: x =>
{
// Maybe ArithmeticException is not application critical
// so we just ignore the error and keep going.
if (x is ArithmeticException) return Directive.Resume;
// Error that we have no idea what to do with
else if (x is InsanelyBadException) return Directive.Escalate;
// Error that we can't recover from, stop the failing child
else if (x is NotSupportedException) return Directive.Stop;
// otherwise restart the failing child
else return Directive.Restart;
});
}
...
}
What’s the Point? Containment.
The whole point of supervision strategies and directives is to contain failure within the system and self-heal, so the whole system doesn’t crash. How do we do this?
We push potentially-dangerous operations from a parent to a child, whose only job is to carry out the dangerous task.
For example, let’s say we’re running a stats system during the World Cup, that keeps scores and player statistics from a bunch of games in the World Cup.
Now, being the World Cup, there could be huge demand on that API and it could get throttled, start rate-limiting, or just plain crash (no offense FIFA, I love you guys and the Cup). We’ll use the epic Germany-Ghana match as an example.
But our scorekeeper has to periodically update its data as the game progresses. Let’s assume it has to call to an external API maintained by FIFA to get the data it needs.
This network call is dangerous! If the request raises an error, it will crash the actor that started the call. So how do we protect ourselves?
We keep the stats in a parent actor, and push that nasty network call down into a child actor. That way, if the child crashes, it doesn’t affect the parent, which is holding on to all the important data. By doing this, we are localizing the failure and keeping it from spreading throughout the system.
Here’s an example of how we could structure the actor hierarchy to safely accomplish the goal:
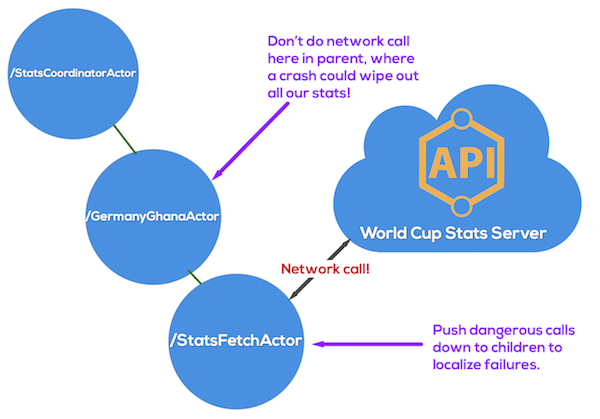
Recall that we could have many clones of this exact structure working in parallel, with one clone per game we are tracking. And we wouldn’t have to write any new code to scale it out! Beautiful.
You may also hear people use the term “error kernel,” which refers to how much of the system is affected by the failure. You may also hear “error kernel pattern,” which is just fancy shorthand for the approach I just explained where we push dangerous behavior to child actors to isolate/protect the parent.
How Long Do Child Actors Have to Wait For Their Supervisor?
This is a common question we get: What if there are a bunch of messages already in the supervisor’s mailbox waiting to be processed when a child reports an error? Won’t the crashing child actor have to wait until those are processed until it gets a response?
Actually, no. When an actor reports an error to its supervisor, it is sent as a special type of “system message.” System messages jump to the front of the supervisor’s mailbox and are processed before the supervisor returns to its normal processing.
System messages jump to the front of the supervisor’s mailbox and are processed before the supervisor returns to its normal processing.
Parents come with a default SuperviserStrategy object (or you can provide a custom one) that makes decisions on how to handle failures with their child actors.
But What Happens to the Current Message When an Actor Fails?
The current message being processed by an actor when it is halted (regardless of whether the failure happened to it or its parent) can be preserved for re-processing after restarting. There are several ways to do this. The most common approach used is during preRestart(), the actor can just send the message back to itself. This way, the message will be moved to the persistent mailbox rather than staying in the ephemeral Stash.
protected override void PreRestart(Exception reason, object message)
{
// put message back in mailbox for re-processing after restart
Self.Tell(message);
}
No More Midnight Phone Calls?
Properly written, your actor system will be self-healing and incredibly resilient, so that it survives whatever types of errors the wide world can throw at it. Then, your team can have a party like this one!

You should now have a solid understanding of how supervision and the actor hierarchy help you to build flexible but resilient systems.
Feel free to ask us any questions in the comments!
If you liked this post, you can share it with your followers or follow us on Twitter!
- Read more about:
- Akka.NET
- Case Studies
- Videos
Observe and Monitor Your Akka.NET Applications with Phobos
Did you know that Phobos can automatically instrument your Akka.NET applications with OpenTelemetry?
Click here to learn more.